Spark 系列(六)—— 累加器与广播变量
一、简介
在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable):
- 累加器:用来对信息进行聚合,主要用于累计计数等场景;
- 广播变量:主要用于在节点间高效分发大对象。
二、累加器
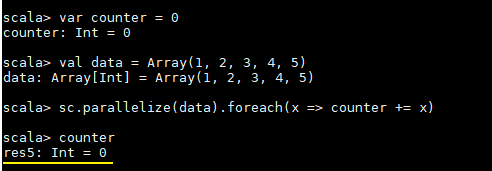
这里先看一个具体的场景,对于正常的累计求和,如果在集群模式中使用下面的代码进行计算,会发现执行结果并非预期:
var counter = 0
val data = Array(1, 2, 3, 4, 5)
sc.parallelize(data).foreach(x => counter += x)
println(counter)counter 最后的结果是 0,导致这个问题的主要原因是闭包。
2.1 理解闭包
1. Scala 中闭包的概念
这里先介绍一下 Scala 中关于闭包的概念:
var more = 10
val addMore = (x: Int) => x + more如上函数 addMore 中有两个变量 x 和 more:
- x : 是一个绑定变量 (bound variable),因为其是该函数的入参,在函数的上下文中有明确的定义;
- more : 是一个自由变量 (free variable),因为函数字面量本生并没有给 more 赋予任何含义。
按照定义:在创建函数时,如果需要捕获自由变量,那么包含指向被捕获变量的引用的函数就被称为闭包函数。
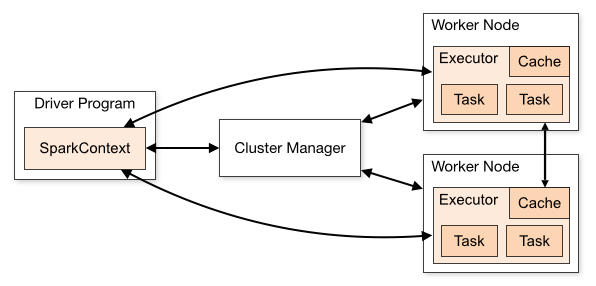
2. Spark 中的闭包
在实际计算时,Spark 会将对 RDD 操作分解为 Task,Task 运行在 Worker Node 上。在执行之前,Spark 会对任务进行闭包,如果闭包内涉及到自由变量,则程序会进行拷贝,并将副本变量放在闭包中,之后闭包被序列化并发送给每个执行者。因此,当在 foreach 函数中引用 counter 时,它将不再是 Driver 节点上的 counter,而是闭包中的副本 counter,默认情况下,副本 counter 更新后的值不会回传到 Driver,所以 counter 的最终值仍然为零。
需要注意的是:在 Local 模式下,有可能执行 foreach 的 Worker Node 与 Diver 处在相同的 JVM,并引用相同的原始 counter,这时候更新可能是正确的,但是在集群模式下一定不正确。所以在遇到此类问题时应优先使用累加器。
累加器的原理实际上很简单:就是将每个副本变量的最终值传回 Driver,由 Driver 聚合后得到最终值,并更新原始变量。
2.2 使用累加器
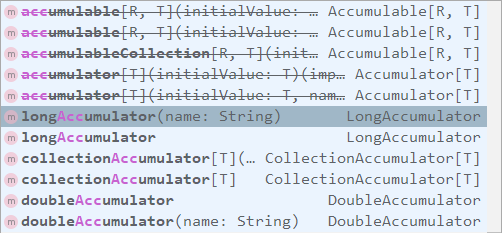
SparkContext 中定义了所有创建累加器的方法,需要注意的是:被中横线划掉的累加器方法在 Spark 2.0.0 之后被标识为废弃。
使用示例和执行结果分别如下:
val data = Array(1, 2, 3, 4, 5)
// 定义累加器
val accum = sc.longAccumulator("My Accumulator")
sc.parallelize(data).foreach(x => accum.add(x))
// 获取累加器的值
accum.value
三、广播变量
在上面介绍中闭包的过程中我们说道每个 Task 任务的闭包都会持有自由变量的副本,如果变量很大且 Task 任务很多的情况下,这必然会对网络 IO 造成压力,为了解决这个情况,Spark 提供了广播变量。
广播变量的做法很简单:就是不把副本变量分发到每个 Task 中,而是将其分发到每个 Executor,Executor 中的所有 Task 共享一个副本变量。
// 把一个数组定义为一个广播变量
val broadcastVar = sc.broadcast(Array(1, 2, 3, 4, 5))
// 之后用到该数组时应优先使用广播变量,而不是原值
sc.parallelize(broadcastVar.value).map(_ * 10).collect()参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(六)—— 累加器与广播变量的更多相关文章
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- Spark学习之路(六)—— 累加器与广播变量
一.简介 在Spark中,提供了两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: 广播变量 ...
- 入门大数据---Spark累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- Spark入门3(累加器和广播变量)
一.概要 通常情况下,当向Spark操作传递一个函数时,它会在一个远程集群节点上执行,它会使用函数中所有变量的副本.这些变量被复制到所有的机器上,远程机器上并没有被更新的变量会向驱动程序回传.在任务之 ...
- 小白学习Spark系列六:Spark调参优化
前几节介绍了下常用的函数和常踩的坑以及如何打包程序,现在来说下如何调参优化.当我们开发完一个项目,测试完成后,就要提交到服务器上运行,但运行不稳定,老是抛出如下异常,这就很纳闷了呀,明明测试上没问题, ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- Spark系列(六)Master注册机制和状态改变机制
各组件的注册流程如下图: 注册机制源码说明: 入口:org.apache.spark.deploy.master文件下的receiveWithLogging方法中的case RegisterAppli ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- SparkCore | Rdd| 广播变量和累加器
Spark中三大数据结构:RDD: 广播变量: 分布式只读共享变量: 累加器:分布式只写共享变量: 线程和进程之间 1.RDD中的函数传递 自己定义一些RDD的操作,那么此时需要主要的是,初始化工作 ...
随机推荐
- 升级pip3的正确姿势--python3 pip3 update
升级pip3的正确姿势为: pip3 install --upgrade pip 而不是 pip3 install --upgrade pip3
- element ui分页器的使用
<el-pagination layout="total, prev, pager, next, jumper" :current-page="pageInfo.p ...
- 京津冀大学生竞赛:babyphp
京津冀大学生竞赛:babyphp 比赛的时候没做出来,回来以后一会就做出来了,难受...还是基本功不扎实,都不记得__invoke怎么触发的了 放上源码 <?php error_reportin ...
- SQLSERVER根据提成比率区间计算业绩提成
USE [Employee] GO /****** Object: Table [dbo].[Commission] Script Date: 2019/11/17 14:10:21 ******/ ...
- HearthBuddy投降插件2019-11-01的使用
在AutoConcede.cs文件中找到如下代码 private List<int> _winList = new List<int> {0, 2, 4, 6, 8}; 现在的 ...
- 包含MANIFEST.MF的jar可执行应用指定classpath及spring boot应用增量升级打包实现
对于不包含MANIFEST.MF,或jar包中的MANIFEST.MF未指定MainClass的jar,可以通过java命令行选项-classpath指定classpath.但是如果是包含MainCl ...
- plsql查询数据库-中文显示问号问题
解决方法: 设置本地环境变量 :NLS_LANG=AMERICAN_AMERICA.ZHS16GBK https://blog.csdn.net/github_38358734/article/det ...
- 生成Nginx服务器SSL证书和客户端证书
Nginx服务器SSL证书 生成pass key 下面的命令用于生成一个2048bit的pass key, -passout pass:111111 用于避免交互式输入密码 [tomcat@a02 t ...
- asp.net core mvc 读取appsettings.config中文乱码问题
asp.net core mvc 读取appsettings.config中文乱码问题的解决方法如下: 用记事本打开appsettings.config,另存为的时候,编码设置为 “UTF-8”,
- 系统运维工程师装逼完全指南(转载Mark)
1.全球化的认证有助于提升逼格,什么OCM.CCIE.RHCA.CISSP等等能考都考,再不济,也要有一张系统架构设计师或者网络规划设计师的信产部认证.每过一个认证,逼格提升一档. 2.TCP/IP协 ...