Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05

这是简易数据分析系列的第 5 篇文章。
上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据全部爬取下来。
前面我们同时说了,爬虫的本质就是找规律,当初这些程序员设计网页时,肯定会依循一些规则,当我们找到规律时,就可以预测他们的行为,达到我们的目的。
今天我们就找找豆瓣网站的规律,想办法抓取全部数据。今天的规律就从常常被人忽略的网址链接开始。
1.链接分析
我们先看看第一页的豆瓣网址链接:
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com这个很明显就是个豆瓣的电影网址,没啥好说的top250这个一看就是网页的内容,豆瓣排名前 250 的电影,也没啥好说的?后面有个start=0&filter=,根据英语提示来看,好像是说筛选(filter),从 0 开始(start)

再看看第二页的网址链接,前面都一样,只有后面的参数变了,变成了 start=25,从 25 开始;
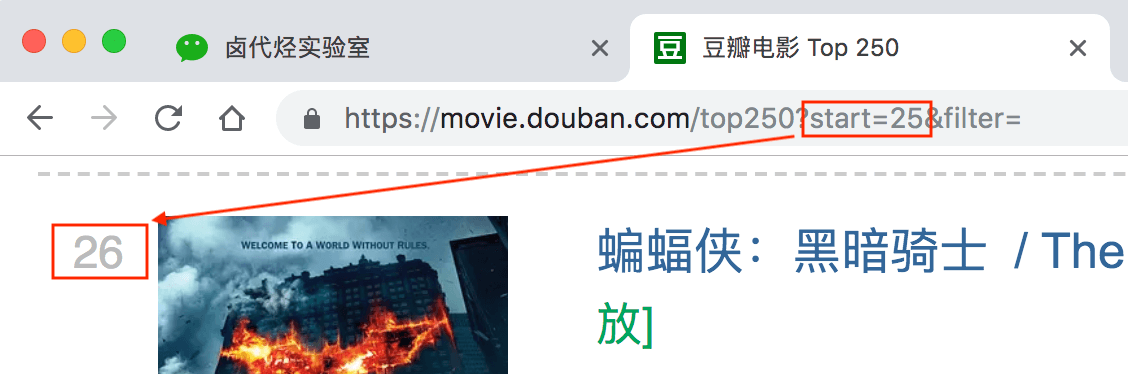
我们再看看第三页的链接,参数变成了 start=50,从 50 开始;
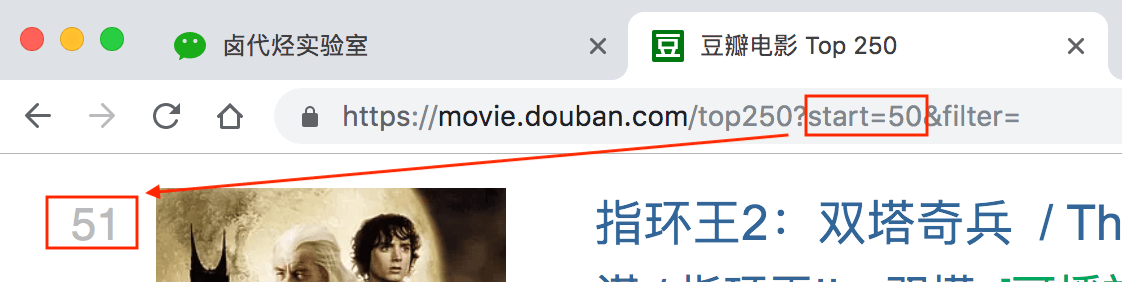
分析 3 个链接我们很容易得出规律:
start=0,表示从排名第 1 的电影算起,展示 1-25 的电影
start=25,表示从排名第 26 的电影算起,展示 26-50 的电影
start=50,表示从排名第 51 的电影算起,展示 51-75 的电影
…...
start=225,表示从排名第 226 的电影算起,展示 226-250 的电影
规律找到了就好办了,只要技术提供支持就行。随着深入学习,你会发现 Web Scraper 的操作并不是难点,最需要思考的其实还是这个找规律。
2.Web Scraper 控制链接参数翻页
Web Scraper 针对这种通过超链接数字分页获取分页数据的网页,提供了非常便捷的操作,那就是范围指定器。
比如说你想抓取的网页链接是这样的:
http://example.com/page/1http://example.com/page/2http://example.com/page/3
你就可以写成 http://example.com/page/[1-3],把链接改成这样,Web Scraper 就会自动抓取这三个网页的内容。
当然,你也可以写成 http://example.com/page/[1-100],这样就可以抓取前 100 个网页。
那么像我们之前分析的豆瓣网页呢?它不是从 1 到 100 递增的,而是 0 -> 25 -> 50 -> 75 这样每隔 25 跳的,这种怎么办?
http://example.com/page/0http://example.com/page/25http://example.com/page/50
其实也很简单,这种情况可以用 [0-100:25] 表示,每隔 25 是一个网页,100/25=4,爬取前 4 个网页,放在豆瓣电影的情景下,我们只要把链接改成下面的样子就行了;
https://movie.douban.com/top250?start=[0-225:25]&filter=
这样 Web Scraper 就会抓取 TOP250 的所有网页了。
3.抓取数据
解决了链接的问题,接下来就是如何在 Web Scraper 里修改链接了,很简单,就点击两下鼠标:
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据:

2.进入新的面板后,找到 Stiemap top250 这个 Tab,点击,再点击下拉菜单里的 Edit metadata:
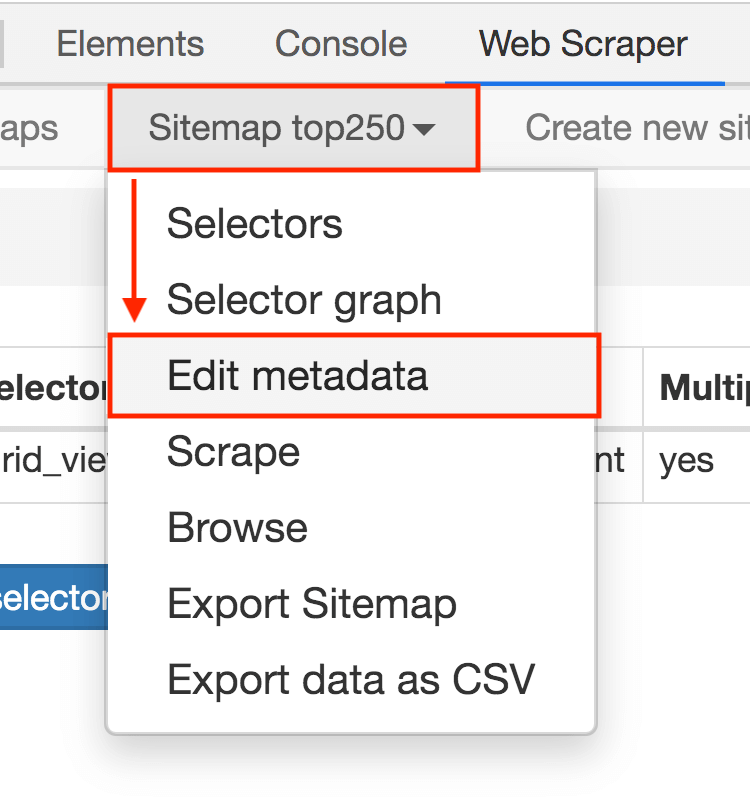
3.修改原来的网址,图中的红框是不同之处:
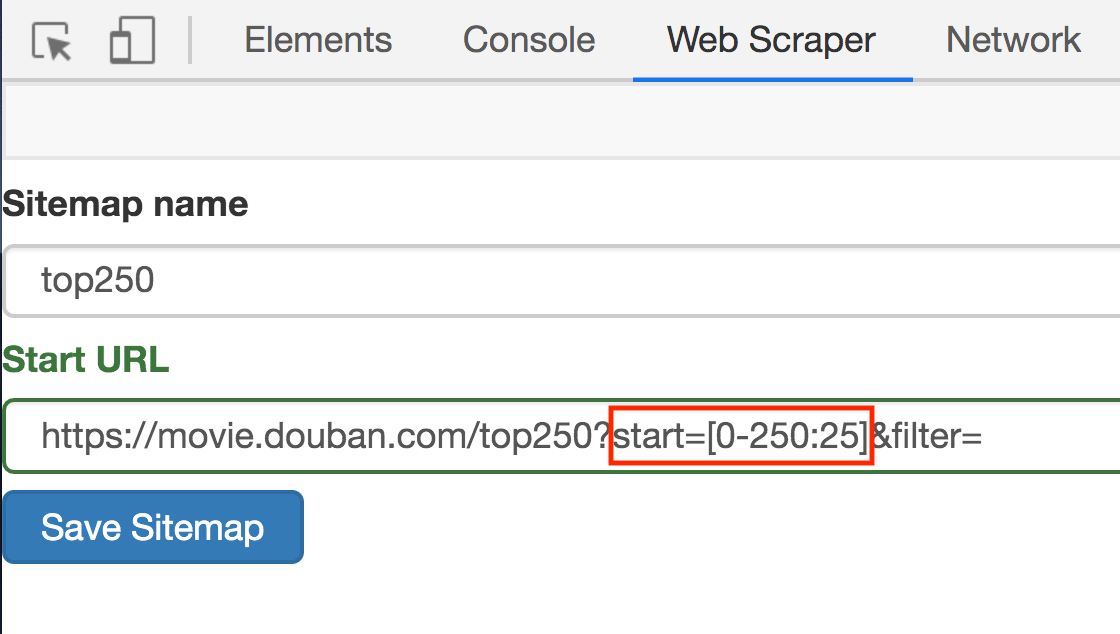
修改好了超链接,我们重新抓取网页就好了。操作和上文一样,我这里就简单复述一下:
- 点击
Sitemap top250下拉菜单里的Scrape按钮 - 新的操作面板的两个输入框都输入 2000
- 点击
Start scraping蓝色按钮开始抓取数据 - 抓取结束后点击面板上的
refresh蓝色按钮,检测我们抓取的数据
如果你操作到这里并抓取成功的话,你会发现数据是全部抓取下来了,但是顺序都是乱的。
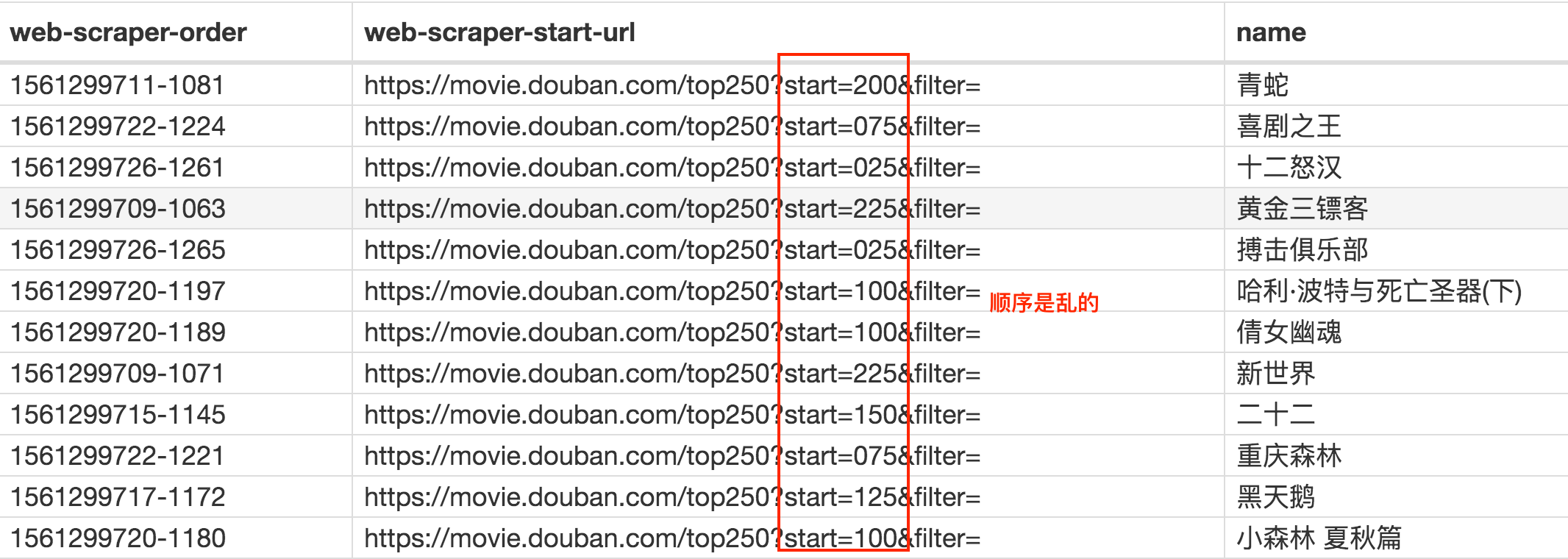
我们这里先不管顺序问题,因为这个属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
这期讲了通过修改超链接的方式抓取了 250 个电影的名字。下一期我们说一些简单轻松的内容换换脑子,讲讲 Web Scraper 如何导入别人写好的爬虫文件,导出自己写好的爬虫软件。
4.参考阅读:
简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
5.联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤代烃实验室」,关注上车防失联。

Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05的更多相关文章
- Web Scraper 翻页——控制链接批量抓取数据
 这是简易数据分析系列的第 5 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14
这是简易数据分析系列的第 14 篇文章. 今天我们还来聊聊 Web Scraper 翻页的技巧. 这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- Web自动化框架LazyUI使用手册(4)--控件抓取工具Elements Extractor详解(批量抓取)
概述 前面的一篇博文详细介绍了单个控件抓取的设计思路&逻辑以及使用方法,本文将详述批量控件抓取功能. 批量抓取:打开一个web页面,遍历页面上所有能被抓取的元素,获得每个元素的iframe.和 ...
- python实现列表页数据的批量抓取练手练手的
python实现列表页数据的批量抓取,练手的,下回带分页的 #!/usr/bin/env python # coding=utf-8 import requests from bs4 import B ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
随机推荐
- 利用Word发布文章到cnblogs博客
利用Word发布文章到cnblogs博客 用博客园cnblogs:http://www.cnblogs.com/博客名称/services/metablogapi.aspx,word老是提醒" ...
- lintcode 787. The Maze 、788. The Maze II 、
787. The Maze https://www.cnblogs.com/grandyang/p/6381458.html 与number of island不一样,递归的函数返回值是bool,不是 ...
- Jmeter全局变量设置
背景:因为BeanShell PreProcessor制造的参数是一些随机参数,每个HTTP取样器包括其他取样器拿值得时候都是单独重新取一次,所以如果当几个取样器的值都要拿同一值时,就不满足需求了,我 ...
- 008-MySQL报错-Access denied for user 'root'@'localhost' (using password: NO)
1.新安装的mysql报错 MySQL报错-Access denied for user 'root'@'localhost' (using password: NO) 解决方案 1.先停掉原来的服务 ...
- docker build时改变docker中的apt源
# Ali apt-get source.list RUN mv /etc/apt/sources.list /etc/apt/sources.list.bak && \ echo & ...
- qbittorrent搜索在线插件
https://raw.githubusercontent.com/khensolomon/leyts/master/yts.py https://raw.githubusercontent.com/ ...
- 好消息!iconfont+开始支持彩色图标
想必关注iconfont的同学都知道,iconfont最近做出了一次重大升级,升级成为iconfont+了,而这次更新,iconfont+居然开始支持彩色图标,这意味着我们能够使用更具有特色更形象的全 ...
- npm use local module
情况是这样的, 我一个Angular的项目和一个微信小程序要共用逻辑, 于是我就把它剥离出来一个Node类库, Angular倒是可以使用Reference去引用, 但是使用uniapp创建的微信小程 ...
- HTTP_HOST , SERVER_NAME 区别
当端口是80的时候,他们的内容是一样的. 但是当端口不是80的时候,就不一样了. # HTTP_HOST = SERVER_NAME:SERVER_PORT /** * 获取当前的host */ pu ...
- es操作手册
0 _search查询数据时可以指定多个index和type GET /index1,index2/type1,type2/_search GET /_all/type1/_search 相当于查询全 ...