【字符串算法3】浅谈KMP算法
【字符串算法1】 字符串Hash(优雅的暴力)
【字符串算法2】Manacher算法
【字符串算法3】KMP算法
这里将讲述 【字符串算法3】KMP算法
Part1 理解KMP的精髓和思想
其实KMP我也不太懂。。有可能会误人子弟qwq
好的吧现在开始
KMP处理这样一个问题:
给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置。
一般的博客都是讲述怎么怎么暴力匹配,然后再讲KMP算法,显然这样的安排是不合适的,
因为来看KMP的OIer基本上都是会暴力匹配的。
那么我们节约时间直接从KMP算法开始,如果不会暴力匹配,右转字符串入门练习场
概念:
模式串:记为T,表示待匹配的串即T在某个长串中的位置即为所求
文本串:记为S,表示待匹配的文本
一般情况下|T|<=|S|,显然当|T|>|S|时输出为空
失配:对于S[j]!=T[i] 我们称两个串在二元组(i,j)时失配
首先是KMP的精髓:
对于每次失配之后,我都不会从头重新开始枚举,
而是根据我已经得知的数据,从某个特定的位置开始匹配;
而对于模式串的每一位,都有唯一的“特定变化位置”,这个在失配之后的特定变化位置可以帮助我们利用已有的数据不用从头匹配,
从而节约时间。
第一步我们需要知道上述两个关键词,找出对于模式串每一个位子失配然后移到的那个位置。(即next数组)
其实,next数组的理解才是KMP中的难点,一般来说我们定义next数组为:
next[]表示 : 模式串每i位子失配时然后移到的那个位置(这里是指向模式串的指针i指向的位置,而不是真实的将模式串移动)
显然,上述定义是完全正确的。 但是等于什么都没说。
【我也知道啊,关键是怎么求】
我现在给出我对next数组的理解
在模式串中,对于每一位 T(i)它的 next 数组应当是记录一个位置 j, | j≤i 并且满足 T[i]==T[j] 并且在 j不等于1 时
理应满足T[1]至T[j-1]分别与 T[i−j+1]~T[i−1] 按位相等
那么next数组中存在的是一个元素j要求保证1到j前面那个字符,和i前面j-1个字符完全相等
(注意到此时若i失配我们就可以把指针跳到next[i]就不会有冗余比较了)
举个栗子:
模式串:a b c a b
文本串:a b c a c a b a b c a b
求出模式串的next数组(当且仅当不存在符合条件的j的时候是0)
next: 0 0 0 1 2
模式串:a b c a b
文本串:a b c a c a b a b c a b
当发现b和c不相等的时候吧指针移到next[5]=2即从第二位重新比较(根据上述next的定义我们知道第1-1和第4-4是一样的串)
next: 0 0 0 1 2
模式串: a b c a b
文本串:a b c a c a b a b c a b
当发现b和c不相等的时候又从头开始比较
next:
模式串: a b c a b
文本串:a b c a c a b a b c a b
一直暴力向后找 直到:
next:
模式串: a b c a b
文本串:a b c a c a b a b c a b
找到一个匹配,那么好记录下来这个时候的位置 8 又发现指针指向头跳出
再来一个:
next: 0 0 0 1 2 3
模式串:a b c a b c
文本串:a b c a b d a b a b c a b c
当第6位失配的时候直接往后移动next[6]=3位(实现的时候就是指向模式串的指针 i 赋值为next[i]就行)
next: 0 0 0 1 2 3
模式串: a b c a b c
文本串:a b c a b d a b a b c a b c
看到这里你好像理解了KMP的实质,现在再来强调一下:
对于每次失配之后,我都不会从头重新开始枚举,
而是根据我已经得知的数据,从某个特定的位置开始匹配;
而对于模式串的每一位,都有唯一的“特定变化位置”,这个在失配之后的特定变化位置可以帮助我们利用已有的数据不用从头匹配,
从而节约时间。
Part2 KMP算法next数组的构造和代码实现
啊啊啊啊啊,经过冗长的KMP的介绍现在终于搞清楚KMP算法,
其实质上面强调过了,要确保KMP的思想已经看懂了然后来写代码
next数组怎么构造是一个玄学问题,(构造就是求的意思)
一句话解决:用模式串自己匹配自己就行
void getnext()
{
int i=,j=-;next[]=-; //-1表示没有
while (i<lenT) {
if (j==-||T[i]==T[j]) { //没有或者是匹配
i++,j++; //往后移
next[i]=j; //赋值表示1到j和i-j+1到i-1都匹配
}else j=next[j]; //跳
}
}
实在不行就背模板吧。
Part3 KMP算法匹配代码实现
void kmp()
{
int i=,j=; //i指针指向文本串,j指针指向模式串
while (i<lenS&&j<lenT) {
if (j==-||S[i]==T[j]){ //前面没的好跳(j==-1然后++j以后j就为0了又从头)或者这位匹配往后跳1位
i++,j++;
} else j=next[j]; //往前跳找一个前面匹配无误的位置再暴力匹配
if (j==lenT) j=next[j],printf("%d\n",i-lenT+); //找到啦,输出位置
}
}
Part4 KMP算法模板题目和程序设计
P3375 【模板】KMP字符串匹配
题目描述
如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
(如果你不知道这是什么意思也不要问,去百度搜[kmp算法]学习一下就知道了。)
输入输出格式
输入格式:
第一行为一个字符串,即为s1
第二行为一个字符串,即为s2
输出格式:
若干行,每行包含一个整数,表示s2在s1中出现的位置
接下来1行,包括length(s2)个整数,表示前缀数组next[i]的值。
输入输出样例
ABABABC
ABA
1
3
0 0 1
说明
时空限制:1000ms,128M
数据规模:
设s1长度为N,s2长度为M
对于30%的数据:N<=15,M<=5
对于70%的数据:N<=10000,M<=100
对于100%的数据:N<=1000000,M<=1000000
样例说明:
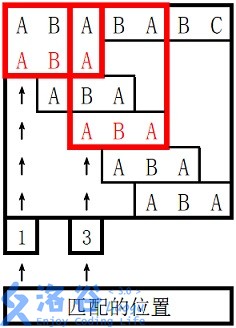
所以两个匹配位置为1和3,输出1、3
代码实现:
# include <bits/stdc++.h>
using namespace std;
const int MSXN=;
char S[MSXN],T[MSXN];
int next[MSXN],lenT,lenS;
void getnext()
{
int i=,j=-;next[]=-;
while (i<lenT) {
if (j==-||T[i]==T[j]) {
i++,j++;
next[i]=j;
}else j=next[j];
}
}
void kmp()
{
int i=,j=;
while (i<lenS&&j<lenT) {
if (j==-||S[i]==T[j]){
i++,j++;
} else j=next[j];
if (j==lenT) j=next[j],printf("%d\n",i-lenT+);
}
}
int main()
{
scanf("%s",S);lenS=strlen(S);
scanf("%s",T);lenT=strlen(T);
getnext();
kmp();
for (int i=;i<=lenT;i++) printf("%d ",next[i]);
return ;
}
【字符串算法3】浅谈KMP算法的更多相关文章
- 浅谈KMP算法及其next[]数组
KMP算法是众多优秀的模式串匹配算法中较早诞生的一个,也是相对最为人所知的一个. 算法实现简单,运行效率高,时间复杂度为O(n+m)(n和m分别为目标串和模式串的长度) 当字符串长度和字符集大小的比值 ...
- 单模式串匹配----浅谈kmp算法
模式串匹配,顾名思义,就是看一个串是否在另一个串中出现,出现了几次,在哪个位置出现: p.s. 模式串是前者,并且,我们称后一个 (也就是被匹配的串)为文本串: 在这篇博客的代码里,s1均为文本串, ...
- 浅谈KMP算法
一.介绍 烤馍片KMP算法是用来处理字符串匹配问题的.比如说给你两个字符串A,B,问B是不是A的子串? 比如,eg就是aeggx的子串 一般讲字符串A称为主串,用来匹配的B串称为模式串 定义n为字符串 ...
- 【文文殿下】浅谈KMP算法next数组与循环节的关系
KMP算法 KMP算法是一种字符串匹配算法,他可以在O(n+m)的时间内求出一个模式串在另一个模式串下出现的次数. KMP算法是利用next数组进行自匹配,然后来进行匹配的. Next数组 Next数 ...
- 浅谈KMP算法——Chemist
很久以前就学过KMP,不过一直没有深入理解只是背代码,今天总结一下KMP算法来加深印象. 一.KMP算法介绍 KMP解决的问题:给你两个字符串A和B(|A|=n,|B|=m,n>m),询问一个字 ...
- 浅谈 KMP 算法
最近在复习数据结构,学到了 KMP 算法这一章,似乎又迷糊了,记得第一次学习这个算法时,老师在课堂上讲得唾沫横飞,十分有激情,而我们在下面听得一脸懵比,啥?这是个啥算法?啥玩意?再去看看书,完全听不懂 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
随机推荐
- C++面向对象模型
1. 基础知识 C++编译器怎样完毕面向对象理论到计算机程序的转化? 换句话:C++编译器是怎样管理类.对象.类和对象之间的关系 详细的说:详细对象调用类写的方法,那,c++编译器是怎样区分,是那个详 ...
- TClientDataSet 提交时提示 Field value Required 但是未提示具体哪个字段。
TClientDataSet 提交时提示 Field value Required 但是未提示具体哪个字段. 这个错误特别麻烦,要使用 midas 控件时,虽然很方便.但是出错了根本找不到原因,特别是 ...
- 2018-3-7 20155317 王新玮 Exp1 PC平台逆向破解(5)M
2018-3-7 20155317 王新玮 Exp1 PC平台逆向破解(5)M 任务要求:手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数. NOP.JNE.JE.JMP.CM ...
- 论FPGA建模,与面向对象编程的相似性
很久没有写FPGA方面的博客了,因为最近一直在弄一个绘图的上位机. 我觉得自己建模思想还不错,但是面向对象思维总是晕的.突然有一天发现,两者居然有这么对共同之处,完全可以相互启发啊.就简单聊下. 1. ...
- MFC如何为程序添加图标
1.找几幅Ico格式的图片,可以在电脑中查找.ico一般都会找到.然后将ico文件放在工程目录下的res文件夹下. 2.点击菜单栏->编辑->添加资源->导入,选择res文件夹中将要 ...
- Linux 学习日记 2 (常用命令 + deb包的安装)
常用命令:以下是一些比较常用的命令,主要是关于安装软件的一些命令 @_@ cd ~/下载(文件名)/ //进入这个文件夹 , ~指的是根目录 cd .. //返回上一级文件夹 sudo apt-get ...
- 华为手机自带浏览器不支持 ES6 语法
原文地址:https://caochangkui.github.io/huawei-es6/ 华为手机自带浏览器对 es6 语法的支持度极差,哪怕最新的荣耀10 手机也有该毛病!所以,移动端项目开发中 ...
- JavaScript快速入门-ECMAScript本地对象(Array)
Array对象 Array对象和python里面的list对象一样,是用来存储多个对象值的对象,且方法和属性基本上类似. 一.属性 lenght 二.方法 1.concat() 用于连接两个或多个 ...
- css怎样去掉多个Img标签之间的间隙
在写css的时候经常会遇到这样的情况,两张宽度加起来是2n的图片,在宽度为2n的容器中放不下,这是因为两张图片之间有一段间隙的缘故,产生这种现象的原因是浏览器把两个img标签之间的空格当成了空白节点. ...
- 学习git 新手。这个写的不错
转自:https://www.cnblogs.com/wupeiqi/p/7295372.html 版本控制 说到版本控制,脑海里总会浮现大学毕业是写毕业论文的场景,你电脑上的毕业论文一定出现过这番景 ...