Spark实战电影点评系统(二)
二、通过DataFrame实战电影点评系统
DataFrameAPI是从Spark 1.3开始就有的,它是一种以RDD为基础的分布式无类型数据集,它的出现大幅度降低了普通Spark用户的学习门槛。
DataFrame类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以解析到具体数据的结构信息,从而对DataFrame中的数据源以及对DataFrame的操作进行了非常有效的优化,从而大幅提升了运行效率。
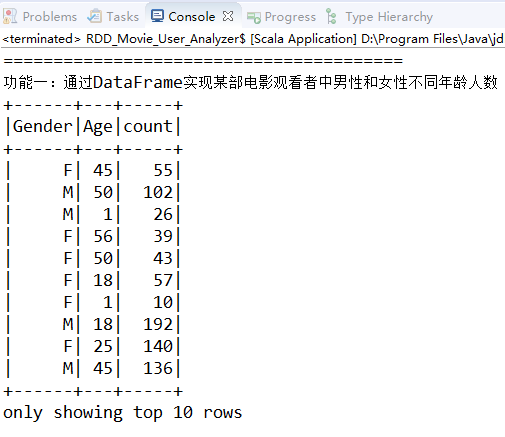
现在我们通过实现几个功能来了解DataFrame的具体用法。先来看第一个功能:通过DataFrame实现某部电影观看者中男性和女性不同年龄分别有多少人。
println("========================================")
println("功能一:通过DataFrame实现某部电影观看者中男性和女性不同年龄人数")
// 首先把User的数据格式化,即在RDD的基础上增加数据的元数据信息
val schemaForUsers = StructType(
"UserID::Gender::Age::OccupationID::Zip-code".split("::")
.map(column => StructField(column,StringType,true))
)
// 然后把我们的每一条数据变成以Row为单位的数据
val usersRDDRows = usersRDD.map(_.split("::")).map(
line => Row(line(0).trim(),line(1).trim(),line(2).trim(),line(3).trim(),line(4).trim())
)
// 使用SparkSession的createDataFrame方法,结合Row和StructType的元数据信息 基于RDD创建DataFrame,
// 这时RDD就有了元数据信息的描述
val usersDataFrame = spark.createDataFrame(usersRDDRows, schemaForUsers)
// 也可以对StructType调用add方法来对不同的StructField赋予不同的类型
val schemaforratings = StructType(
"UserID::MovieID".split("::")
.map(column => StructField(column,StringType,true)))
.add("Rating",DoubleType,true)
.add("Timestamp",StringType,true)
val ratingsRDDRows = ratingsRDD.map(_.split("::")).map(
line => Row(line(0).trim(),line(1).trim(),line(2).trim().toDouble,line(3).trim())
)
val ratingsDataFrame = spark.createDataFrame(ratingsRDDRows, schemaforratings)
// 接着构建movies的DataFrame
val schemaformovies = StructType(
"MovieID::Title::Genres".split("::")
.map(column => StructField(column,StringType,true))
)
val moviesRDDRows = moviesRDD.map(_.split("::")).map(line => Row(line(0).trim(),line(1).trim(),line(2).trim()))
val moviesDataFrame = spark.createDataFrame(moviesRDDRows, schemaformovies)
// 这里能够直接通过列名MovieID为1193过滤出这部电影,这些列名都是在上面指定的
/*
* Join的时候直接指定基于UserID进行Join,这相对于原生的RDD操作而言更加方便快捷
* 直接通过元数据信息中的Gender和Age进行数据的筛选
* 直接通过元数据信息中的Gender和Age进行数据的groupBy操作
* 基于groupBy分组信息进行count统计操作,并显示出分组统计后的前10条信息
*/
ratingsDataFrame.filter(s"MovieID==1193")
.join(usersDataFrame,"UserID")
.select("Gender", "Age")
.groupBy("Gender", "Age")
.count().show(10)
上面案例中的代码无论是从思路上,还是从结构上都和SQL语句十分类似,下面通过写SQL语句的方式来实现上面的案例。
println("========================================")
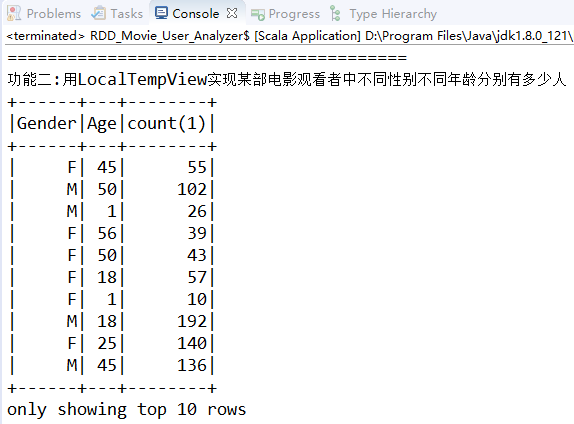
println("功能二:用LocalTempView实现某部电影观看者中不同性别不同年龄分别有多少人")
// 既然使用SQL语句,那么表肯定是要有的,所以需要先把DataFrame注册为临时表
ratingsDataFrame.createTempView("ratings")
usersDataFrame.createTempView("users")
// 然后写SQL语句,直接使用SparkSession的sql方法执行SQL语句即可。
val sql_local = "SELECT Gender,Age,count(*) from users u join ratings as r on u.UserID=r.UserID where MovieID=1193 group by Gender,Age"
spark.sql(sql_local).show(10)
这篇博文主要来自《Spark大数据商业实战三部曲》这本书里面的第一章,内容有删减,还有本书的一些代码的实验结果。随书附赠的代码库链接为:https://github.com/duanzhihua/code-of-spark-big-data-business-trilogy
Spark实战电影点评系统(二)的更多相关文章
- Spark实战电影点评系统(一)
一.通过RDD实战电影点评系统 日常的数据来源有很多渠道,如网络爬虫.网页埋点.系统日志等.下面的案例中使用的是用户观看电影和点评电影的行为数据,数据来源于网络上的公开数据,共有3个数据文件:uers ...
- 基于Spark的电影推荐系统(实战简介)
写在前面 一直不知道这个专栏该如何开始写,思来想去,还是暂时把自己对这个项目的一些想法 和大家分享 的形式来展现.有什么问题,欢迎大家一起留言讨论. 这个项目的源代码是在https://github. ...
- 实战Java虚拟机之二“虚拟机的工作模式”
今天开始实战Java虚拟机之二:“虚拟机的工作模式”. 总计有5个系列 实战Java虚拟机之一“堆溢出处理” 实战Java虚拟机之二“虚拟机的工作模式” 实战Java虚拟机之三“G1的新生代GC” 实 ...
- 编程实战——电影管理器之界面UI及动画切换
编程实战——电影管理器之界面UI及动画切换 在前文“编程实战——电影管理器之利用MediaInfo获取高清视频文件的相关信息”中提到电影管理器的目的是方便播放影片,在想看影片时不需要在茫茫的文件夹下找 ...
- ETL利器Kettle实战应用解析系列二
本系列文章主要索引如下: 一.ETL利器Kettle实战应用解析系列一[Kettle使用介绍] 二.ETL利器Kettle实战应用解析系列二 [应用场景和实战DEMO下载] 三.ETL利器Kettle ...
- (转载)Android项目实战(三十二):圆角对话框Dialog
Android项目实战(三十二):圆角对话框Dialog 前言: 项目中多处用到对话框,用系统对话框太难看,就自己写一个自定义对话框. 对话框包括:1.圆角 2.app图标 , 提示文本,关闭对话 ...
- 基于Spark的电影推荐系统(推荐系统~2)
第四部分-推荐系统-数据ETL 本模块完成数据清洗,并将清洗后的数据load到Hive数据表里面去 前置准备: spark +hive vim $SPARK_HOME/conf/hive-site.x ...
- 基于Spark的电影推荐系统(推荐系统~4)
第四部分-推荐系统-模型训练 本模块基于第3节 数据加工得到的训练集和测试集数据 做模型训练,最后得到一系列的模型,进而做 预测. 训练多个模型,取其中最好,即取RMSE(均方根误差)值最小的模型 说 ...
- 基于Spark的电影推荐系统(推荐系统~7)
基于Spark的电影推荐系统(推荐系统~7) 22/100 发布文章 liuge36 第四部分-推荐系统-实时推荐 本模块基于第4节得到的模型,开始为用户做实时推荐,推荐用户最有可能喜爱的5部电影. ...
随机推荐
- C++中vector的使用总结
vector简单说明 vector也是一个容器,并且是个顺序容器.顺序容器有可变长数组vector.双向链表list.双端队列deque. 顺序容器的定义,是因为容器元素的位置和他们的值大小无关,也就 ...
- 如何把Eclipse项目迁移到AndroidStudio(如何把项目导入安卓)--这我很困惑
学习android对我来说,就是兴趣,所以我以自己的兴趣写出的文章,希望各位多多支持!多多点赞,评论讨论加关注. 大佬必备功能. 把Eclipse项目迁移到AndroidStudio 现在就叫你如何把 ...
- nginx之升级openssl及自定义nginx版本
favicon.ico浏览器图标配置 favicon.ico 文件是浏览器收藏网址时显示的图标,当客户端使用浏览器问页面时,浏览器会自己主动发起请求获取页面的favicon.ico文件,但是当浏览器请 ...
- shell 空语句
在shell脚本中“:”是空命令,表示什么都不做类似于python中的pass
- mysql(五)执行计划
参考文档 http://blog.itpub.net/12679300/viewspace-1394985/
- 【Beta】Scrum meeting 8 & 助教参会记录
目录 写在前面 进度情况 任务进度表 Beta-1阶段燃尽图 遇到的困难 助教参会会议情况 会议具体内容 Q:最近压力大吗?临近期末,注意好时间安排 Q:最近进度如何,以后的计划如何 Q:这段时间遇到 ...
- 仅当使用了列列表并且 IDENTITY_INSERT 为 ON 时,才能为表'TableName'中的标识列指定显式值
当某表的一个列为自动增长列,是无法直接通过insert语句向给字段写入指定值,解决方法: SET IDENTITY_INSERT TABLE_NAME ON; INSERT INTO TABLE_NA ...
- convmv 解决GBK 迁移到 UTF-8 ,中文 文件名乱码
yum install convmv 命令: convmv -f GBK -t UTF-8 -r --nosmart --notest <目标目录> -f from -t to --nos ...
- CentOS7下安装ELK(nginx 、elasticsearch-5.1.1、logstash-5.1.1、kibana-5.1.1)
nginx: #直接yum安装: [root@elk-node1 ~]# yum install nginx -y 官方文档:http://nginx.org/en/docs/http/ngx_htt ...
- 支付宝小程序开发——H5跳转到小程序(获取小程序页面的链接)
前言: 这个问题支付宝小程序官方文档并没有专门说明,钉钉群的官方技术支持给了个开发者社区的帖子,详见:如何跳转小程序. 如果配置的页面没有参数还好,不会出问题,如果有参数,很可能配出来的链接无法正常获 ...