浅谈 KMP 算法
最近在复习数据结构,学到了 KMP 算法这一章,似乎又迷糊了,记得第一次学习这个算法时,老师在课堂上讲得唾沫横飞,十分有激情,而我们在下面听得一脸懵比,啥?这是个啥算法?啥玩意?再去看看书,完全听不懂呀?总之,觉得十分懵比,课后去看了一些视频和博客,才慢慢有一点理解,学习不是一蹴而就的,需要脚踏实地的努力。过了三年,重新温习这个算法,似乎依旧不是很明白,理解得不够透彻,重新拾起课本和视频,认真学习这个算法。
1.KMP 算法简介
KMP 算法是由三位老前辈(D.E.Knuth,J.H.Morris 和 V.R.Pratt )的研究结果,该算法巧妙之处在于避免重复遍历的情况,全称叫做克努特-莫里斯-普拉特算法,简称 KMP 算法,D.E.Knuth,编写了《计算机程序设计艺术》写完了第四卷,这部著作被誉为计算机领域中的“相对论”。
2.子串 next 数组的计算
KMP 算法关键点是先求出 next[] 数组,这个 next 数组只与模式匹配串有关,例如以 "abababca" 这个子串计算一下它的 next 数组
下标为 index = 0 开始 ,
index = 0 ,"a" 的前缀和后缀都为空集,value = 0;
index = 1,"ab" 的前缀和后缀分别为 "a" 和 "b",不相等,value = 0;
index = 2, "aba" 的前缀是 "a"、 "ab",后缀是 "ba"、"a",有相同交集 "a",长度为 1, value = 1;
index = 3, "abab" 的前缀是 "a"、"ab"、"aba",后缀是 "bab"、"ab"、"b",有最长相同交集 "ab", 长度为 2,value = 2;
index = 4,"ababa" 的前缀是 "a"、"ab"、"aba"、"abab",后缀是 "baba"、"aba"、"ba"、"a",有最大相同交集 "aba",长度为 3, value = 3;
index = 5,"ababab" 的前缀是 "a"、"ab"、"aba"、"abab"、"ababa",后缀是 "babab"、"abab"、"bab"、"ab"、"b",有最长相同交集 "abab",长度为 4, value = 4;
index = 6,"abababc" 的前缀是 "a"、"ab"、"aba"、"abab"、"ababa"、"ababab",后缀是 "bababc"、"ababc"、"babc"、"abc"、"bc"、"c",没有相同交集,value = 0;
index = 7,"abababca" 的前缀是 "a"、"ab"、"aba"、"abab"、"ababa"、"abababc",后缀是 "bababca"、"ababca"、"babca"、"abca"、"bca"、"ca"、"a",有相同交集 "a",长度为1,value = 1;
最后结果如下:
char: | a | b | a | b | a | b | c | a |
index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
value: | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |
3、如何使用 next[] 数组
得到子串的 next 数组以后,在目标串中匹配使用 next 数组,通过使用 next 数组避免重复的匹配已经匹配过的元素,如果找到长度为 partial_match_length 的部分匹配,并且表 next [partial_match_length]> 1,我们可以提前跳过 partial_match_length - next[partial_match_length-1] 个字符
总结移动位数 = 已匹配的字符数 - 对应的部分匹配值
char: | a | b | a | b | a | b | c | a |
index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
value: | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |
以 "bacbababaabcbab" 为例说明它的匹配过程,第一次匹配, 调到 index = 1 位置,如下
bacbababaabcbab
|
abababca
不难看出, 部分匹配的长度为 partial_match_length = 1, 但是在 next [ partial_match_length - 1] = 0,也就是 next[0] = 0,这个元素,所以我们不需要跳过任何元素,接下来 cb 和 a 都不匹配直接向右匹配,到了下一个 a 匹配的地方
bacbababaabcbab
| | | | |
abababca
来到这个地方,你会发现此时部分匹配的长度为 5 , partial_match_length = 5, next[partial_match_length - 1] = next[4],查 next 数组,next[4] = 3,这就意味着在接下来的匹配中我们要跳过 partial_match_length - next[partial_match_length-1] ,即 5 - next[4] = 5 - 3 = 2,要跳过 2 个字符,所以接下来的匹配应该变成了如下所示:
bacbababaabcbab
xx | | |
abababca
xx 表示跳过了,部分匹配长度为 3, partial_match_length = 3,next[partial_match_length - 1] = next[2] = 1,接下来匹配中要跳过
partial_match_length - next[partial_match_length - 1], 即 3 - 1 = 2, 跳过 2 个字符后的匹配情况如下:
bacbababaabcbab
xx |
abababca
得到部分匹配长度为 1 , partial_match_length = 1, next[partial_match_length - 1] = 0,接下来匹配不用跳过字符,向右匹配,匹配串比剩余的主串要长,所以没有找到匹配的字符串。
4、KMP 算法代码实现,使用 C 语言实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void get_next(char T[],int next[])//next数组
{
int i,j;
i=;//前
j=;//后
next[]=;
while(j<T[]) {
if(i== || T[i]==T[j])
{
i++;
j++;
next[j]=i;
/*if(T[i]!=T[j])
{
next[j]=i;
}
else
{ next[j]=next[i];
}*/
}
else
{
i=next[i];
}
}
}
int Index_KMP(char S[],char T[])
{
int next[];
int i=;
int j=;
get_next(T,next);//获得next数组
/*
for(i=1;i<=T[0];i++)
{
printf("%d ",next[i]);
}
*/
while(i<=S[] && j<=T[])
{
if(j==||S[i]==T[j])
{
i++;
j++;
}
else
{
j=next[j];
}
}
if(j>T[])
return i-T[];
return ; }
int main (){
char T[],S[];
int i,k;
while(scanf("%s %s",S,T)!=EOF)
{
k=strlen(T);
for(i=strlen(T);i>;i--)//向后移动
{
T[i]=T[i-];
}
T[]=k;
k=strlen(S);
for(i=strlen(S);i>;i--)//向后移动
{
S[i]=S[i-];
}
S[]=k;
printf("%d\n",Index_KMP(S,T));
}
return ; }
运行结果如下:
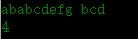
4 为第一个出现匹配字符串的数字下标从 1 开始
5、个人总结
经过这次对于 KMP 算法的练习,使我重新练习了一遍,关于 KMP 中算法实现的某些步骤依旧不是很清楚,有些地方想得还不是特别明白,也许这就是差距。今天出现了一些代码的 Bug,为了解决 Bug 查了一些网站的资料,重新温习了 C语言的使用,今天过得很充实。
更多有趣、好玩、实用的内容,请关注我的微信公众号:
参考资料:
http://jakeboxer.com/blog/2009/12/13/the-knuth-morris-pratt-algorithm-in-my-own-words/
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
https://liam.page/2016/12/20/KMP-Algorithm/
https://blog.dotcpp.com/a/8986
浅谈 KMP 算法的更多相关文章
- 浅谈KMP算法及其next[]数组
KMP算法是众多优秀的模式串匹配算法中较早诞生的一个,也是相对最为人所知的一个. 算法实现简单,运行效率高,时间复杂度为O(n+m)(n和m分别为目标串和模式串的长度) 当字符串长度和字符集大小的比值 ...
- 单模式串匹配----浅谈kmp算法
模式串匹配,顾名思义,就是看一个串是否在另一个串中出现,出现了几次,在哪个位置出现: p.s. 模式串是前者,并且,我们称后一个 (也就是被匹配的串)为文本串: 在这篇博客的代码里,s1均为文本串, ...
- 浅谈KMP算法
一.介绍 烤馍片KMP算法是用来处理字符串匹配问题的.比如说给你两个字符串A,B,问B是不是A的子串? 比如,eg就是aeggx的子串 一般讲字符串A称为主串,用来匹配的B串称为模式串 定义n为字符串 ...
- 【字符串算法3】浅谈KMP算法
[字符串算法1] 字符串Hash(优雅的暴力) [字符串算法2]Manacher算法 [字符串算法3]KMP算法 这里将讲述 [字符串算法3]KMP算法 Part1 理解KMP的精髓和思想 其实KM ...
- 【文文殿下】浅谈KMP算法next数组与循环节的关系
KMP算法 KMP算法是一种字符串匹配算法,他可以在O(n+m)的时间内求出一个模式串在另一个模式串下出现的次数. KMP算法是利用next数组进行自匹配,然后来进行匹配的. Next数组 Next数 ...
- 浅谈KMP算法——Chemist
很久以前就学过KMP,不过一直没有深入理解只是背代码,今天总结一下KMP算法来加深印象. 一.KMP算法介绍 KMP解决的问题:给你两个字符串A和B(|A|=n,|B|=m,n>m),询问一个字 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
随机推荐
- Fcitx使用搜狗词库与皮肤
在 \(\text{Linux}\) 环境下,\(\text{Fcitx}\) 确实是最好用的开源输入法之一.然而 \(\text{Windows}\) 下的巨头输入法 -- 搜狗,对 \(\text ...
- JDK-基于Windows环境搭建
JDK安装: 毋庸置疑你要跑java程序,肯定少不了JDK,如jemter还有还有~ 下载jdk地址1:https://pan.baidu.com/s/1FIvGNvZSy0EpCBxHCz07nA ...
- Android 世界中,谁喊醒了 Zygote ?
本文基于 Android 9.0 , 代码仓库地址 : android_9.0.0_r45 文中源码链接: SystemServer.java ActivityManagerService.java ...
- wsgi相关的
目录 web 本质 http协议 请求方式 响应状态码 请求与响应文本格式 目录 web 本质 本质就是浏览器和服务器进行通信, http协议 也叫超文本传输协议(英文:HyperText T ...
- requests模块(代理)篇
- 用户验证 - 代理验证 #可能需要使用HTTP basic Auth, 可以这样 # 格式为 用户名:密码@代理地址:端口地址 proxy = { "http": " ...
- Java零基础手把手系列:HashMap排序方法一网打尽
HashMap的排序在一开始学习Java的时候,比较容易晕,今天总结了一些常见的方法,一网打尽.HashMap的排序入门,看这篇文章就够了. 1. 概述 本文排序HashMap的键(key)和值(va ...
- top命令之性能分析
top命令详解 当前时间20:27:12 当前系统运行时间3:18秒 1个用户 系统负载平均长度为0.00,0.00,0.00(分别为1分钟.5分钟.15分钟前到现在的平均值) 第二行为进程 ...
- 02 【PMP】项目管理系统、PMIS、工作授权系统、配置管理系统、变更管理
PMBOK融会贯通:盘点八大系统<项目管理系统.PMIS.工作授权系统.配置管理系统.变更管理> 一. PMBOK相关系统: 工作系统作为事业环境因素,提高或限制项目管理的灵活性,并 ...
- [Luogu2967] 视频游戏的麻烦Video Game Troubles
农夫约翰的奶牛们游戏成瘾!本来约翰是想要按照调教兽的做法拿她们去电击戒瘾的,可是 后来他发现奶牛们玩游戏之后比原先产更多的奶.很明显,这是因为满足的牛会产更多的奶. 但是,奶牛们在哪个才是最好的游 ...
- Ubuntu使用中遇到的的一些问题
制作ubuntu启动盘后,U盘只读. ubuntu自带的"启动盘创建器(usb-creator-gtk)"制作启动盘后,U盘只读. 打开ubuntu自带的"磁盘(hard ...