hadoop 2.6.0 分布式 + Spark 1.1.0 集群环境
配置jdk
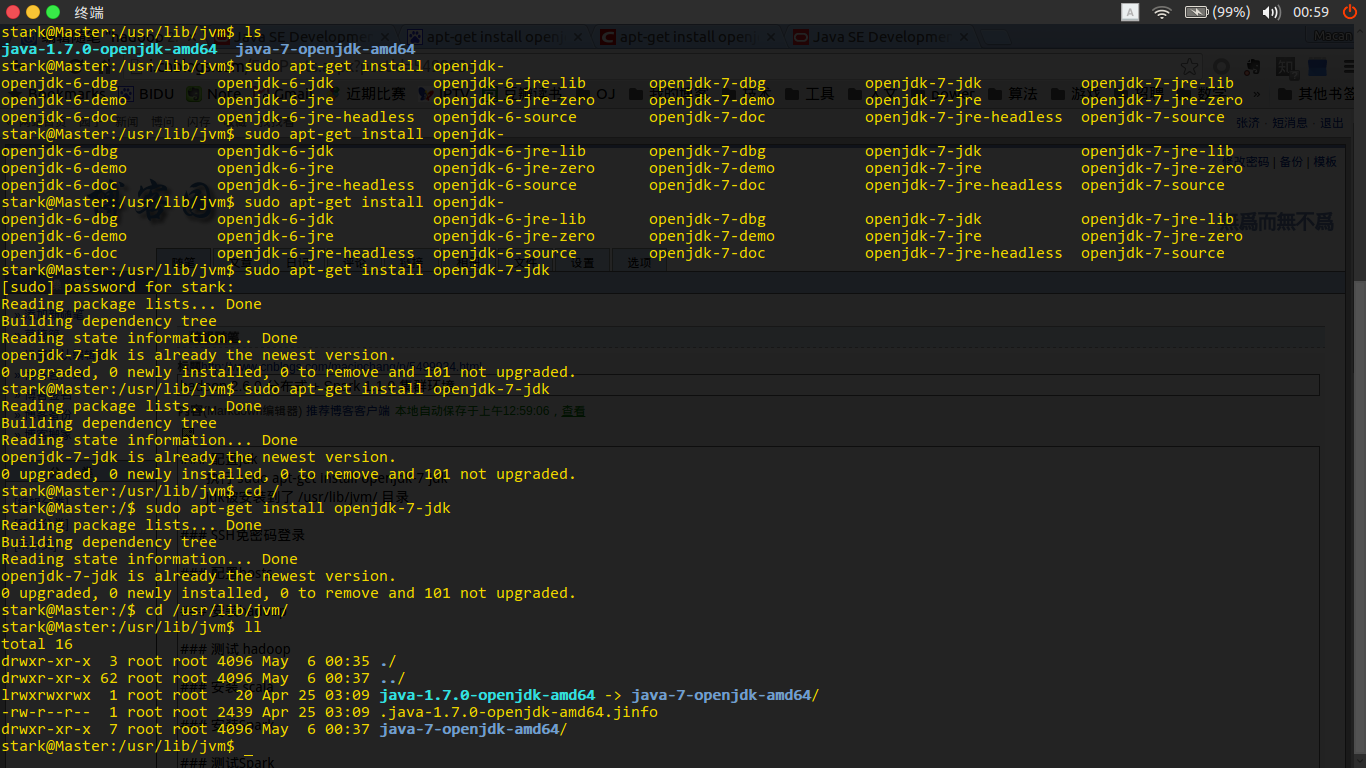
执行 sudo apt-get install openjdk-7-jdk
jdk被安装到了 /usr/lib/jvm/ 目录
配置hosts
使用 vim 打开 /etc/hosts, 将主节点和两个子节点的ip分别定义为 Master, Slave1, Slave2
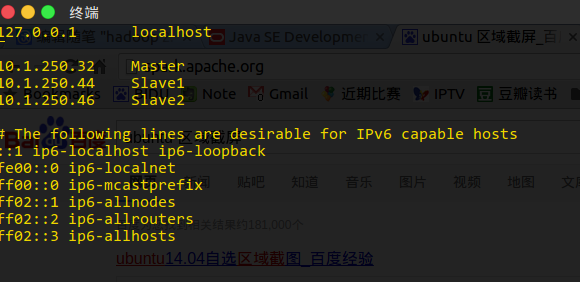
并且在 /etc/hostname中更改对应的主机名


SSH免密码登录
分别在Master, Slave1, Slave2 新建用户 stark
root@Master:~# adduser stark
在Master中, 切换到用户 stark
su stark
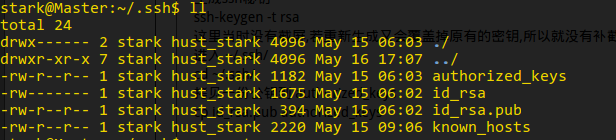
生成ssh秘钥
ssh-keygen -t rsa
这里当时没有截屏,若重新生成又会覆盖掉原有的密钥,所以就没有补截屏了.
进入 ~/.ssh/
cd ~/.ssh/
拷贝一份公钥到 authorized_keys
cp id_rsa.pub authorized_keys
分别在Slave1 和 Slave2 执行上述操作
利用 scp将Slave1和Slave2的公钥拷贝到主节点Master

将子节点的公钥追加到 authorized_keys

将authorized_keys拷贝到其他两台机器


测试SSH无密码连接

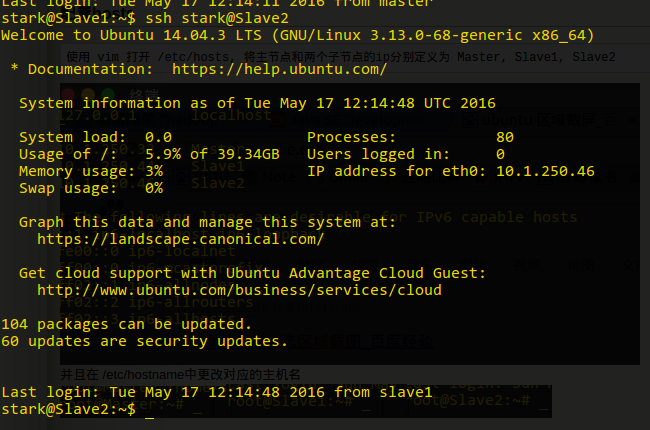
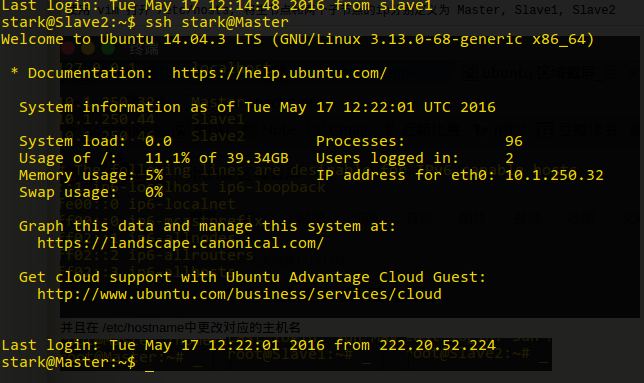
安装hadoop 2.6.0
从 http://mirror.hust.edu.cn/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz 下载hadoop到服务器
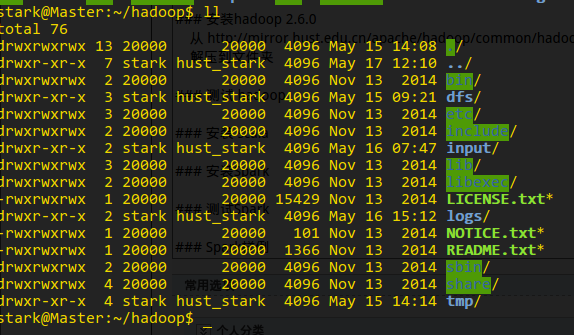
解压到文件夹 /home/stark/hadoop, 并将终端切换到该目录下
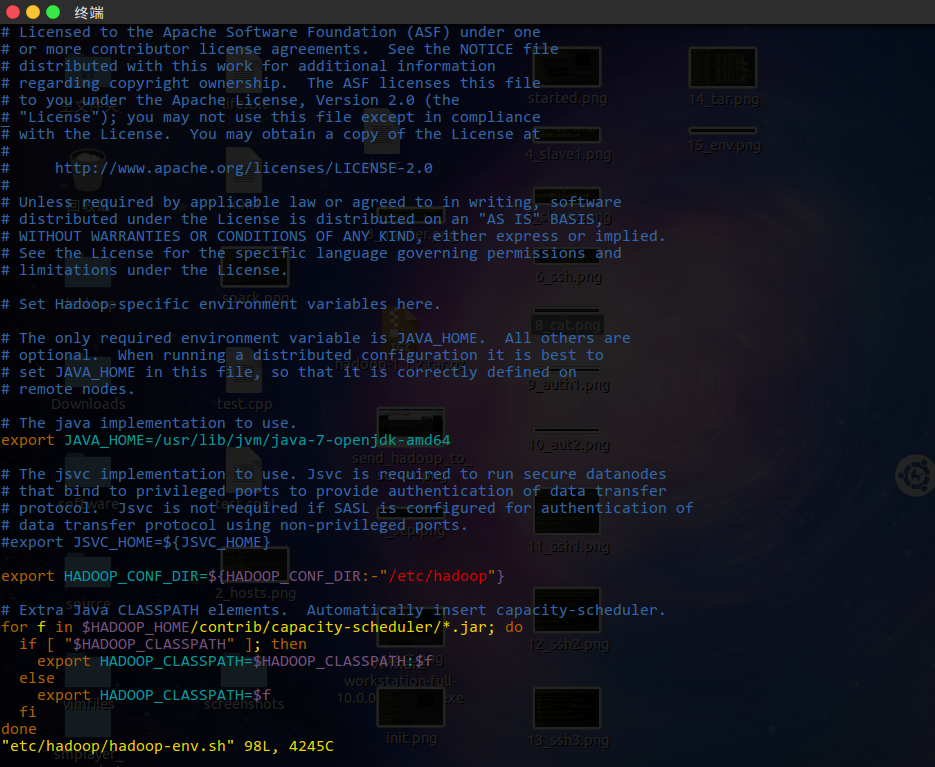
更改 etc/hadoop/hadoop-env.sh中的JAVA_HOME为实际的jdk目录

更改 etc/hadoop/core-site.xml为

更改 etc/hadoop/hdfs-site.xml为

更改 etc/hadoop/mapred-site.xml 为
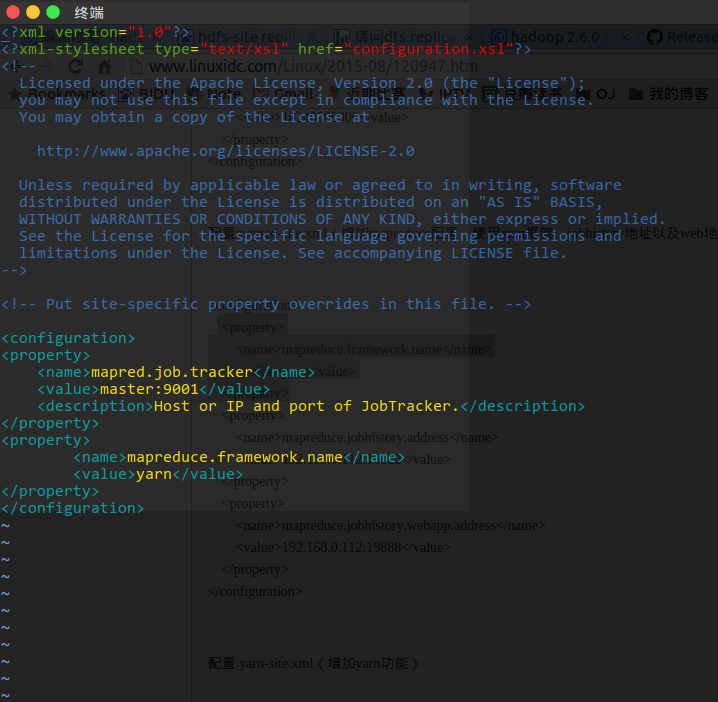
将配置好的hadoop拷贝到其他两个节点


测试 hadoop
格式化节点
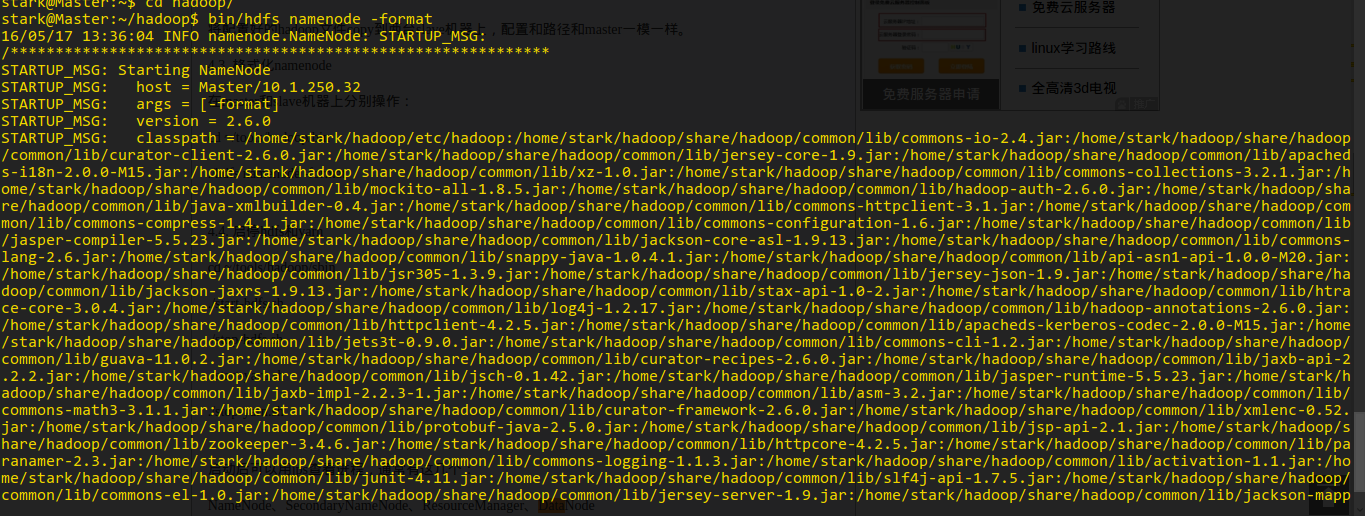
启动 hdfs 和 yarn


查看状态

运行 wordcount
在hdfs中创建目录 input
将file拷贝到input中
安装 scala

安装Spark

安装 mahout


hadoop 2.6.0 分布式 + Spark 1.1.0 集群环境的更多相关文章
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- 【Spark】Spark必不可少的多种集群环境搭建方法
目录 Local模式运行环境搭建 小知识 搭建步骤 一.上传压缩包并解压 二.修改Spark配置文件 三.启动验证进入Spark-shell 四.运行Spark自带的测试jar包 standAlone ...
- Hadoop集群环境安装
转载请标明出处: http://blog.csdn.net/zwto1/article/details/45647643: 本文出自:[zhang_way的博客专栏] 工具: 虚拟机virtual ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
随机推荐
- Huatuo's Medicine
Huatuo's Medicine Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others ...
- C# Keywords - as
记录一下在日常开发过程中遇到的一些C# 基础编程的知识! 希望以后能用的着.知识是在平常的开发过程中去学到的.只有用到了,你才能深入的理解它,并用好它. 本资料来源于:MSND 下面是一些相关的cod ...
- c++面向对象程序设计 谭浩强 第五章答案
1: #include <iostream> using namespace std; class Student {public: void get_value() {cin>&g ...
- 如何让MP4 video视频背景色变成透明?
本文转自:https://www.zhangxinxu.com/wordpress/2019/05/mp4-video-background-transparent/ 亲测,pc端有效,但移动端微信内 ...
- sql server 授权相关命令
原文:https://blog.csdn.net/hfdgjhv/article/details/83834076 https://www.cnblogs.com/shi-yongcui/p/7755 ...
- 初学C#,总结一下.sln和.csproj的区别
1.sln:solusion 解决方案 csproj:c sharp project C#项目 csproj文件大家应该不会陌生,那就是C#项目文件的扩展名,它是“C Sharp Project”的缩 ...
- 02操控奴隶——掌握它的语言“Python”
一 编程常识 1编程语言的发展史 程序员是计算机的主人,主人与奴隶沟通的介质是编程语言,编程语言从诞生到现在它经历了那几个阶段呢? 2 语言的特性: 3 初期的编程语言更多的是站在计算机的角度去设计编 ...
- Sona && Little Elephant and Array && Little Elephant and Array && D-query && Powerful array && Fast Queries (莫队)
vjudge上莫队专题 真的是要吐槽自己(自己的莫队手残写了2个bug) s=sqrt(n) 是元素的个数而不是询问的个数(之所以是sqrt(n)使得左端点每个块左端点的范围嘴都是sqrt(n)) 在 ...
- Codeforces Round #506 (Div. 3) D-F
Codeforces Round #506 (Div. 3) (中等难度) 自己的做题速度大概只尝试了D题,不过TLE D. Concatenated Multiples 题意 数组a[],长度n,给 ...
- C IO programming test code
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl ...