跟我一起hadoop(1)-hadoop2.6安装与使用
伪分布式
hadoop的三种安装方式:
安装之前需要
$ sudo apt-get install ssh
$ sudo apt-get install rsync
详见:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
伪分布式配置
Configuration
修改下边:
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置ssh
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
如果想运行在yarn上
需要执行下边的步骤:
- Configure parameters as follows:
etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> - Start ResourceManager daemon and NodeManager daemon:
$ sbin/start-yarn.sh
- Browse the web interface for the ResourceManager; by default it is available at:
- ResourceManager - http://localhost:8088/
- Run a MapReduce job.
- When you're done, stop the daemons with:
$ sbin/stop-yarn.sh
输入:
可以看到
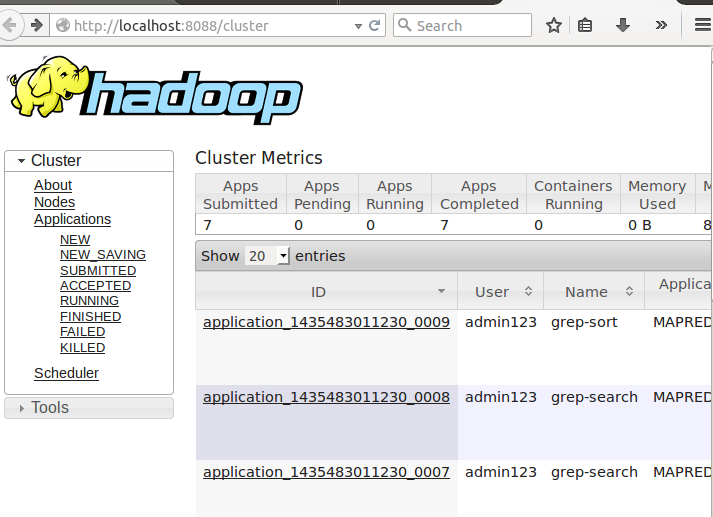
启动yarn后
- Format the filesystem:
$ bin/hdfs namenode -format
- Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
- Browse the web interface for the NameNode; by default it is available at:
- NameNode - http://localhost:50070/
输入后得到:
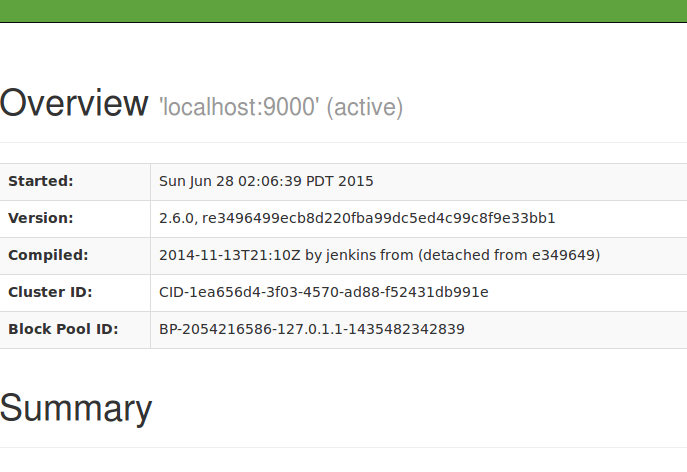
然后执行测试
- Make the HDFS directories required to execute MapReduce jobs:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username> - Copy the input files into the distributed filesystem:
$ bin/hdfs dfs -put etc/hadoop input
- Run some of the examples provided:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
- Examine the output files:
Copy the output files from the distributed filesystem to the local filesystem and examine them:
$ bin/hdfs dfs -get output output
$ cat output/*or
View the output files on the distributed filesystem:
$ bin/hdfs dfs -cat output/*
看运行的情况:
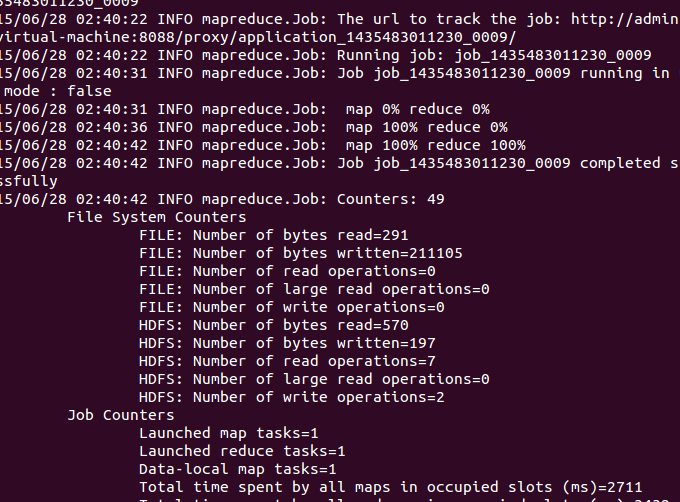
查看结果
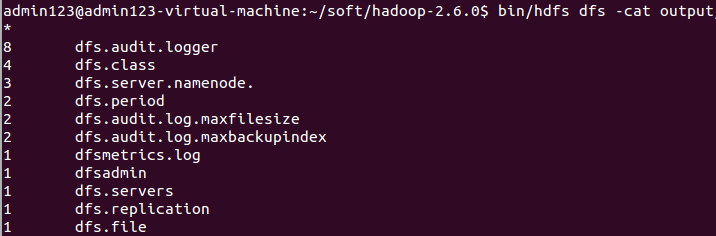
测试执行成功,可以编写本地代码了。
eclipse hadoop2.6插件使用
下载源码:
git clone https://github.com/winghc/hadoop2x-eclipse-plugin.git
下载过程:
编译插件:
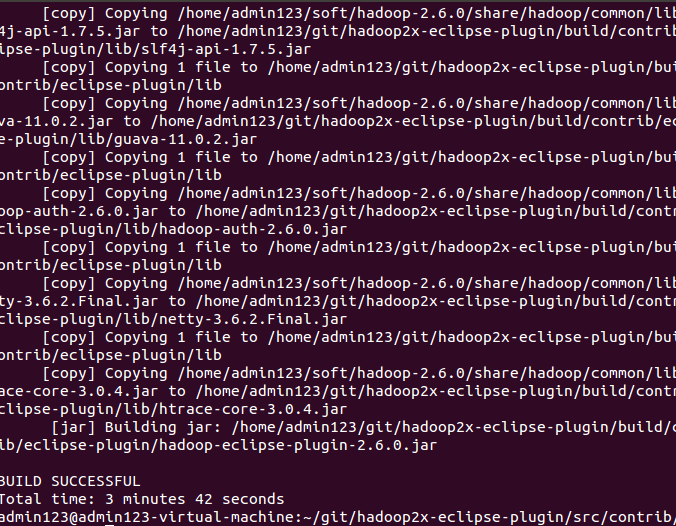
cd src/contrib/eclipse-plugin
ant jar -Dversion=2.6.0 -Declipse.home=/usr/local/eclipse -Dhadoop.home=/usr/local/hadoop-2.6.0 //路径根据自己的配置
- 复制编译好的jar到eclipse插件目录,重启eclipse
- 配置 hadoop 安装目录
window ->preference -> hadoop Map/Reduce -> Hadoop installation directory
- 配置Map/Reduce 视图
window ->Open Perspective -> other->Map/Reduce -> 点击“OK”
windows → show view → other->Map/Reduce Locations-> 点击“OK”
- 控制台会多出一个“Map/Reduce Locations”的Tab页
在“Map/Reduce Locations” Tab页 点击图标<大象+>或者在空白的地方右键,选择“New Hadoop location…”,弹出对话框“New hadoop location…”,配置如下内容:将ha1改为自己的hadoop用户
注意:MR Master和DFS Master配置必须和mapred-site.xml和core-site.xml等配置文件一致。
打开Project Explorer,查看HDFS文件系统。
- 新建Map/Reduce任务
File->New->project->Map/Reduce Project->Next
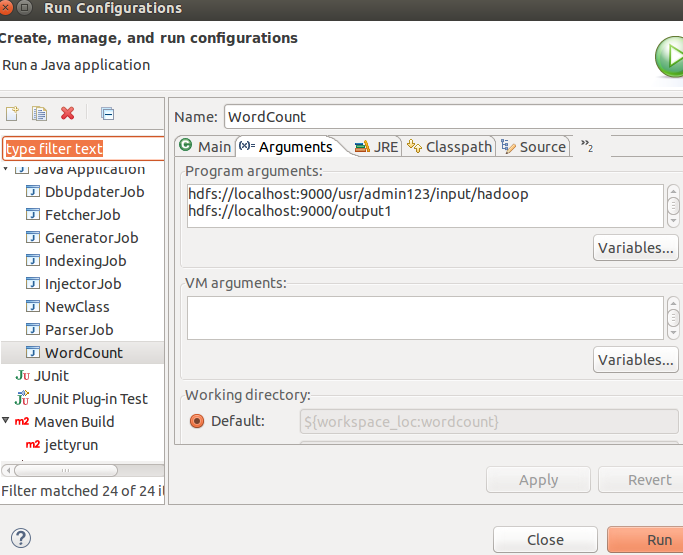
编写WordCount类:记得先把服务都起来
/**
*
*/
package com.zongtui; /**
* ClassName: WordCount <br/>
* Function: TODO ADD FUNCTION. <br/>
* date: Jun 28, 2015 5:34:18 AM <br/>
*
* @author zhangfeng
* @version
* @since JDK 1.7
*/ import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer; import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat; public class WordCount {
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
} public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
} public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf);
}
}user/admin123/input/hadoop是你上传在hdfs的文件夹(自己创建),里面放要处理的文件。ouput1放输出结果
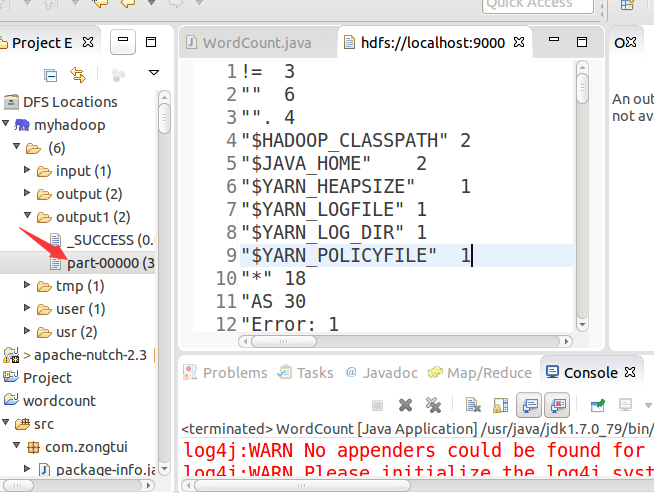
将程序放在hadoop集群上运行:右键-->Runas -->Run on Hadoop,最终的输出结果会在HDFS相应的文件夹下显示。至此,ubuntu下hadoop-2.6.0 eclipse插件配置完成。
遇到异常
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/output already exists
at org.apache.hadoop.mapred.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:132)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:564)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:432)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:833)
at com.zongtui.WordCount.main(WordCount.java:83)


1、改变输出路径。
2、删除重新建。
运行完成后看结果:
跟我一起hadoop(1)-hadoop2.6安装与使用的更多相关文章
- hadoop入门-centos7.2安装hadoop2.8
1. 安装准备 (1)必须安装jdk: 因为hadoop是基于Java实现的,所有必须安装jdk 是JDK不是jre jdk1.7 jdk1.8 (2)系统位数 (3)创建专用用户 useradd h ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- 【原】Hadoop伪分布模式的安装
Hadoop伪分布模式的安装 [环境参数] (1)Host OS:Win7 64bit (2)IDE:Eclipse Version: Luna Service Release 2 (4.4.2) ( ...
- 完全分布式Hadoop2.3安装与配置
一.Hadoop基本介绍 Hadoop优点 1.高可靠性:Hadoop按位存储和处理数据 2.高扩展性:Hadoop是在计算机集群中完成计算任务,这个集群可以方便的扩展到几千台 3.高效性:Hadoo ...
- Hadoop集群环境安装
转载请标明出处: http://blog.csdn.net/zwto1/article/details/45647643: 本文出自:[zhang_way的博客专栏] 工具: 虚拟机virtual ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
- Hadoop分布式HA的安装部署
Hadoop分布式HA的安装部署 前言 单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个n ...
- hadoop完全分布式的安装
下载地址: centos 7.5 下载地址 清华 http://mirrors.tuna.tsinghua.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-DV ...
- [转] Hadoop 2.0 详细安装过程
1. 准备 创建用户 useradd hadoop passwd hadoop 创建相关的目录 定义代码及工具存放的路径 mkdir -p /home/hadoop/source mkdir -p / ...
随机推荐
- 超大 Cookie 拒绝服务攻击
有没有想过,如果网站的 Cookie 特别多特别大,会发生什么情况? 不多说,马上来试验一下: for (i = 0; i < 20; i++) document.cookie = i + '= ...
- 通过Jexus 部署 dotnetcore版本MusicStore 示例程序
ASPNET Music Store application 是一个展示最新的.NET 平台(包括.NET Core/Mono等)上使用MVC 和Entity Framework的示例程序,本文将展示 ...
- 水印第三版 ~ 变态水印(这次用Magick.NET来实现,附需求分析和源码)
技能 汇总:http://www.cnblogs.com/dunitian/p/4822808.html#skill 以前的水印,只是简单走起,用的是原生态的方法.现在各种变态水印,于是就不再用原生态 ...
- 微软Azure 经典模式下创建内部负载均衡(ILB)
微软Azure 经典模式下创建内部负载均衡(ILB) 使用之前一定要注意自己的Azure的模式,老版的为cloud service模式,新版为ARM模式(资源组模式) 本文适用于cloud servi ...
- [C#] string 与 String,大 S 与小 S 之间没有什么不可言说的秘密
string 与 String,大 S 与小 S 之间没有什么不可言说的秘密 目录 小写 string 与大写 String 声明与初始化 string string 的不可变性 正则 string ...
- 简记某WebGIS项目的优化之路
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 该项目为研究生时的老师牵头,个人已毕业数年,应老师要求协助其 ...
- C++ 事件驱动型银行排队模拟
最近重拾之前半途而废的C++,恰好看到了<C++ 实现银行排队服务模拟>,但是没有实验楼的会员,看不到具体的实现,正好用来作为练习. 模拟的是银行的排队叫号系统,所有顾客以先来后到的顺序在 ...
- JAVA构造时成员初始化的陷阱
让我们先来看两个类:Base和Derived类.注意其中的whenAmISet成员变量,和方法preProcess(). 情景1:(子类无构造方法) class Base { Base() { pre ...
- ESLint的使用笔记
原文地址:https://csspod.com/getting-started-with-eslint/?utm_source=tuicool&utm_medium=referral 在团队协 ...
- CYQ.Data V5 从入门到放弃ORM系列:教程 - AppConfig、AppDebug类的使用
1:AppConfig类的介绍: Public Static (Shared) Properties IsEnumToInt 是否使用表字段枚举转Int方式(默认为false). 设置为true时,可 ...