python笔记3----第一个小爬虫
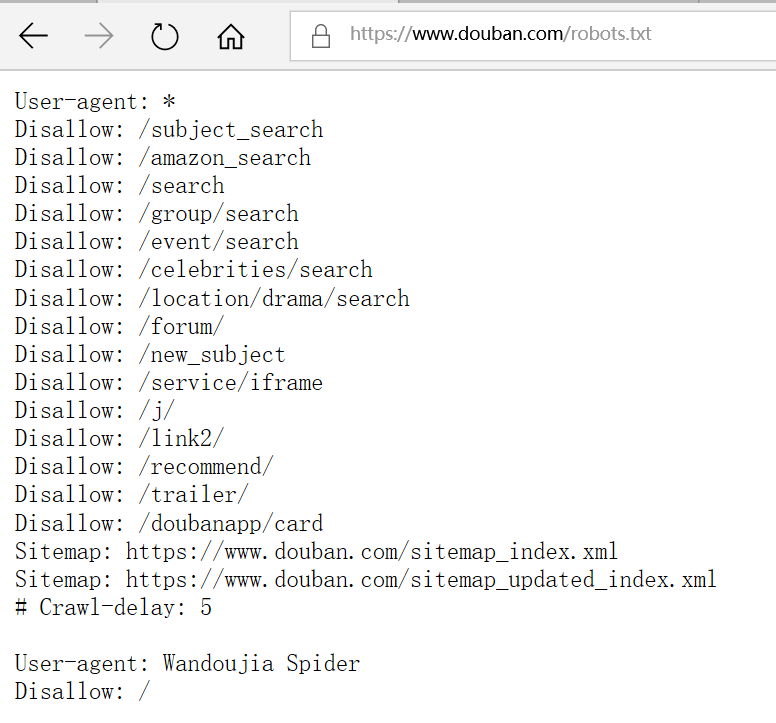
1、先看看要爬的网站有没有爬虫协议,可以看该网站有没有robots.txt,如豆瓣的:
2、requests模块:【requests是第三方,代码比python自带的urllib模块简单】
先加载requests模块,然后输入要抓取的地址:
import requests
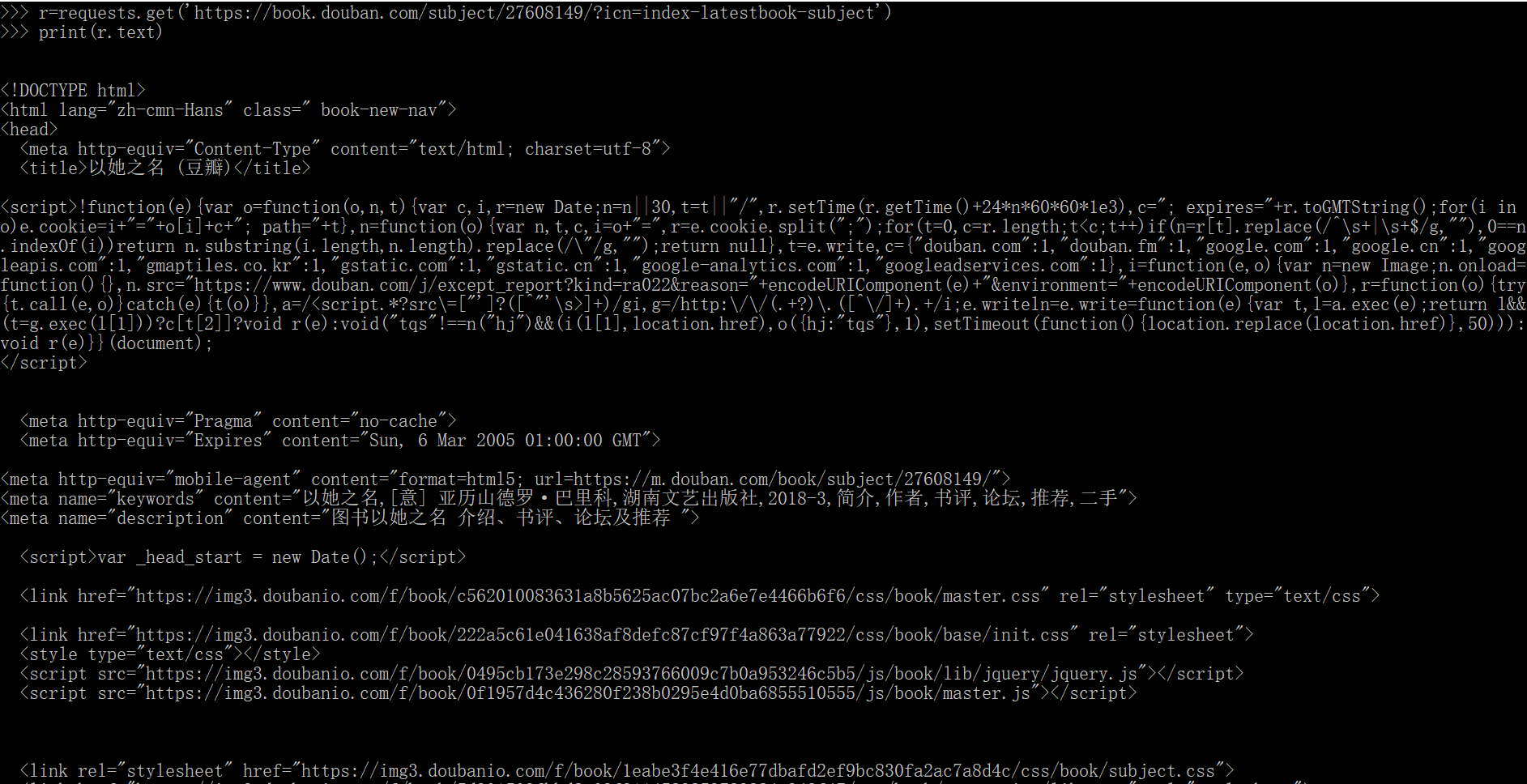
r=requests.get(‘https://book.douban.com/subject/28135034/?icn=index-latestbook-subject')
print(r.text)
结果如下:输出该网页的代码源
运用BeautifulSoup,BeautifulSoup是用来从HTML和xml中提取数据的Python库。
#导入BeautifulSoup
from bs4 import BeautifulSoup
#把要提取的源码加入汤里
soup=BeautifulSoup(r.text,'html')
#find_all函数是将<p class='comment-content’> </p>之间的字符串找出来
pattern=soup.find_all('p','comment-content')
#将每一个字符串打印出来。
for item in pattern:
print(item.string)
运用正则表达式来获取评分:
#导入正则表达式模块
import re
sum=0
#将正则表达式的字符串形式编译成pattern实例,观察源代码,评分是在以下的标签中,(.*?)是正则表达式,懒惰匹配
pattern_s=re.compile('<span class="user-stars allstars(.*?) rating"')
#使用Pattern实例处理文本并获得匹配结果
p=re.findall(pattern_s,r.text)
for i in p:
#i是字符串,需要转化成整型
sum+=int(i)
print(i)
print(sum)
3、urllib模块小程序:
目的:将以下网页的出版社爬取出来

from urllib import request
import re #读取数据
data=request.urlopen('https://read.douban.com/provider/all').read()
#中文转码,将Unicode码转成utf-8,将中文显示出来
data=data.decode('utf-8')
#观察网页,将需要爬取数据正则表达式写出来
pat='<div class="name">(.*?)</div>'
#从数据源中爬取正则表达式中的数据,注意data要转成str
res=re.compile(pat).findall(str(data))
#res为列表,所有数据集合的列表,可以打印出来
for item in res:
print(item)
写入文件中,如写入‘E://1.txt'
file=open('E://1.txt','w')
for item in res:
file.write(item,'\n')
python笔记3----第一个小爬虫的更多相关文章
- Python爬虫01——第一个小爬虫
Python小爬虫——贴吧图片的爬取 在对Python有了一定的基础学习后,进行贴吧图片抓取小程序的编写. 目标: 首先肯定要实现图片抓取这个基本功能 然后实现对用户所给的链接进行抓取 最后要有一定的 ...
- Python 学习(1) 简单的小爬虫
最近抽空学了两天的Python,基础知识都看完了,正好想申请个联通日租卡,就花了2小时写了个小爬虫,爬一下联通日租卡的申请页面,看有没有好记一点的手机号~ 人工挑眼都挑花了. 用的IDE是PyCh ...
- Python笔记_第一篇_面向过程_第一部分_8.画图工具(小海龟turtle)
turtle 是一个简单的绘图工具. 提供一个小海龟,可以把它理解为一个机器人,只能听懂有限的命令,且绘图窗口的原点(0,0)在中间,默认海龟的方向是右侧海龟的命令包括三类:运动命令.笔画控制命令.其 ...
- 从Python小白到第一个小游戏发布
1.安装必要的环境(附图两张) 直接下载安装程序,本人win10系统,根据电脑系统下载并安装对应的python.exe,安装路径可以选择D盘的,具体安装细节这里就不说了,不知道的可以留言或者找度娘 2 ...
- Python笔记_第一篇_面向过程_第一部分_5.Python数据类型之字符串类型(string)
关于Python的字符串处理也如其他语言一样属于重点中的重点,主要是牵扯到的函数和内容较为多和乱一些.关于什么是字符串,Python中的定义是:以单引号或者双引号括起来的任意文本. 1. 字符串的 ...
- Python笔记_第一篇_面向过程_第一部分_2.内存详解
Python的很多教材中并没有讲内存方面的知识,但是内存的知识非常重要,对于计算机工作原理和方便理解编程语言是非常重要的,尤其是小白,因此需要把这一方面加上,能够更加深入的理解编程语言.这里引用了C语 ...
- Python笔记_第一篇_面向过程_第一部分_0.开场白
*什么是Python? Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido(吉多) van Rossum于1989年发明,第一个公开版本发行于1991年.在国外应用非常的广泛,国 ...
- Python笔记_第一篇_面向过程第一部分_6.循环控制语句(while 和 for)_
承接条件控制语句.条件控制语句像大树一样有很多的之差,那条路径通(也就是表达式判断为True)就会往哪一个树杈去运行,万涓溪水汇成大河.对于常用的程序结构形式,还有一种这篇文章就会讲解,那就是循环控制 ...
- 使用Python写的第一个网络爬虫程序
今天尝试使用python写一个网络爬虫代码,主要是想訪问某个站点,从中选取感兴趣的信息,并将信息依照一定的格式保存早Excel中. 此代码中主要使用到了python的以下几个功能,因为对python不 ...
- python3速查参考- python基础 1 -> python版本选择+第一个小程序
题外话: Python版本:最新的3.6 安装注意点:勾选添加路径后自定义安装到硬盘的一级目录,例如本人的安装路径: F:\Python 原因:可以自动添加python环境变量,自动关联.py文件,其 ...
随机推荐
- jvm学习-垃圾回收器(四)
说明 各种垃圾回收算法都有各自的优缺点.jvm也并没有只采用一种垃圾算法.并提供几种组合供我根据场景进行选择. jvm内存结构 Person p=new Person(); 1.程序里面创建一个对象会 ...
- 命令行下配置Windows 2003防火墙
命令:netsh firewall 参数: ? // 显示命令列表 add // 添加防火墙配置 delete // 删除防火墙配置 dump // 显示一个配置脚本 help // 显示命令列表 r ...
- 0613pt-query-digest分析慢查询日志
转自http://www.jb51.net/article/107698.htm 这篇文章主要介绍了关于MySQL慢查询之pt-query-digest分析慢查询日志的相关资料,文中介绍的非常详细,对 ...
- Bi-shoe and Phi-shoe 欧拉函数 素数
Bamboo Pole-vault is a massively popular sport in Xzhiland. And Master Phi-shoe is a very popular co ...
- Linux中tty是什么(tty1~7)
tty:终端设备的统称. tty一词源于Teletypes,或者teletypewriters,原来指的是电传打字机,是通过串行线用打印机键盘通过阅读和发送信息的东西,后来这东西被键盘与显示器取代,所 ...
- [Cypress] Load Data from Test Fixtures in Cypress
When creating integration tests with Cypress, we’ll often want to stub network requests that respond ...
- QUERY_REWRITE_INTEGRITY
QUERY_REWRITE_INTEGRITY Property Description Parameter type String Syntax QUERY_REWRITE_INTEGRITY = ...
- C/C++中字符串String及字符操作方法
本文总结C/C++中字符串操作方法,还在学习中,不定期更新. .. 字符串的输入方法 1.单个单词能够直接用std::cin,由于:std::cin读取并忽略开头全部的空白字符(如空格,换行符,制表符 ...
- Android与JS互相调用以及注意
近期项目中常常使用Html5而Android与JS调用常常会用到,这里记录一下,測试系统5.0以上. 这里先贴一下源代码 Activity: package jwzhangjie.com.webvie ...
- DotNetBar.Bar菜单的使用
DotNetBar.Bar菜单的使用 老帅 在C#中使用控件DevComponents.DotNetBar.Bar时,怎样设计菜单呢? 1.拖放生成一个菜单容器 拖放一个D ...