Temporal-Difference Learning for Prediction
In Monte Carlo Learning, we've got the estimation of value function:
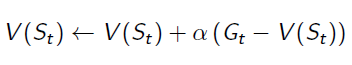
Gt is the episode return from time t, which can be calculated by:
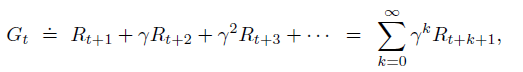
Please recall, Gt can be only calculated at the end of a given episode. This reveals a disadvantage of Monte Carlo Learning: have to wait until the end of episodes.
TD(0) algorithm replace Gt of the equation to the immediate reward and estimated value function of the next state:
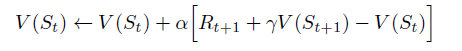
The algorithm updates the Estimated State-Value Function at time t+1, because everything in the equation is determined. This means we will wait until the agent reaching the next state, so that the agent can get the immediate reward Rt+1 and know which state the system will transition to at time t+1.
The equations below are State-Value Function for Dynamic Programming, in which the whole environment is known. Compare to these equations:
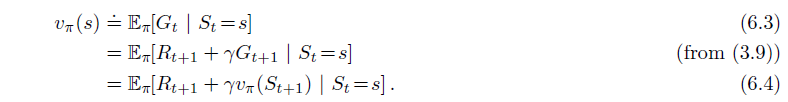
TD algorithm is quite like 6.4 Bellman Equation, but it does not take expectation. Instead, it uses the knowledge till now to estimate how much reward I am going to get from this state. The whole algorithm can be demonstrated as:

TD Target, TD Error
Bias/ Viriance trade-off
Bootstraping
Temporal-Difference Learning for Prediction的更多相关文章
- 【PPT】 Least squares temporal difference learning
最小二次方时序差分学习 原文地址: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd= ...
- PP: Multi-Horizon Time Series Forecasting with Temporal Attention Learning
Problem: multi-horizon probabilistic forecasting tasks; Propose an end-to-end framework for multi-ho ...
- [Reinforcement Learning] Model-Free Prediction
上篇文章介绍了 Model-based 的通用方法--动态规划,本文内容介绍 Model-Free 情况下 Prediction 问题,即 "Estimate the value funct ...
- [Machine Learning] 机器学习常见算法分类汇总
声明:本篇博文根据http://www.ctocio.com/hotnews/15919.html整理,原作者张萌,尊重原创. 机器学习无疑是当前数据分析领域的一个热点内容.很多人在平时的工作中都或多 ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- Machine Learning 学习笔记1 - 基本概念以及各分类
What is machine learning? 并没有广泛认可的定义来准确定义机器学习.以下定义均为译文,若以后有时间,将补充原英文...... 定义1.来自Arthur Samuel(上世纪50 ...
- Distributional Reinforcement Learning with Quantile Regression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1710.10044v1 [cs.AI] 27 Oct 2017 In AAAI Conference on Artifici ...
- 3. Distributional Reinforcement Learning with Quantile Regression
C51算法理论上用Wasserstein度量衡量两个累积分布函数间的距离证明了价值分布的可行性,但在实际算法中用KL散度对离散支持的概率进行拟合,不能作用于累积分布函数,不能保证Bellman更新收敛 ...
随机推荐
- Java 应用中的日志
frankiegao123 芋道源码 日志在应用程序中是非常非常重要的,好的日志信息能有助于我们在程序出现 BUG 时能快速进行定位,并能找出其中的原因. 但是,很多介绍 AOP 的地方都采用日志来作 ...
- Python核心技术与实战——三|字符串
一.字符串基础 Python的字符串支持单引号('').双引号("")和三引号之中('''....'''和"""...""&quo ...
- Mybatis SQL 使用JAVA 静态资源
常量:${@com.htsc.backtest.component.Global@PAGE_SIZE} 静态方法:${@com.htsc.backtest.component.Global@doMet ...
- 十、S3C2440 开发资源
10.1 S3C2440 内部资源 1.2V 内核供电, 1.8V/2.5V/3.3V 储存器供电, 3.3V 外部 I/O 供电,具备 16KB 的指令缓存和 16KB 的数据缓存和 MMU 的微处 ...
- Flutter-發送短信驗證碼
import 'dart:async'; import 'package:flutter/material.dart'; import 'package:flutter/services.dart'; ...
- 超级POM
在一个有POM的文件夹下执行: mvn help:effective-pom 会输出一个超级POM文件,可以就该文件,进行分析.
- 滑块QAbstractSlider
继承于 QWidget 抽象类-必须子类化 提供的范围内的整数值 QAbstractSlider import sys from PyQt5.QtWidgets import QApplication ...
- NOIP模拟赛(by hzwer) T2 小奇的序列
[题目背景] 小奇总是在数学课上思考奇怪的问题. [问题描述] 给定一个长度为 n 的数列,以及 m 次询问,每次给出三个数 l,r 和 P, 询问 (a[l'] + a[l'+1] + ... + ...
- 面试题常考&必考之--js中的数组去重和字符串去重
1.引入:首先得知道数组没有可以直接去重的方法,即直接[].unique()是不支持的, 会报“Uncaught TypeError: [].unique is not a function”错误, ...
- Leetcode 1. Two Sum(hash+stl)
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...