02 | 健康之路 kubernetes(k8s) 实践之路 : 生产可用环境及验证
上一篇《 01 | 健康之路 kubernetes(k8s) 实践之路 : 开篇及概况 》我们介绍了我们的大体情况,也算迈出了第一步。今天我们主要介绍下我们生产可用的集群架设方案。涉及了整体拓补图,和我们采用的硬件配置,目前存在的问题等内容。
遵循上一篇提到的系列风格,这边不涉及基础的内容,这些基础的内容大家可以通过官方文档或其它渠道进行补充,主要还是分享实践经验及注意点。
涉及到的内容
- LVS
- HAProxy
- Harbor
- Etcd
- Kubernetes (master、node)
整体拓扑图
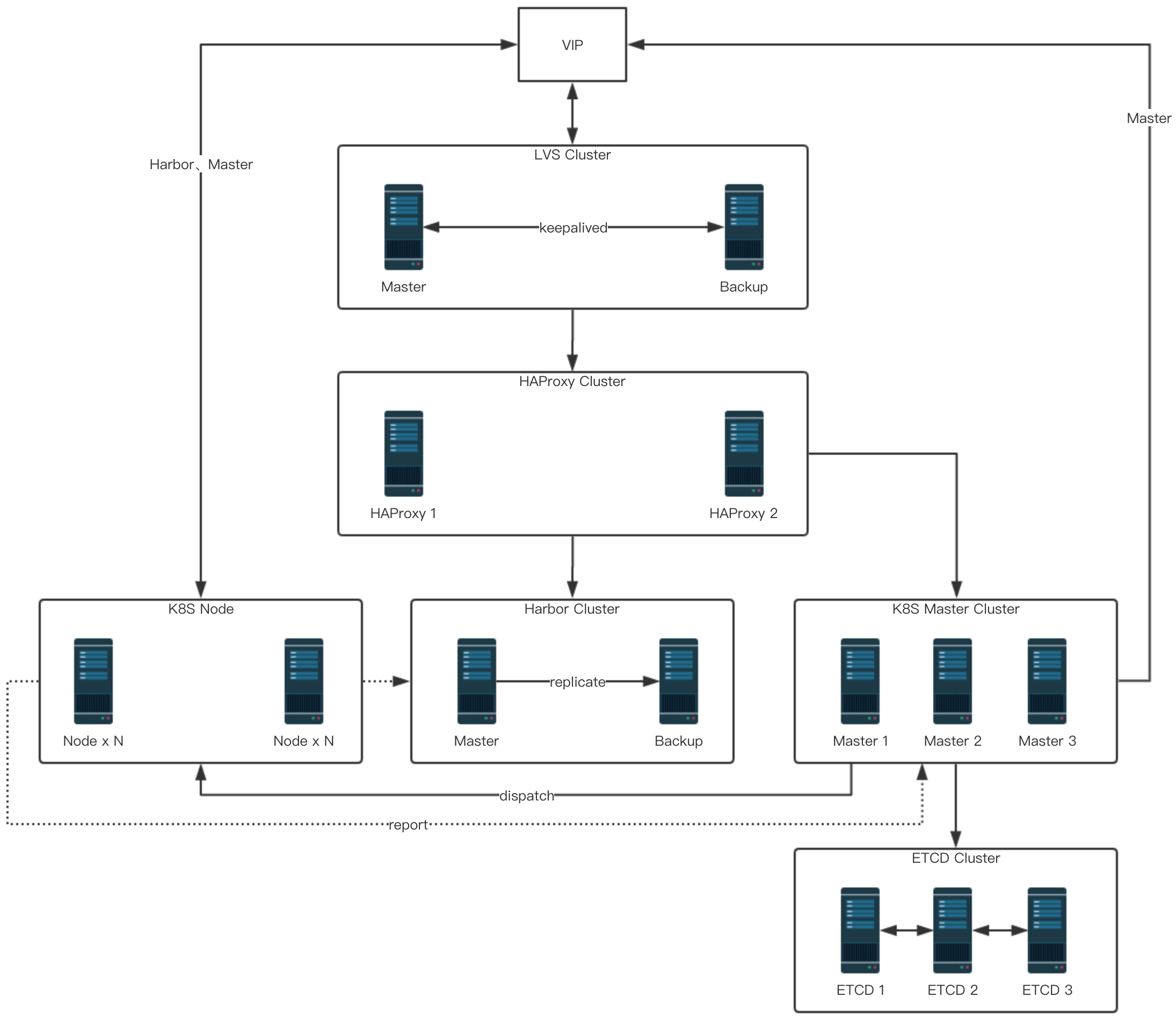
以上就是我们目前在生产线的整体拓补图(隐去了IP,除了 K8S Node块其它实例数与图中一致)
SLB
LVS 、HAProxy 被规划为基础层,主要提供了一个高可用的7层负载均衡器。
由LVS keepalived 提供一个高可用的VIP(虚拟IP)。
这个VIP反代到后端的两台HAProxy服务器。
HAProxy反代了K8S Master和Harbor服务器,提供了K8S Master API和Harbor的高可用和负载均衡能力。
为什么不使用Nginx?
这个使用nginx也完全没问题,根据自己的喜好选择,这边选择HAProxy的主要原因是k8s官方文档中出现了HAProxy而不是Nginx。
能否不使用HAProxy,直接从LVS转发到Master?
理论上可行,我们没有试验。
如果不缺两台机器推荐还是架设一层具有7层代理能力的服务。
k8s apiserver、harbor、etcd都是以HTTP的方式提供的api,如果有7层代理能力的服务后续会更容易维护和扩展。
硬件配置
|
用途 |
数量 |
CPU |
内存 |
|
Keepalived |
2 |
2 |
4GB |
|
HAProxy |
2 |
2 |
4GB |
kubernetes集群
kubernetes集群主要有两种类型的节点:master和node。
master则是集群领导。
node是工作者节点。
可以看出这边主要的工作在master节点,node节点根据具体需求随意增减就好了。
master节点的高可用拓补官方给出了两种方案。
- Stacked etcd topology(堆叠etcd)
External etcd topology(外部etcd)
可以看出最主要的区别在于etcd。
第一种方案是所有k8s master节点都运行一个etcd在本机组成一个etcd集群。
第二种方案则是使用外部的etcd集群(额外搭建etcd集群)。
我们采用的是第二种,外部etcd,拓补图如下:

如果采用堆叠的etcd拓补图则是:

这边大家可以根据具体的情况选择,推荐使用第二种,外部的etcd。
参考来源:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/
Master节点的组件
- apiserver
- controller-manager
- scheduler
一个master节点主要含有上面3个组件 ( 像cloud-controller-manager这边就不多做说明了,正常基本不会用到 )。
apiserver: 一个api服务器,所有外部与k8s集群的交互都需要经过它。(可水平扩展)
controller-manager: 执行控制器逻辑(循环通过apiserver监控集群状态做出相应的处理)(一个master集群中只会有一个节点处于激活状态)
scheduler: 将pod调度到具体的节点上(一个master集群中只会有一个节点处于激活状态)
可以看到除了apiserver外都只允许一个
实例处于激活状态(类HBase)运行于其它节点上的实例属于待命状态,只有当激活状态的实例不可用时才会尝试将自己设为激活状态。
这边牵扯到了领导选举(zookeeper、consul等分布式集群系统也是需要领导选举)
Master高可用需要几个节点?失败容忍度是多少?
k8s依赖etcd所以不存在数据一致性的问题(把数据一致性压到了etcd上),所以k8s master不需要采取投票的机制来进行选举,而只需节点健康就可以成为leader。
所以这边master并不要求奇数,偶数也是可以的。
那么master高可用至少需要2个节点,失败容忍度是(n/0)+1,也就是只要有一个是健康的k8s master集群就属于可用状态。(这边需要注意的是master依赖etcd,如果etcd不可用那么master也将不可用)
Master组件说明: https://kubernetes.io/docs/concepts/overview/components/
部署文档: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
硬件配置
|
用途 |
数量 |
CPU |
内存 |
|
k8s master |
3 |
4 |
6GB |
etcd
etcd是一个采用了raft算法的分布式键值存储系统。
这不是k8s专属的是一个独立的分布式系统,具体的介绍大家可以参考官网,这边不多做介绍。
我们采用了 static pod的方式部署了etcd集群。
失败容忍度
最小可用节点数:(n/2)+1
|
总数 |
健康数 |
失败数 |
|
1 |
1 |
0 |
|
2 |
2 |
0 |
|
3 |
2 |
1 |
|
4 |
3 |
1 |
|
5 |
3 |
2 |
|
6 |
4 |
2 |
|
7 |
4 |
3 |
|
8 |
5 |
3 |
|
9 |
5 |
4 |
硬件配置
|
用途 |
数量 |
CPU |
内存 |
|
etcd |
3 |
4 |
8GB |
官网: https://etcd.io/
官方硬件建议: https://etcd.io/docs/v3.3.12/op-guide/hardware/
部署文档: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
Harbor
harbor是一个开源的docker镜像库系统。
眼尖的人可以看出,拓补图中的harbor拓补的高可用其实是存在问题的。
我们目前采用的是双主模式:
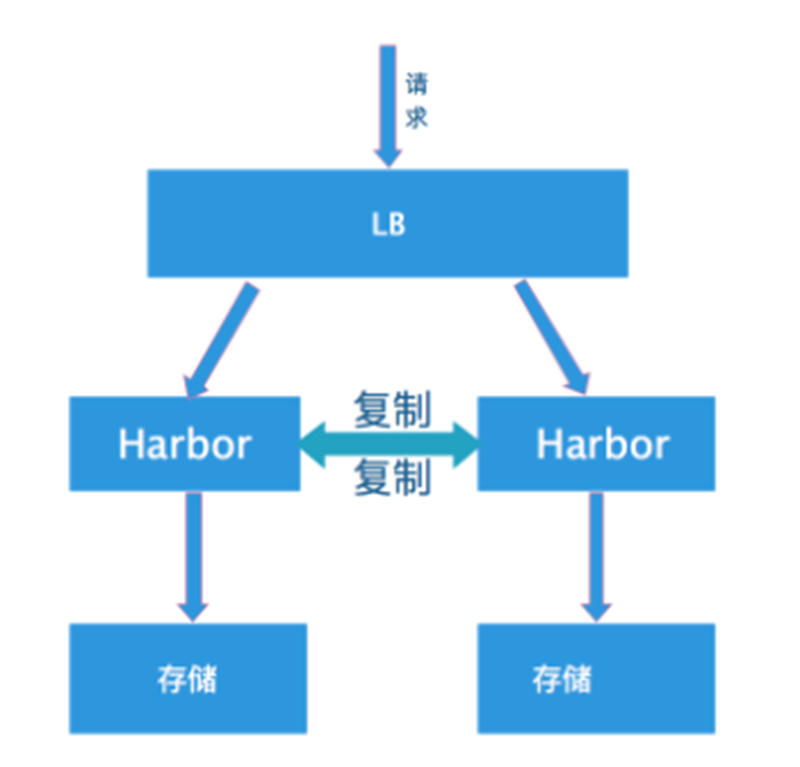
可以发现,如果复制过程中出现了问题那么就可能会造成间歇性pull镜像失败。
真正推荐的做法是共享后端存储,将harbor实例做成无状态的:
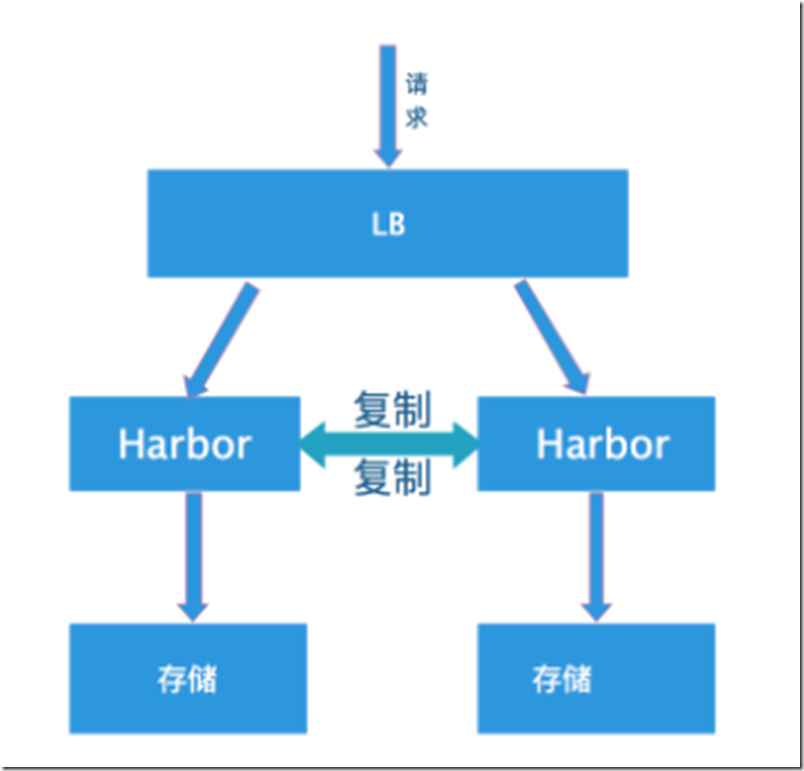
由于我们刚起步,还没有搭建分布式存储系统,后面当搭建了Ceph集群后会转成这种模式。
如果大家现状允许可以直接采用共享存储的方式搭建harbor。
高可用验证
至此生产可用的k8s集群已“搭建完成”。为什么打引号?因为我们还没有进行测试和验证,下面给出我们列出的上线前的验证清单。
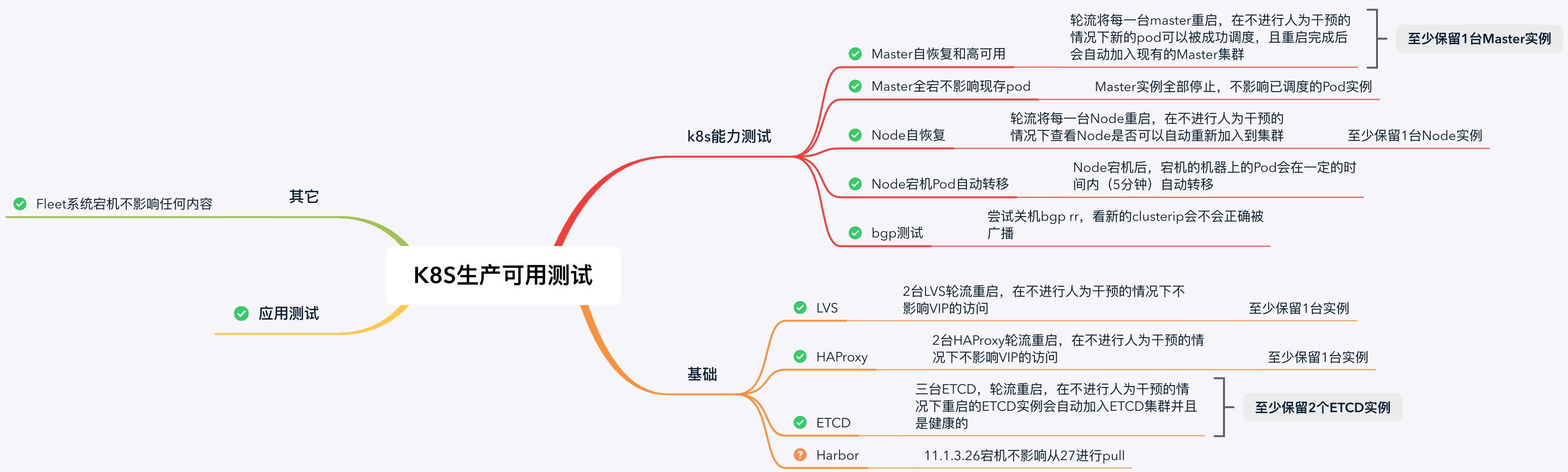
其中harbor由于我们采用的是双主,所以目前还标记为警告状态。
还有涉及的BGP相关的验证不在此次文章内容中,后续会为大家说明。
写在最后
还有一点需要注意的是物理机的可用性,如果这些虚拟机全部在一台物理机上那么还是存在“单点问题”。这边建议至少3台物理机以上。
为什么需要3台物理机以上?
主要是考虑到了etcd的问题,如果只有两台物理机部署了5个etcd节点,那么部署了3个etcd的那台物理机故障了,则不满足etcd失败容忍度而导致etcd集群宕机,从而导致k8s集群宕机。
下一篇大概会是什么内容?
应该会写,k8s master、node的一些可选配置调优和推荐。
02 | 健康之路 kubernetes(k8s) 实践之路 : 生产可用环境及验证的更多相关文章
- 01 | 健康之路 kubernetes(k8s) 实践之路 : 开篇及概况
近几年容器相关的技术大行其道,容器.docker.k8s.mesos.service mesh.serverless等名词相信大家多少都有听过,国内互联网公司无一不接触和使用相关技术. 健康之路早在2 ...
- 一寸宕机一寸血,十万容器十万兵|Win10/Mac系统下基于Kubernetes(k8s)搭建Gunicorn+Flask高可用Web集群
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_185 2021年,君不言容器技术则已,欲言容器则必称Docker,毫无疑问,它是当今最流行的容器技术之一,但是当我们面对海量的镜像 ...
- aspnetcore.webapi实践k8s健康探测机制 - kubernetes
1.浅析k8s两种健康检查机制 Liveness k8s通过liveness来探测微服务的存活性,判断什么时候该重启容器实现自愈.比如访问 Web 服务器时显示 500 内部错误,可能是系统超载,也可 ...
- DolphinScheduler & K8s 在优路科技的实践
T 摘要 · 本文通过介绍DolphinScheduler on Kubernetes 在优路科技的实践,阐述了DolphinScheduler如何在云原生时代,更好地助力企业实现高效的数据调度解决方 ...
- aspnetcore.webapi实战k8s健康探测机制 - kubernetes
1.浅析k8s两种健康检查机制 Liveness k8s通过liveness来探测微服务的存活性,判断什么时候该重启容器实现自愈.比如访问 Web 服务器时显示 500 内部错误,可能是系统超载,也可 ...
- 从 Spark 到 Kubernetes — MaxCompute 的云原生开源生态实践之路
2019年5月14日,喜提浙江省科学技术进步一等奖的 MaxCompute 是阿里巴巴自研的 EB 级大数据计算平台.该平台依托阿里云飞天基础架构,是阿里巴巴在10年前做飞天系统的三大件之分布式计算部 ...
- Kubernetes(k8s) docker集群搭建
原文地址:https://blog.csdn.net/real_myth/article/details/78719244 一.Kubernetes系列之介绍篇 •Kubernetes介绍 1.背 ...
- K8S 使用Kubeadm搭建高可用Kubernetes(K8S)集群 - 证书有效期100年
1.概述 Kubenetes集群的控制平面节点(即Master节点)由数据库服务(Etcd)+其他组件服务(Apiserver.Controller-manager.Scheduler...)组成. ...
- 知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路
本文来自知乎官方技术团队的“知乎技术专栏”,感谢原作者陈鹏的无私分享. 1.引言 知乎存储平台团队基于开源Redis 组件打造的知乎 Redis 平台,经过不断的研发迭代,目前已经形成了一整套完整自动 ...
随机推荐
- github 上传更新代码(最简单的方法)
1.首先你需要一个github账号,还没有的朋友先去注册一个吧! GitHub地址:https://github.com/ 我们使用git需要先安装git工具,这里给出下载地址,下载后一路直接安装即可 ...
- 【React入门】React父子组件传值demo
公司一直是前后端分离的,最近集团开始推进中后台可视化开发组件(基于React封装),跟师兄聊起来也听说最近对后台开发人员的前端能力也是越来越重视了.所以作为一名后端,了解下前端的框架对自己也是大有好处 ...
- 【设计模式】行为型08状态模式(status Pattern)
状态模式(status Pattern) 定义:允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类.其别名为状态对象(Objects for States).与命令模式 ...
- 使用回调的方式实现中间件-laravel
$app = function ($request) { echo $request . "\n"; return "项目运行中....."; }; // 现在 ...
- Mac上使用ssh连接服务器title显示服务器的ip
Mac上使用ssh连接服务器title显示服务器的ip 使用Mac开发时,管理的服务器过多时,会搞混乱.可能有时啪啪啪一顿操作,最后发现操作错了机器. 解决方案 在远程服务器上,编辑vim /etc/ ...
- POJ 2914:Minimum Cut(全局最小割Stoer-Wagner算法)
http://poj.org/problem?id=2914 题意:给出n个点m条边,可能有重边,问全局的最小割是多少. 思路:一开始以为用最大流算法跑一下,然后就超时了.后来学习了一下这个算法,是个 ...
- HDU 4763:Theme Section(KMP)
http://acm.hdu.edu.cn/showproblem.php?pid=4763 Theme Section Problem Description It's time for mus ...
- Codeforces 757B:Bash's Big Day(分解因子+Hash)
http://codeforces.com/problemset/problem/757/B 题意:给出n个数,求一个最大的集合并且这个集合中的元素gcd的结果不等于1. 思路:一开始把素数表打出来, ...
- python数据库-MySQL数据库高级查询操作(51)
一.什么是关系? 1.分析:有这么一组数据关于学生的数据 学号.姓名.年龄.住址.成绩.学科.学科(语文.数学.英语) 我们应该怎么去设计储存这些数据呢? 2.先考虑第一范式:列不可在拆分原则 这里面 ...
- 机器学习经典算法之PageRank
Google 的两位创始人都是斯坦福大学的博士生,他们提出的 PageRank 算法受到了论文影响力因子的评价启发.当一篇论文被引用的次数越多,证明这篇论文的影响力越大.正是这个想法解决了当时网页检索 ...