尚未成功启动solr的,请参考我的另一篇文章:http://www.cnblogs.com/zhuwenjoyce/p/6506359.html(solr6.4.1 搜索引擎启动eclipse启动)
注意,这里的两个输入框*Dir如果不指定目录,那么默认这个core3目录将应该在solrhome根目录下,instanceDir和dataDir必须是两个已存在的目录
我这里的core3目录是D:\solr\solrhome\core3(这个core3目录也要先建立出来)
先不要点击按钮Add Core,因为会报错:
Error CREATEing SolrCore 'core1': Unable to create core [core1] Caused by: Can't find resource 'solrconfig.xml' in classpath or 'D:\solr\core1'
为了避免这个错误,我们首先需要为这个core3做一些准备工作,包括要把Add Core中的solrconfig.xml和schema.xml文件都创建出来。主要分为以下几步:
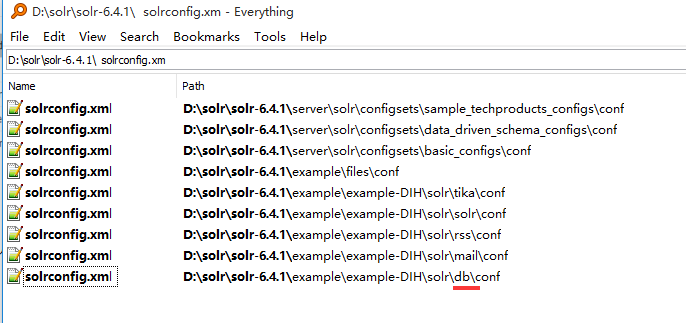
因为是同步数据库,所以找的是db目录下的solrconfig.xml, D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\solrconfig.xml
(上图工具使用的是一个windows搜索器:Everything.exe)
复制D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\solrconfig.xml黏贴到D:\solr\solrhome\core3目录下。
修改D:\solr\solrhome\core3\solrconfig.xml,把<lib dir= 标签这7个节点里的${solr.install.dir:../../../..}替换为本地solr根目录D:/solr/solr-6.4.1
因为在D:\solr\solrhome\core3\solrconfig.xml中,提到使用db-data-config.xml来导入数据
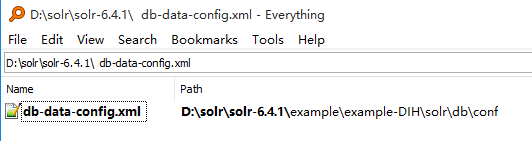
所以同理,复制db目录下的db-data-config.xml到D:\solr\solrhome\core3\目录下
重点1:db-data-config.xml中,url地址中的&符号必须替换为&否则会报错:
Data Config problem: 对实体 "useUnicode" 的引用必须以 ';' 分隔符结尾。
以下是我本地的db-data-config.xml文件
重点2:所有field标签的name值都必须存在于schema.xml中!(参考第三步:创建schema.xml)
复制D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\managed-schema黏贴为D:\solr\solrhome\core3\schema.xml,这个schema.xml就是Add Core界面的schema文件。
重点1:schema.xml文件定义了所有我们需要在数据库中同步过来的字段,其中db-data-config.xml中导入的字段必须要存在于该schema.xml中所以schema.xml文件决定了在整个solr应用中,所有的字段必须不能重复!建议在solr中对字段命名时采用表名_字段名方式。
重点2:schema.xml文件中所有的<field标签中required="true"属性标志着你所有在solr中的查询都必须有一个字段是这些字段,而且必须有值,否则报错:SolrException missing required field: id
重点3:当点击Add Core按钮之后,原先的D:\solr\solrhome\core3\schema.xml文件将被删除,随之增加D:\solr\solrhome\core3\conf\managed-schema(注意,没有后缀名)
以下是我本地的managed-schema文件
第四步:复制stopwords_*.txt文件到D:\solr\core1\lang\目录下
所有的D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\stopwords_*.txt文件
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\stopwords_el.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\stopwords_en.txt
it;id;hy;lv;hu;pt;tr;de;hi;da;cz;th;sv; 等等txt文件,总共有31个
第五步:复制以下文件到D:\solr\core1\lang\目录下
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\contractions_it.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\contractions_ca.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\contractions_ga.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\contractions_fr.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\hyphenations_ga.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\stemdict_nl.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\lang\stoptags_ja.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\elevate.xml
第六步:复制以下文件到D:\solr\core1\目录下
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\protwords.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\synonyms.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\stopwords.txt
D:\solr\solr-6.4.1\example\example-DIH\solr\db\conf\currency.xml
第七步:重启tomcat,访问solr,增加core
增加一个core就相当于增加了一个数据库,solr本就支持数据库集群,支持以json格式存储数据
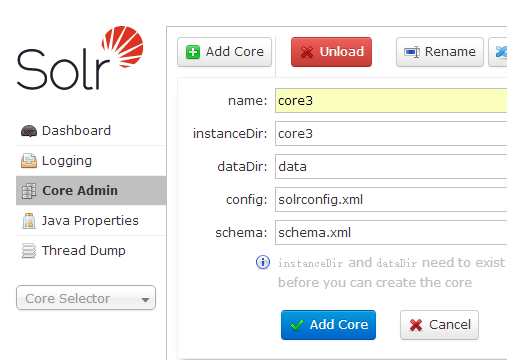
点击Core Admin菜单,输入core信息,点击Add Core按钮:
ps: 如果启动过程中有遇到*.lock文件而报错,那么删除该lock文件重新建立一遍既可成功。
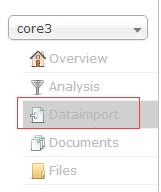
下拉框选择刚刚建立的core3,选中Dataimport菜单
先检查core3加载的db-data-config.xml文件是否有效,点击Reload按钮校验,当出现信息No information available时则表示校验通过。
初次导入选择full-import全量导入模式,点击Execute按钮执行数据导入,页面右边显示Indexing since则表示正在导入中,在导入过程中,点击Refresh Status则会显示详细的导入信息(Requests,Fetched,Skipped),如下图右图所示:
选择core3,点击菜单Query,什么查询条件都不要加,点击Execute Query按钮
查询出solr同步数据如下,表示同步mysql数据成功:
上图中,http地址表示此次查询可以使用这样的get请求方式,其中status 0 表示查询成功,params表示此次查询使用的查询参数。这里显示的全都是默认值。response里的数据代表查询到的数据,可以看到已经查询成功。
- solr6.4.1搜索引擎(3)增量同步mysql数据库
尚未实现首次同步mysql数据库的,请参考我的另一篇文章http://www.cnblogs.com/zhuwenjoyce/p/6512378.html(solr6.4.1搜索引擎同步mysql数据 ...
- solr6.4.1搜索引擎(2)首次同步mysql数据库
尚未成功启动solr的,请参考我的另一篇文章:http://www.cnblogs.com/zhuwenjoyce/p/6506359.html(solr6.4.1 搜索引擎启动eclipse启动) ...
- Logstash同步mysql数据库信息到ES
@font-face{ font-family:"Times New Roman"; } @font-face{ font-family:"宋体"; } @fo ...
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
- 使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch
本文介绍如何使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch. 1.go-mysql-elasticsearch简介 go-mysql-elasti ...
- 使用logstash同步mysql数据库信息到ElasticSearch
本文介绍如何使用logstash同步mysql数据库信息到ElasticSearch. 1.准备工作 1.1 安装JDK 网上文章比较多,可以参考:https://www.dalaoyang.cn/a ...
- Elasticsearch学习(2) windows环境下Elasticsearch同步mysql数据库
在上一章中,我们已经能够通过spring boot来使用Elasticsearch,但是由于我们习惯性的将数据写入mysql,所以为了解决这个问题,Elasticsearch为我们提供了一个插件log ...
- 如何通过 Docker 部署 Logstash 同步 Mysql 数据库数据到 ElasticSearch
在开发过程中,我们经常会遇到对业务数据进行模糊搜索的需求,例如电商网站对于商品的搜索,以及内容网站对于内容的关键字检索等等.对于这些高级的搜索功能,显然数据库的 Like 是不合适的,通常我们采用 E ...
- django无法同步mysql数据库 Error:1064
[问题] 具体问题:新建django工程,使用django的manage.py的 migrate命令进行更改. 在初始化数据库表时,失败,错误信息为 django.db.migrations.exce ...
- html标签默认样式整理
引:http://www.jb51.net/web/94964.html 文为大家整理了html标签默认样式属性及浏览器默认样式等等,喜欢css布局的朋友们可以学下,希望对大家有所帮助 html, a ...
- HttpSesstionActivationLIstener示例
HttpSesstionActivationLIstener示例: http://www.cnblogs.com/xdp-gacl/p/3969249.html 钝化的session会已session ...
- pureMVC简单示例及其原理讲解四(Controller层)
本节将讲述pureMVC示例中的Controller层. Controller层有以下文件组成: AddUserCommand.as DeleteUserCommand.as ModelPrepCom ...
- C++实现具有基本功能的智能指针
C++中的智能指针实际上是代理模式与RAII的结合. 自定义unique_ptr,主要是release()和reset().代码如下. #include <iostream> using ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Linux笔记(十四) - 日志管理
(1)rsyslogd的服务:查看服务是否启动:ps aux | grep rsyslogd 查看服务是否自启动:chkconfig --list | grep rsyslog 配置文件 : /etc ...
- 汇编实现HelloWorl!
hello word~ ASSUME CS:CODE,DS:DATA DATA SEGMENT DB "HELLO WORLD" ;存储要显示的数据 DATA ENDS CODE ...
- 【ci框架基础】之部署百度编辑器
在ci框架下加载编辑器,现在复习下内容.我的框架文件名称为ci 1.下载百度编辑器ueditor,http://ueditor.baidu.com/ 一般情况下下载ubuilder版即可,并将uedi ...
- netty 对 protobuf 协议的解码与包装探究(2)
netty 默认支持protobuf 的封装与解码,如果通信双方都使用netty则没有什么障碍,但如果客户端是其它语言(C#)则需要自己仿写与netty一致的方式(解码+封装),提前是必须很了解net ...
- iOS核心笔记—MapKit框架-基础
1.MapKit框架简介: ✨了解:MapKit框架使用须知:①.MapKit框架中所有的数据类型的前缀都是MK:②.需要导入#import <MapKit/MapKit.h>头文件:③. ...