进阶4:hive 安装
安装包:
apache-hive-2.1.1-bin.tar.gz
安装步骤:
1.上传 apache-hive-2.1.1-bin.tar.gz 到linux;
2.解压文件:
tar zxvf apache-hive-2.1.1-bin.tar.gz
3.安装mysql (仅支持mysql 5.7以下版本,不支持5.7或更高版本,原因:若采用高版本mysql,部分文档内容需要改写)
sudo yum install mysql-server
4. 安装 mysql connector
sudo yum install mysql-connector-java
该命令会在/usr/share/java/下产生mysql-connector-java.jar
5. 建立链接
ln -s /usr/share/java/mysql-connector-java.jar /usr/local/hadoop-soft/etc/hive-2.1.1/lib/mysql-connector-java.jar
该命令在hive安装目录的lib目录下建立软链接,指向/usr/share/java/mysql-connector-java.jar
6. 启动mysql
sudo service mysqld start
可通过以下命令验证mysql启动成功(显示mysql进程):
ps aux | grep mysql
7. 修改mysql密码 , 修改mysql密码(改为newpass,请根据需要自行替换newpass)
mysql> use mysql;
mysql> UPDATE user SET Password = PASSWORD('newpass') WHERE user = 'root';
mysql> FLUSH PRIVILEGES;
允许用户root通过任意机器访问mysql:
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'newpass' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
8. 进入到根目录,配置环境变量:
vim ~/.bash_profile
export HIVE_HOME=/usr/local/hadoop-soft/etc/hive-2.1.1
export PATH=$HIVE_HOME/bin:$PATH
运行生效:
source ~/.bash_profile
9. 配置hive
a.进入目录:
cd /usr/local/hadoop-soft/etc/hive-2.1.1/conf
b. 新建 并 编辑 hive-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/local/hadoop-soft/etc/hive-2.1.1/warehouse</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>datanucleus.schema.autoCreateTables</name>
<value>true</value>
</property> <property>
<name>beeline.hs2.connection.user</name>
<value>master</value>
</property>
<property>
<name>beeline.hs2.connection.password</name>
<value>master</value>
</property>
</configuration>
注意 :
1. hive.metastore.uris中的“bigdata“含义为metastore server所在的机器(启动metastore的方法见下一节)
2. javax.jdo.option.ConnectionURL中的“bigdata”为mysql安装机器的hostname
3. javax.jdo.option.ConnectionUserName和javax.jdo.option.ConnectionPassword分别为mysql的访问用户和密码,可通过以下命令验证是否有效(期中bigdata为javax.jdo.option.ConnectionURL中配置的地址,xxx为mysql用户名):
mysql –h bigdata-u xxx –p
4. fs.defaultFS为HDFS的namenode启动的机器地址
5. beeline.hs2.connection.user和beeline.hs2.connection.password是beeline方式访问的用户名和密码,可任意指定,但在beeline访问时要写入你指定的这个(具体参考最后一部分)
10.如果是第一次启动hive,需要执行初始化命令
schematool -dbType mysql -initSchema
注意:仅在第一次启动hive时,运行该命令,以后则只需直接启动metastore和hiveserver
11. 启动metastore
nohup hive --service metastore >> /usr/local/hadoop-soft/etc/hive-2.1.1/metastore.log 2>&1 &
12. 启动hive server
nohup hive --service hiveserver2 >> /usr/local/hadoop-soft/etc/hive-2.1.1/hiveserver.log 2>&1 &
13. 查看hive metastore和hiveserver2是否启动成功
ps aux | grep hive
能输出两个进程,分别对应metastore和hiveserver2.

14. Hive常见两种访问方式
a.不建议使用 hive ,已经被淘汰
b. 建议使用 beeline
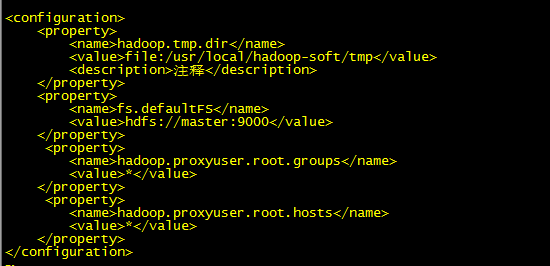
15. 修改hadoop 安装目录下 ,core-site.xml 文件
比如要用root 用户启动 hive server2和hive metastore,则增加配置:
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property> <property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
16. 之后输入以下命令发起一个连接:
!connect jdbc:hive2://master:10000/default master master
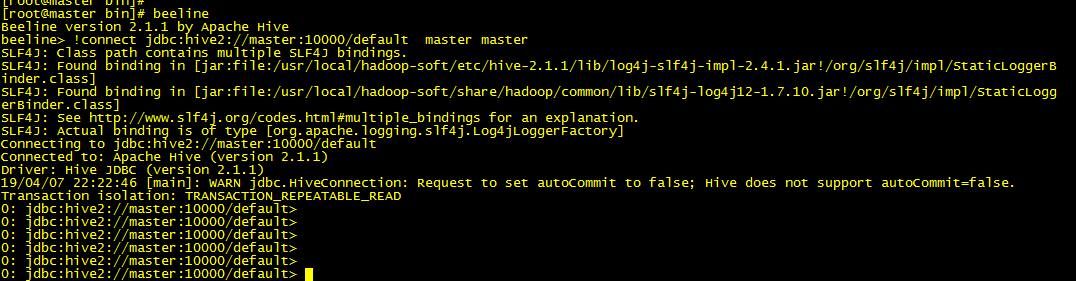
其中master 和master 分别是在hive-site.xml配置文件中由beeline.hs2.connection.user和beeline.hs2.connection.password设置的。
注:如果要使用beeline或JDBC连接hive时,遇到报错:“User: xxx is not allowed to impersonate yyy”,需在hadoop的配置文件core-site.xml中加入以下配置(其中红色标志的“xxx”是你启动hive server2和hive metastore所采用的用户,
用户名中不要包含“.”,比如“cheng.dong”是不支持的),并重启hiveserver2, hive metastore,HDFS和YARN:
进阶4:hive 安装的更多相关文章
- HIVE安装配置
Hive简介 Hive 基本介绍 Hive 实现机制 Hive 数据模型 Hive 如何转换成MapReduce Hive 与其他数据库的区别 以上详见:https://chu888chu888.gi ...
- Linux环境Hive安装配置及使用
Linux环境Hive安装配置及使用 一.Hive Hive环境前提 二.Hive架构原理解析 三.Hive-1.2.2单机安装流程 (1) 解压apache-hive-1.2.2-bin.tar.g ...
- Hive安装配置指北(含Hive Metastore详解)
个人主页: http://www.linbingdong.com 本文介绍Hive安装配置的整个过程,包括MySQL.Hive及Metastore的安装配置,并分析了Metastore三种配置方式的区 ...
- hive安装--设置mysql为远端metastore
作业任务:安装Hive,有条件的同学可考虑用mysql作为元数据库安装(有一定难度,可以获得老师极度赞赏),安装完成后做简单SQL操作测试.将安装过程和最后测试成功的界面抓图提交 . 已有的当前虚拟机 ...
- Hive安装与部署集成mysql
前提条件: 1.一台配置好hadoop环境的虚拟机.hadoop环境搭建教程:稍后补充 2.存在hadoop账户.不存在的可以新建hadoop账户安装配置hadoop. 安装教程: 一.Mysql安装 ...
- 【转】 hive安装配置及遇到的问题解决
原文来自: http://blog.csdn.net/songchunhong/article/details/51423823 1.下载Hive安装包apache-hive-1.2.1-bin.ta ...
- Hadoop之hive安装过程以及运行常见问题
Hive简介 1.数据仓库工具 2.支持一种与Sql类似的语言HiveQL 3.可以看成是从Sql到MapReduce的映射器 4.提供shall.Jdbc/odbc.Thrift.Web等接口 Hi ...
- Hive安装与配置详解
既然是详解,那么我们就不能只知道怎么安装hive了,下面从hive的基本说起,如果你了解了,那么请直接移步安装与配置 hive是什么 hive安装和配置 hive的测试 hive 这里简单说明一下,好 ...
- hive安装详解
1.安装MYSQL simon@simon-Lenovo-G400:~$ sudo apt-get install mysql-server simon@simon-Lenovo-G400:~$ su ...
随机推荐
- Mac020--常用插件
Google浏览器常用插件 1.github插件octotree 2.掘金Chrome网上应用商店 2-1.掘金/老司机的神兵利器 2-2.好用的Google插件:来自掘金 3.Gliffy Diag ...
- 简述在Vue脚手架中,组件以及父子组件(非父子组件)之间的传值
1.组件的定义 组成: template:包裹HTML模板片段(反映了数据与最终呈现给用户视图之间的映射关系) 只支持单个template标签: 支持lang配置多种模板语法: script:配置Vu ...
- Spring中单例模式中的饿汉和懒汉以及Spring中的多例模式
链接:https://pan.baidu.com/s/1wgxnXnGbPdK1YaZvhO7PDQ 提取码:opjr 单例模式:每个bean定义只生成一个对象实例,每次getBean请求获得的都是此 ...
- Hive-多分隔符
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES (&qu ...
- sql query执行的顺序
第一, from, 选择或者join多个表得到基础数据表,所以,联结是第一步要执行的操作,它在获取最基础的数据表: 第二,where,过滤掉基础数据表中不符合条件的行,得到后续操作的数据表: 第三, ...
- JavaDoc注释
标签 说明 JDK 1.1 doclet 标准doclet 标签类型 @author 作者 作者标识 √ √ 包. 类.接口 @version 版本号 版本号 √ √ 包. 类.接口 @param 参 ...
- ftok用法
转载: http://www.cnblogs.com/hjslovewcl/archive/2011/03/03/2314344.html http://www.cnblogs.com/lihaozy ...
- hdu1263 简单模拟
题意:依据水果销量表.依照特定格式输出 格式:首先按产地排序,然后同一产地按水果名排序 注意:第一,设计多级排序 第二.同一产地同一水果可能多次出现,所以须要在前面已经输入的水果里 ...
- SpringMVC_放行静态资源
静态资源到处都是坑!明白原理才能绕过这些坑! web.xml配置servlet中四种路径的区别 在web.xml文件的配置中,四种路径编写方式优先级如下图: 其中b和d都能接收所有请求,仅仅是在优先级 ...
- vue项目1-pizza点餐系统9-axios实现数据存储
一.安装.引入axios 1.终端输入cnpm install axios 2.在main.js中引入 import axios from ‘axios’ 3.配置路径 axios.defaults. ...