scrapy2——框架简介和抓取流程
scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
scrapy的执行流程
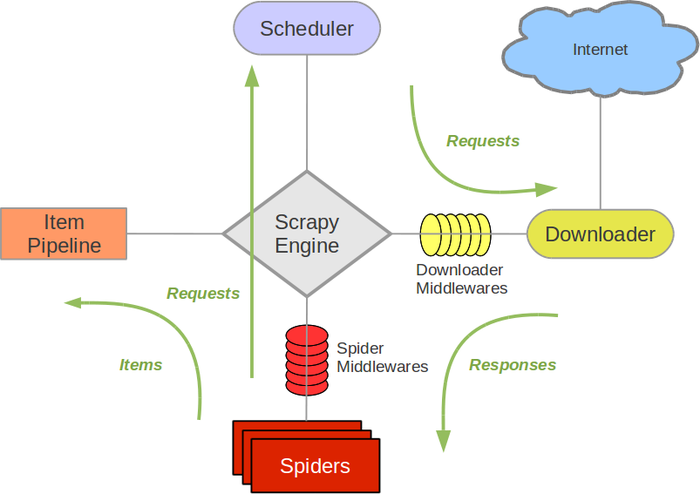
Scrapy主要包括了以下组件:
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
相关网站:https://scrapy-chs.readthedocs.io/zh_CN/stable/topics/architecture.html
Scrapy运行流程:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站
简化:
①引擎调用Spider中的start_request获取Request的一个实例化对象(通过Spider中间件),②引擎将Request的对象发送给调度器(通过调度器中间间),(引擎向调度器请求下一个Request对象并发送给调度器;重复①②),调度器会过滤掉重复的Request对象,加入到队列中,③将Request对象经过调度器中间件发送给引擎,④引擎通过下载中间件将Request对象交给下载器,下载器向互联网发送网络请求,⑤下载器把资源下载下来,并封装成响应包(Response)⑥下载器将Response对象(response)发送给引擎,⑦引擎将Response对象发送给Spider进行数据解析(如果解析得到url需要发送请求则回到①),将解析后的数据封装成Item发送给引擎,⑧引擎将(Spider返回的)爬取到的Item给ItemPipeline(管道),(process_item)进行持久化存储
scrapy2——框架简介和抓取流程的更多相关文章
- 【Nutch2.2.1基础教程之6】Nutch2.2.1抓取流程
一.抓取流程概述 1.nutch抓取流程 当使用crawl命令进行抓取任务时,其基本流程步骤如下: (1)InjectorJob 开始第一个迭代 (2)GeneratorJob (3)FetcherJ ...
- Nutch抓取流程
nutch抓取流程注入起始url(inject).生成爬取列表(generate).爬取(fetch).解析网页内容(parse).更新url数据库(updatedb)1:注入起始url(inject ...
- 【Nutch2.2.1基础教程之6】Nutch2.2.1抓取流程 分类: H3_NUTCH 2014-08-15 21:39 2530人阅读 评论(1) 收藏
一.抓取流程概述 1.nutch抓取流程 当使用crawl命令进行抓取任务时,其基本流程步骤如下: (1)InjectorJob 开始第一个迭代 (2)GeneratorJob (3)FetcherJ ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- 使用scrapy框架来进行抓取的原因
在python爬虫中:使用requests + selenium就可以解决将近90%的爬虫需求,那么scrapy就是解决剩下10%的吗? 这个显然不是这样的,scrapy框架是为了让我们的爬虫更强大. ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Python抓取框架:Scrapy的架构
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具. 一.概述 下 ...
- 爬虫抓取页面数据原理(php爬虫框架有很多 )
爬虫抓取页面数据原理(php爬虫框架有很多 ) 一.总结 1.php爬虫框架有很多,包括很多傻瓜式的软件 2.照以前写过java爬虫的例子来看,真的非常简单,就是一个获取网页数据的类或者方法(这里的话 ...
- Scrapy框架简介及小项目应用
今天来总结一下Scrapy框架的用法.scrapy的架构如下: Engine :引擎,处理整个系统的数据流处理.触发事务,是整个框架的核心. Items :项目,它定义了爬取结果的数据结构,爬取的数 ...
随机推荐
- ICEM-管肋
原视频下载地址:https://yunpan.cn/cMgkmd7u9ZPdC 访问密码 8a73
- T-MAX-冲刺总结
T-MAX-冲刺总结 这个作业属于哪个课程 班级链接 这个作业要求在哪里 作业要求的链接 团队名称 T-MAX 这个作业的目标 冲刺总结 作业的正文 T-MAX-冲刺总结 其他参考文献 面向B站,百度 ...
- TP5单元测试
tp5版本: 5.0.24 单元测试版本:1.* 1. 安装单元测试扩展: composer require topthink/think-testing .* 2.安装完毕,运行 php think ...
- 关于Android8.0 静态注册广播 行为变更的说明。
Andorid 8.0 对广播的使用做了变更. 当广播接收器使用静态注册方式使用时,除了一些例外,这个接收器接收不到隐式广播. 注意这个“隐式”是重点. 看了网上几篇文章,对这个变更理解有误.错误的理 ...
- IDEA一些自动补全方式
第一种:系统自带:可以CTRL + j 可以查看 psvm 也就是public static void main的首字母. 依次还有在方法体内键入for会有一个fori的提示,选中然后tab键,就会自 ...
- taocrypt
taocrypt MySQL Bugs: #25189: mysqld: coding.cpp:243: void TaoCrypt::Base64Decoder::Decode(): Asserti ...
- ArcMap与快捷键冲突
ArcMap与快捷键冲突 商务合作,科技咨询,版权转让:向日葵,135-4855__4328,xiexiaokui#qq.com 问题:armap进入鼠标自动导航状态,arcmap失控,系统紊乱,导致 ...
- 使用TFA启动需要知道哪些概念?
1. Boot stage BL1,BL2,BL31,BL32,BL33 2. Exception level EL3, EL1S, EL2 3. 那么放在表格里比较一下咯 Boot stage Ex ...
- phpstorm yii2框架的redis和mongodb提示
随便找个目录创建一个 yii_helper.php 文件,内容如下: /** * Class Yii */ class Yii { /** * @var MyApplication */ public ...
- CentOS / RHEL 7 更改时区
timedatectl 是 RHEL7 上的一项新功能.它可用于查询和更改系统时钟及其设置. 按照以下步骤将时区更改为中国.(以root用户身份执行以下命令). 1.使用以下命令列出所有可用的时区.你 ...