kafka汇总
Kafka
1. kafka概念
kafka是一个高吞吐亮的、分布式、基于发布/订阅(也就是一对多)的消息系统,最初由Linkedln公司开发的,使用Scala语言编写的,目前是Apache的开源项目。
消息队列:
1> 原理
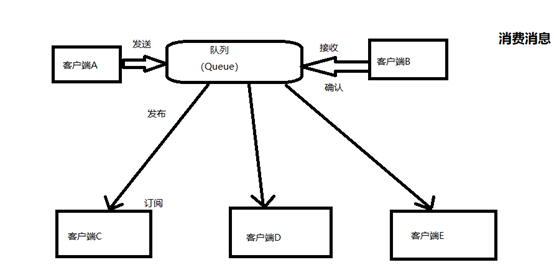
客户端消费Queue的数据优良种方式:
- 发布/订阅模式:也就是一对多,数据产生后,推给所有的订阅者。
- 点点对点模式:也就是一对一,这个是主动模式,第一种模式更像是被动模式,这个就是消费者主动拉取生产后的数据。
2> 消息队列的优点:
- 解耦2.冗余3.扩展性4.灵活性和峰值处理能力5.可恢复性6.顺序保证(kafka保证一个partition内的数据是有序的)7.缓冲8.异步通信
kafka的基本术语
topic:消息类别,kafka按照topic来分类消息。可以理解成一个队列,一个topic里有多个partition。
broker:kafka服务器,负责消息的存储与转发。一台kafka服务器就是一个broker,一个集群有多个broker,一个broker可以有多个topic。
partition:topic的一个分区,一个topic可以包含多个partition,topic消息保存在各个partition上。
offset:消息在日志中的位置,可以理解是消息在partition上的偏移量,也是代表消息的唯一序号。
producer:消息生产者。向kafka broker发消息的客户端。
consumer:消息消费者。向kafka broker 取消息的客户端。
Consumer group:消费者分组,每个consumer必须属于一个group。Consumer group是kafka用来实现原子广播和单播的手段。topic的消息会复制(不是真正的复制)到所有的consumer group,但是每个partition只会把消息发给该consumer group中的一个consumer。
eg:广播实现的方法是:只要每个consumer有一个独立的consumer group就行了。单播的实现方法就是:只要所有的consumer在同一个consumer group中就可以了。
Zookeeper:保存着集群broker、topic、partition等meta数据;另外,还负责broker 故 障发现,partition leader选举,负载均衡等功能
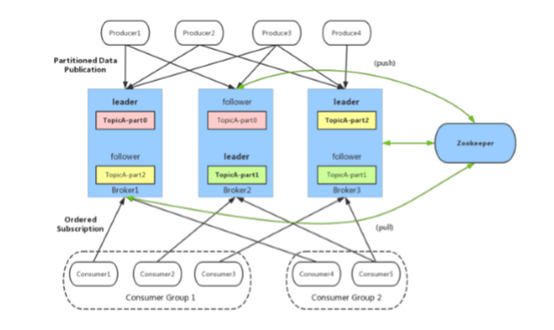
kafka数据存储设计:
1. partition的数据文件(offset、messageSize、data)
partition中的每条Message包含了以下三个属性:offset,MessageSize、data,其中offset表示Message在这个partition中的偏移量,offset不是该patition数据文件中的实际存储位置,而是逻辑上的一个值,它唯一确定了partition中的一条Message,可以认为offset是partition中Message的id;MessageSize表示消息内容data的大小;data为message的及具体内容。
2. 数据文件分段segment(顺序读写、分段命令、二分查找)
partition物理上由多个segment文件组成,每个segment大小相等,顺序读写。每个segment 数据文件以该段中小的offset命名,文件扩展名为.log。这样在查找指定offset的Message的 时候,用二分查找就可以定位到该Message在哪个segment数据文件中。
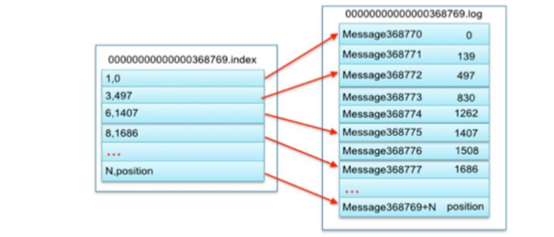
3. 数据文件索引(分段索引、稀疏存储)
Kafka 为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩 展名为.index。index 文件中并没有为数据文件中的每条 Message 建立索引,而是采用了稀疏存 储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以 将索引文件保留在内存中
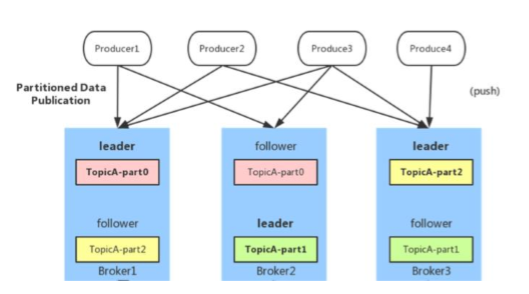
生产者设计
负载均衡
由于topic是由多个partition组成的,且 partition 会均衡分布到不同 broker 上,因此,为了有 效利用broker集群的性能,提高消息的吞吐量,producer可以通过随机或者hash等方式,将消息平均发送到多个partition上,以实现负载均衡。
批量发送
是提高消息吞吐量的重要方式,Producer端可以在内存中合并多条消息后,以一次请求的方式发送了这批量的消息给broker,从而大大减少broker的存储消息IO操作次数。但也一定程度上影响了消息的实时性,相当于以延时为代价,换取更好的吞吐量。
压缩(GZIP或Snappy)
Producer端可以通过GZIP或Snappy格式对消息集合进行压缩。Producer端进行压缩之后,在 Consumer 端需进行解压。压缩的好处就是减少传输的数据量,减轻对网络传输的压力,在对大 数据处理上,瓶颈往往体现在网络上而不是CPU(压缩和解压会耗掉部分CPU资源)。
消费者设计
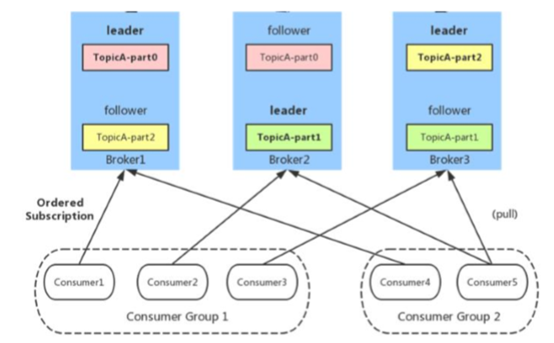
同一 Consumer Group 中的多个 Consumer 实例,不同时消费同一个 partition,等效于队列模 式。partition内消息是有序的,Consumer通过pull方式消费消息。Kafka 不删除已消费的消息
对于partition,顺序读写磁盘数据,以时间复杂度O(1)方式提供消息持久化能力。
拉取系统
- kafka broker会持久化数据,broker没有压力,因此,consumer非常适合采取pull的方式消费数据。
- consumer根据自身的能力自主控制消息拉取的速度
- consumer根据自身情况自主选择消费,例如批量消费,重复消费。
kafka的特点
l 可扩展性
当需要增加broker节点时,新增的broker会向zookeeper注册,而producer与consumer会根据注册在zookeeper上的watcher感知这些变化,并及时做出调整。
l 高吞吐率
kafka每秒可以生产约25万条消息(50MB),每秒处理55W消息(110MB)
l 持久化数据存储
可进行持久化操作,将消息持久化到磁盘,因此可以批量消费。
l 分布式系统易于扩展
所有的producer、consumer、broker都会有多个,均为分布式的
kafka汇总的更多相关文章
- 基于flink和drools的实时日志处理
1.背景 日志系统接入的日志种类多.格式复杂多样,主流的有以下几种日志: filebeat采集到的文本日志,格式多样 winbeat采集到的操作系统日志 设备上报到logstash的syslog日志 ...
- Kafka各个版本差异汇总
Kafka各个版本差异汇总 从0.8.x,0.9.x,0.10.0.x,0.10.1.x,0.10.2.x,0.11.0.x,1.0.x或1.1.x升级到2.0.0 Kafka 2.0.0引入了线 ...
- 大数据常见端口汇总-hadoop、hbase、hive、spark、kafka、zookeeper等(持续更新)
常见端口汇总:Hadoop: 50070:HDFS WEB UI端口 8020 : 高可用的HDFS RPC端口 9000 : 非高可用的HDFS RPC端口 8088 ...
- Kafka 常见问题汇总
Kafka 常见问题汇总 1. Kafka 如何做到高吞吐.低延迟的呢? 这里提下 Kafka 写数据的大致方式:先写操作系统的页缓存(Page Cache),然后由操作系统自行决定何时刷到磁盘. 因 ...
- Kafka资源汇总
终于下定决心写一点普及类的东西.很多同学对Kafka的使用很感兴趣.如果你想参与到Kafka的项目开发中,很多资源是你必须要提前准备好的.本文罗列了一些常用的Kafka资源,希望对这些develope ...
- Kafka笔记——技术点汇总
Table of contents Table of contents Overview Introduction Use cases Manual setup Assumption Configur ...
- Kafka一些常见资源汇总
终于下定决心写一点普及类的东西.很多同学对Kafka的使用很感兴趣.如果你想参与到Kafka的项目开发中,很多资源是你必须要提前准备好的.本文罗列了一些常用的Kafka资源,希望对这些develope ...
- 精尽 Kafka 学习指南【优秀学习指南汇总】
1. 视频 炼石成金 <中间件之 Kafka> 一共有 19P .概念部分讲的蛮细的. 尚硅谷 <大数据视频_Kafka视频教程> 一共 24P .讲的还不错的. 书生小四 & ...
- [转]RabbitMQ,ActiveMQ,ZeroMQ,Kafka之间的比较与资料汇总
MQ框架非常之多,比较流行的有RabbitMq.ActiveMq.ZeroMq.kafka.这几种MQ到底应该选择哪个?要根据自己项目的业务场景和需求.下面我列出这些MQ之间的对比数据和资料. 第一部 ...
随机推荐
- android中SELINUX规则分析和语法简介
1. SELINUX是可以理解为一种android上面的安全机制,是有美国国家安全局和一些公司设计的一个针对linux的安全加强系统我们可以通过配置SELINUX的相关policy,来定制自己的手机的 ...
- SqlComparison
package com.ufo.leftjoin; import java.security.MessageDigest; import java.sql.Connection; import jav ...
- ChannelEventRunnable handle RECEIVED operation error, channel is NettyChannel解决方法
[] 2019-11-23 16:17:40 [3673645] [c.a.d.r.t.d.ChannelEventRunnable]-[WARN] DubboServerHandler-10.20. ...
- Spark连续特征转化成离散特征
当数据量很大的时候,分类任务通常使用[离散特征+LR]集成[连续特征+xgboost],如果把连续特征加入到LR.决策树中,容易造成overfit. 如果想用上连续型特征,使用集成学习集成多种算法是一 ...
- BIO,NIO,AIO到NETTY
NIO 近期接触了几个产品都触及NIO,要么应用,要么改造项目,听多了也有些了解,但仍然不能真正理解,工期比较赶,还是要潜心下来看看. NIO是什么呢,应该是NOT-BLOCKING IO的意思,不阻 ...
- Python 使用 win32com 模块对 word 文件进行操作
what's the win32com 模块 win32com 模块主要为 Python 提供调用 windows 底层组件对 word .Excel.PPT 等进行操作的功能,只能在 Windows ...
- 国内pip源及pip命令
更换PIP源 PIP源在国外,速度慢,可以更换为国内源,以下是国内一些常用的PIP源. 豆瓣(douban) http://pypi.douban.com/simple/ (推荐) 清华大学 http ...
- 生命游戏(python实现,pygame显示图形)
# 游戏规则:# 生命游戏(Game of Life),或者叫它的全称John Conway's Game of Life.是英国数学家约翰·康威在1970年代所发明的一种元胞自动机.# 1. 活细胞 ...
- springBoot项目不重新上传jar包,增量升级步骤
1.把源jar包cp到一个空文件夹里,然后把该jar包解压 jar -xf www.itxm.cn-0.0.1-SNAPSHOT.jar 2.进入BOOT-INF文件夹,找到class文件夹,把要升级 ...
- javascript中var、let、const的区别
这几天修改别人的js,发现声明变量有的用var,有的用let,那它们有什么区别呢? javascript中声明变量的方式有:var.let.const 1.var (1)作用域: 整个函数范围内,或者 ...