hadoop 2.6.0 分布式 + Spark 1.1.0 集群环境
配置jdk
执行 sudo apt-get install openjdk-7-jdk
jdk被安装到了 /usr/lib/jvm/ 目录
配置hosts
使用 vim 打开 /etc/hosts, 将主节点和两个子节点的ip分别定义为 Master, Slave1, Slave2
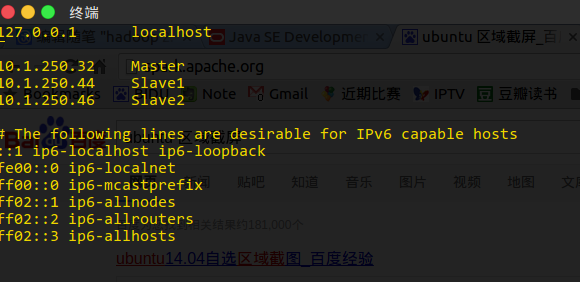
并且在 /etc/hostname中更改对应的主机名


SSH免密码登录
分别在Master, Slave1, Slave2 新建用户 stark
root@Master:~# adduser stark
在Master中, 切换到用户 stark
su stark
生成ssh秘钥
ssh-keygen -t rsa
这里当时没有截屏,若重新生成又会覆盖掉原有的密钥,所以就没有补截屏了.
进入 ~/.ssh/
cd ~/.ssh/
拷贝一份公钥到 authorized_keys
cp id_rsa.pub authorized_keys
分别在Slave1 和 Slave2 执行上述操作
利用 scp将Slave1和Slave2的公钥拷贝到主节点Master

将子节点的公钥追加到 authorized_keys

将authorized_keys拷贝到其他两台机器


测试SSH无密码连接

安装hadoop 2.6.0
从 http://mirror.hust.edu.cn/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz 下载hadoop到服务器
解压到文件夹 /home/stark/hadoop, 并将终端切换到该目录下
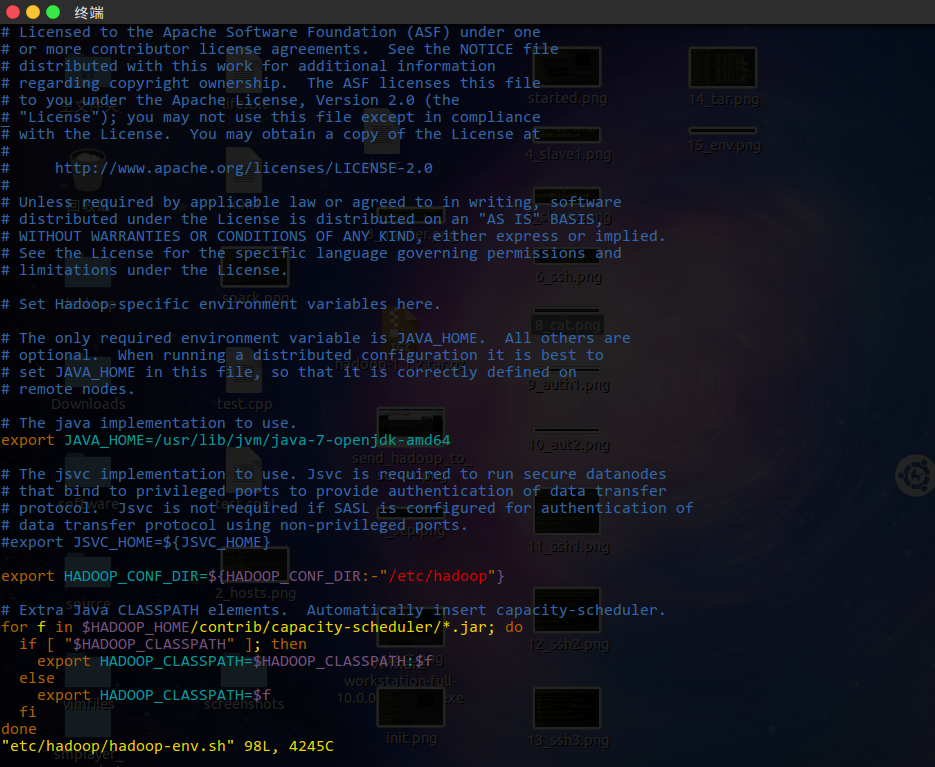
更改 etc/hadoop/hadoop-env.sh中的JAVA_HOME为实际的jdk目录

更改 etc/hadoop/core-site.xml为

更改 etc/hadoop/hdfs-site.xml为

更改 etc/hadoop/mapred-site.xml 为
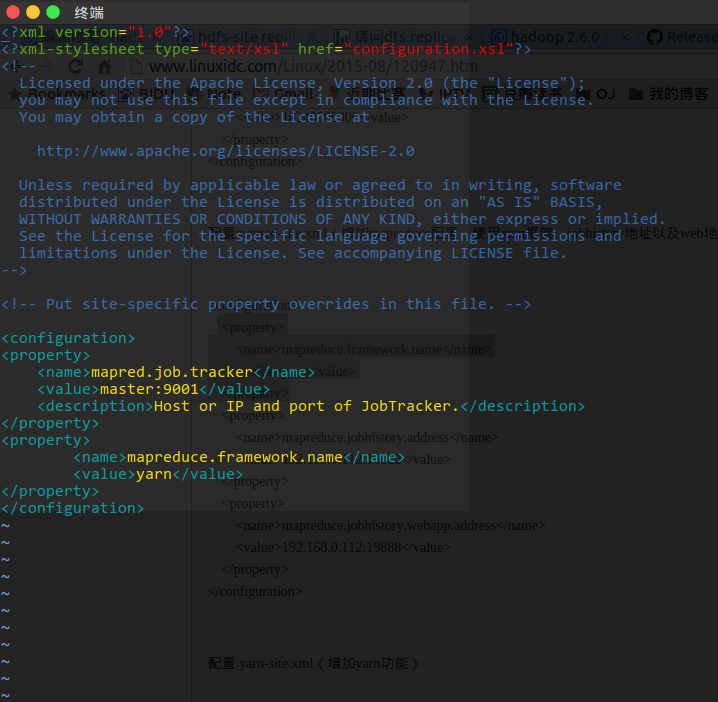
将配置好的hadoop拷贝到其他两个节点


测试 hadoop
格式化节点
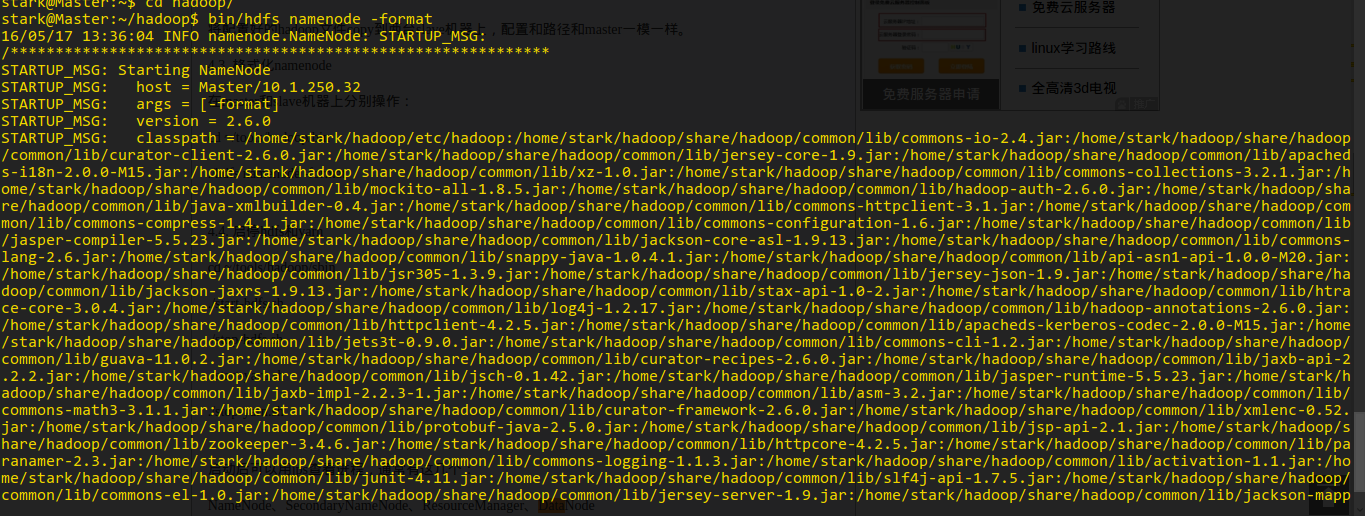
启动 hdfs 和 yarn


查看状态

运行 wordcount
在hdfs中创建目录 input
将file拷贝到input中
安装 scala
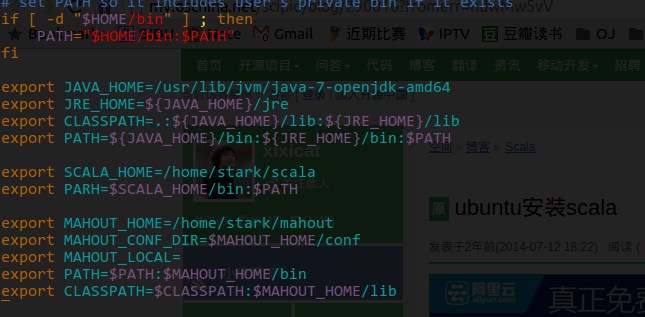

安装Spark
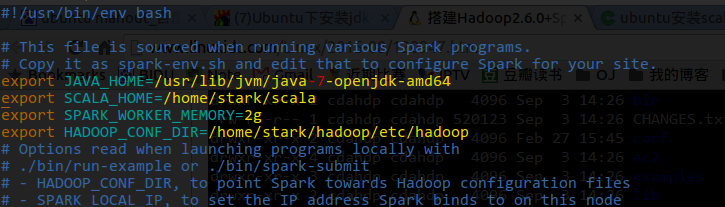
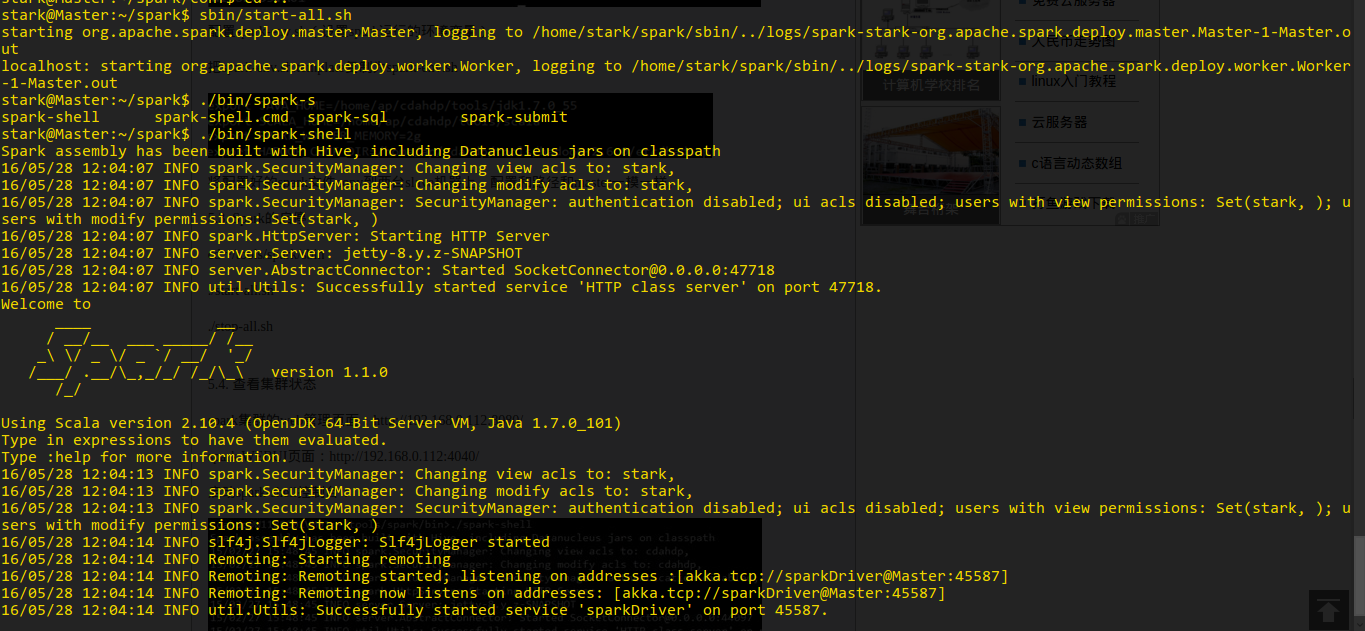
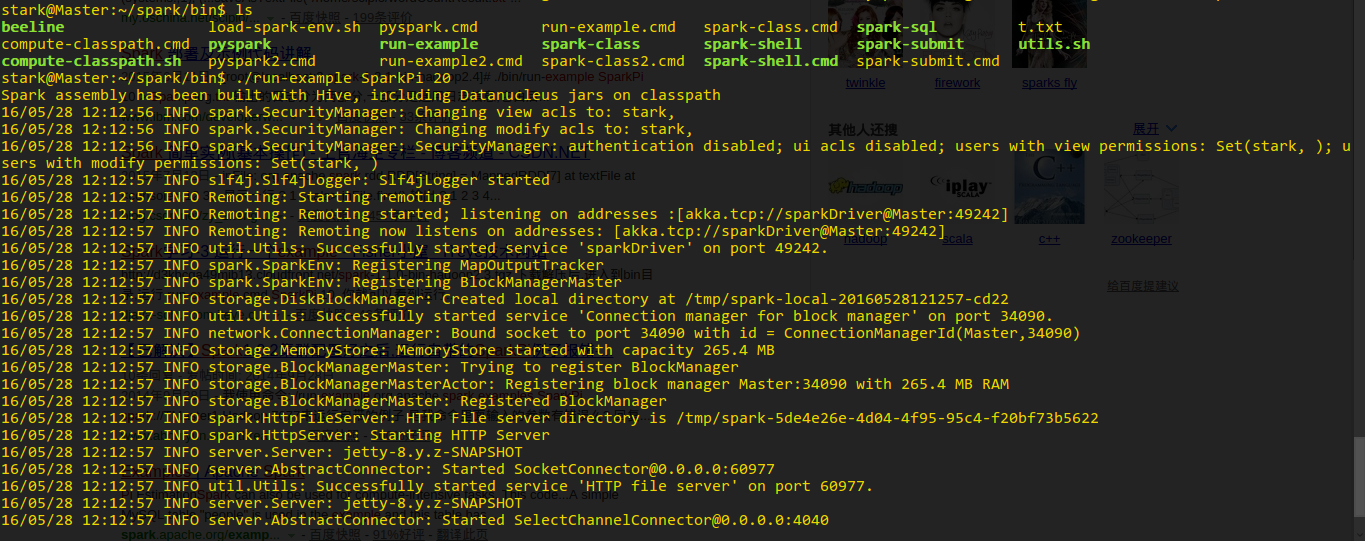

安装 mahout


hadoop 2.6.0 分布式 + Spark 1.1.0 集群环境的更多相关文章
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- 【Spark】Spark必不可少的多种集群环境搭建方法
目录 Local模式运行环境搭建 小知识 搭建步骤 一.上传压缩包并解压 二.修改Spark配置文件 三.启动验证进入Spark-shell 四.运行Spark自带的测试jar包 standAlone ...
- Hadoop集群环境安装
转载请标明出处: http://blog.csdn.net/zwto1/article/details/45647643: 本文出自:[zhang_way的博客专栏] 工具: 虚拟机virtual ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
随机推荐
- [POJ 2279] Mr. Young's Picture Permutations
[题目链接] http://poj.org/problem?id=2279 [算法] 杨氏矩阵与勾长公式 [代码] #include <algorithm> #include <bi ...
- Binary Indexed Tree 总结
特点 1. 针对 数组连续子序列累加和 问题(需要进行频繁的 update.sum 操作): 2. 并非是树型结构,只是逻辑上层次分明: 3. 可以通过 填坑法 来理解: 4. 中心思想:每一个整数都 ...
- Java入门第一季
慕课网:http://www.imooc.com/learn/85 Java入门知识第一季 1.Java开发环境和IDE的使用: 2.变量和常量 3.常用的运算符 4.流程控制语句 5.数组:使用Ar ...
- linux安装lua
1,下载lua源码wget http://www.lua.org/ftp/lua-5.3.3.tar.gz或curl -R -O http://www.lua.org/ftp/lua-5.3.3.ta ...
- 将百度百科的机器学习词条中的一段关于机器学习的demo改用Java写了一遍
这是引用的百度百科中关于机器学习的一段示例,讲述了通过环境影响来进行学习的例子. 下面是代码: import java.io.BufferedReader; import java.io.IOExce ...
- Windows 安装 MySQL8
MySQL8下载地址:https://dev.mysql.com/downloads/mysql/ 解压到安装目录 新建配置文件my.ini [mysqld]# 设置mysql的安装目录basedir ...
- node——含有异步函数的函数封装
在写代码时我们会发现有大量的重复代码,为了使代码更加简洁,我们可以将重复的代码封装为一个可以在多个部分时候用的函数. 之前写的新闻代码中,经常出现的操作有对文件的读取,我们可以将它封装为一个函数rea ...
- 注解实战aftersuite和beforesuite
package com.course.testng;import org.testng.annotations.*; public class BasicAnnotation { //最基本的注解,用 ...
- logstash配置如何理解?
elasticsearch { action => "index" #The operation on ES hosts => "localhost: ...
- Vue双向绑定原理(源码解析)---getter setter
Vue双向绑定原理 大部分都知道Vue是采用的是对象的get 和set方法来实现数据的双向绑定的过程,本章将讨论他是怎么利用他实现的. vue双向绑定其实是采用的观察者模式,get和s ...