python爬虫学习心得:中国大学排名(附代码)

今天下午花时间学习了python爬虫的中国大学排名实例,颇有心得,于是在博客园与各位分享
首先直接搬代码:
import requests
from bs4 import BeautifulSoup
import bs4 def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" def fillUnivList(ulist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr.find_all('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string]) def printUnivList(ulist,num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288))) def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo,20)
main()
再附上大学排名截图:
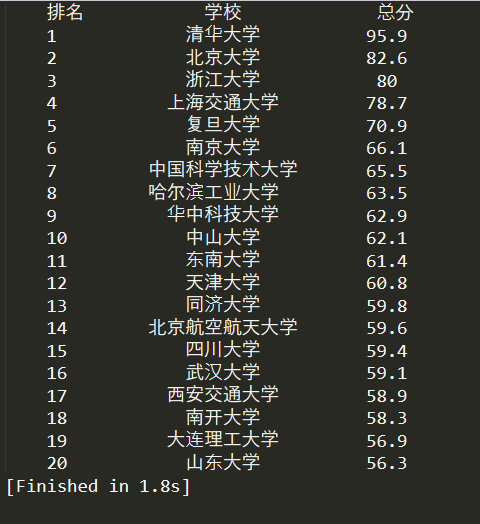
那么,现在开始代码心得讲解:
首先开始分析网页结构:
打开http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
打开chrome网页分析工具:
可以发现大学排名,学校名称,省市,总分等都处在tbody标签内
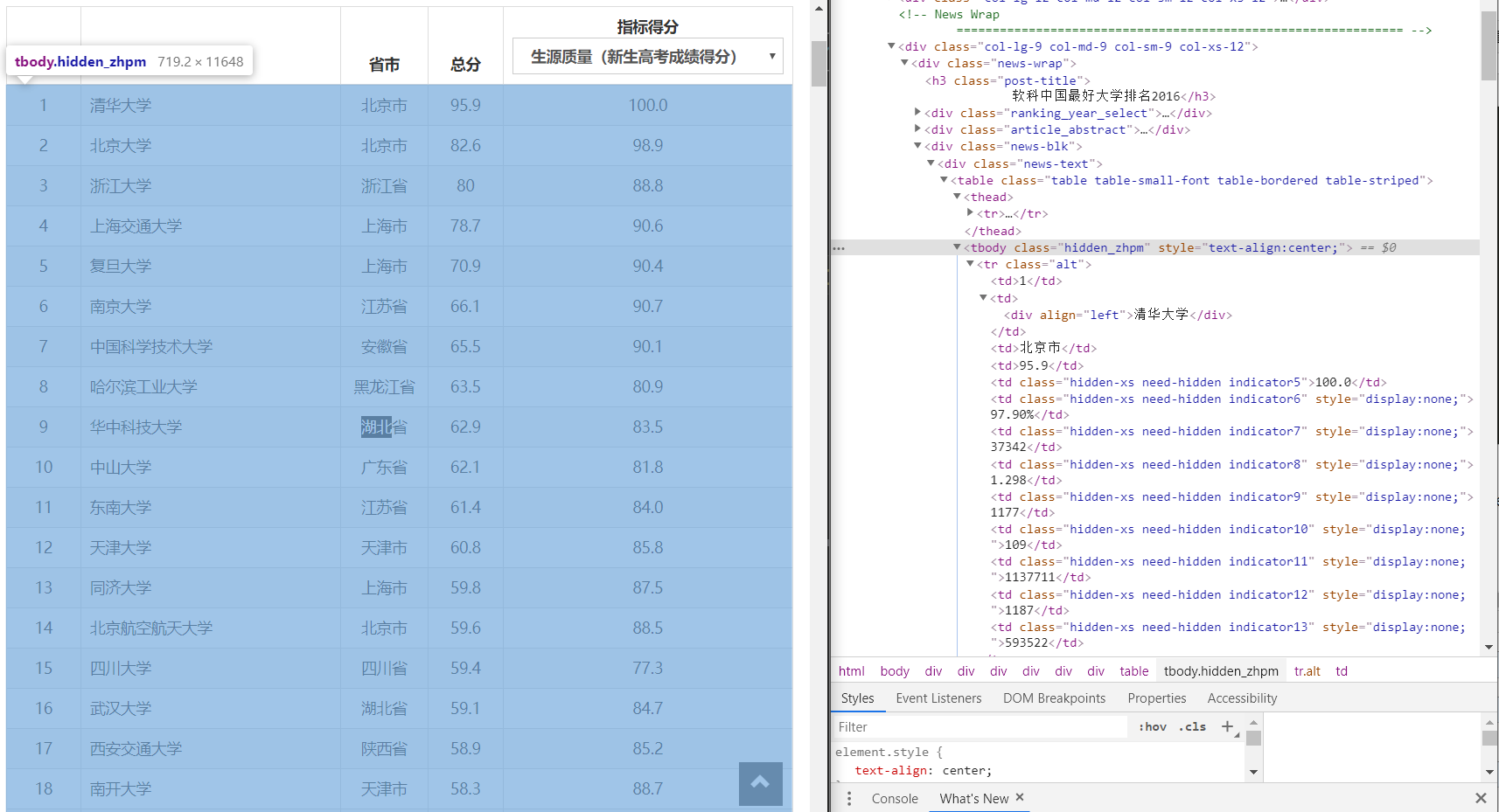
而大学名称、省市等,都处于tr标签内的td中

好,分析完成,开始构建函数架构:

主要思想为:获取网页html文本,得到需求数据,并将需求数据转化为列表,最后将列表输出
下一步:开始补充getHTMLText()部分的代码:

这里我用try except形式编写代码:
首先获取网页url,时限为30s,j接着运用 r.raise_for_status()(如果 HTTP 请求返回了不成功的状态码, r.raise_for_status() 会抛出一个 HTTPError异常)
然后将网页转码为r.apparent_encoding
返回一个r.text
这里代码运行中如果出现错误,则会return "",返回一个空字符串
接下来开始编写fillUnivList()部分代码

我们先做一锅汤,定义为soup,然后在这锅汤中遍历tr的孩子,这里每一个tr都对应一所大学的信息
而且我们需要滤掉非标签类型的其他信息,所以运用isinstance对函数类型做一个判断
if isinstance(tr,bs4.element.Tag):
这行代码就是检测标签类型,如果标签不是bs4库定义的类型,将过滤掉,同时为了运用这个方法,我们也就需要引入bs4库
由于tr标签已经被解析出来,接下来就需要对tr标签中的td标签做查询
if isinstance(tr,bs4.element.Tag):
tds = tr.find_all('td')
这里把查询到的td标签存入tds列表中
再然后在ulist表中增加:排名,大学名和总分的对应字段
ulist.append([tds[0].string,tds[1].string,tds[3].string])
接着来编写printUnivList()函数
注意:这里的{:^10}表示取10位居中对齐,^是居中对齐,\t是横向制表符。

ok,主要代码完成,希望可以帮到你。
python爬虫学习心得:中国大学排名(附代码)的更多相关文章
- python爬虫学习心得
作为一名python的忠实爱好者,我开始接触爬虫是在2017年4月份,最开始接触它的时候遇到两个梗,一个是对python还不算太了解(当然现在也仍然在努力学习它的有关内容),二是对爬虫心怀一份敬畏之心 ...
- Python爬虫学习第一记 (翻译小助手)
1 # Python爬虫学习第一记 8.24 (代码有点小,请放大看吧) 2 3 #实现有道翻译,模块一: $fanyi.py 4 5 import urllib.request 6 import u ...
- Python之爬虫-中国大学排名
Python之爬虫-中国大学排名 #!/usr/bin/env python # coding: utf-8 import bs4 import requests from bs4 import Be ...
- python网络爬虫-中国大学排名定向爬虫
爬虫定向爬取中国大学排名信息 #!/usr/bin/python3 import requests from bs4 import BeautifulSoup import bs4 #从网络上获取大学 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
随机推荐
- python calendar 时间处理类库
#python中的calendar import calendar #返回指定年的某月 def get_month(year, month): return calendar.month(year, ...
- 2019-2020-8 20199317 《Linux内核原理与分析》 第八周作业
第7章 可执行程序工作原理 1 ELF目标文件格式 1.1 ELF概述 “目标文件”,是指编译器生成的文件.“目标”指目标平台目标文件一般也叫作ABI(Application Bi ...
- 【我的物联网成长记8】超速入门AT指令集【华为云技术分享】
[摘要] 在物联网中,AT命令集可用于控制&调测设备.通信模块入网等.本文为您介绍NB-IoT常用的AT命令集及其调测工具. 什么是AT指令集 AT命令,用来控制TE(Terminal Equ ...
- html格式化输出JSON( 测试接口)
将 json 数据以美观的缩进格式显示出来,借助最简单的 JSON.stringify 函数就可以了,因为此函数还有不常用的后面2个参数. 见MDN https://developer.mozilla ...
- git配置文件—— .gitattributes
目录 .gitattributes 文档 1. gitattributes文件以行为单位设置一个路径下所有文件的属性,格式如下: 2. 在gitattributes文件的一行中,一个属性(以text属 ...
- JSP+Servlet 实现:理财产品信息管理系统
一.接业务,作分析 1.大致业务要求 1.1 使用 JSP+Servlet 实现理财产品信息管理系统,MySQL5.5 作为后台数据库,实现查看理财 和增加理财功能 1.2 查询页面效果图 1.3 添 ...
- 建议收藏:命令创建.net core3.0 web应用详解(超详细教程)
你是不是曾经膜拜那些敲几行代码就可以创建项目的大神,学习了命令创建项目你也可以成为大神,其实命令创建项目很简单. (1)cmd命令行到你打算创建项目的位置 (2)在该目录下创建解决方案文件夹JIY ...
- 【MyBatis】动态 SQL
[MyBatis]动态 SQL 转载: 目录 ========================================== 1.if 2.choose when otherwise 3.tri ...
- uploadify没反应
由于业务问题,需要用到uploadify这个插件,结果官方的case怎么弄都没问题,弄到自己的页面上就有问题了. 后来发现,这个插件是要用到swf的,但是页面加载的过程中并没有加载swf文件,所以将问 ...
- 微服务架构 SpringBoot(一)
spring Boot:官网地址 https://spring.io/ 由来: 随着spring组件功能的强大,配置文件也越来越复杂繁琐,背离了spring公司的简洁快速开发原理,2015年就推出Sp ...