Hadoop之Flume 记录
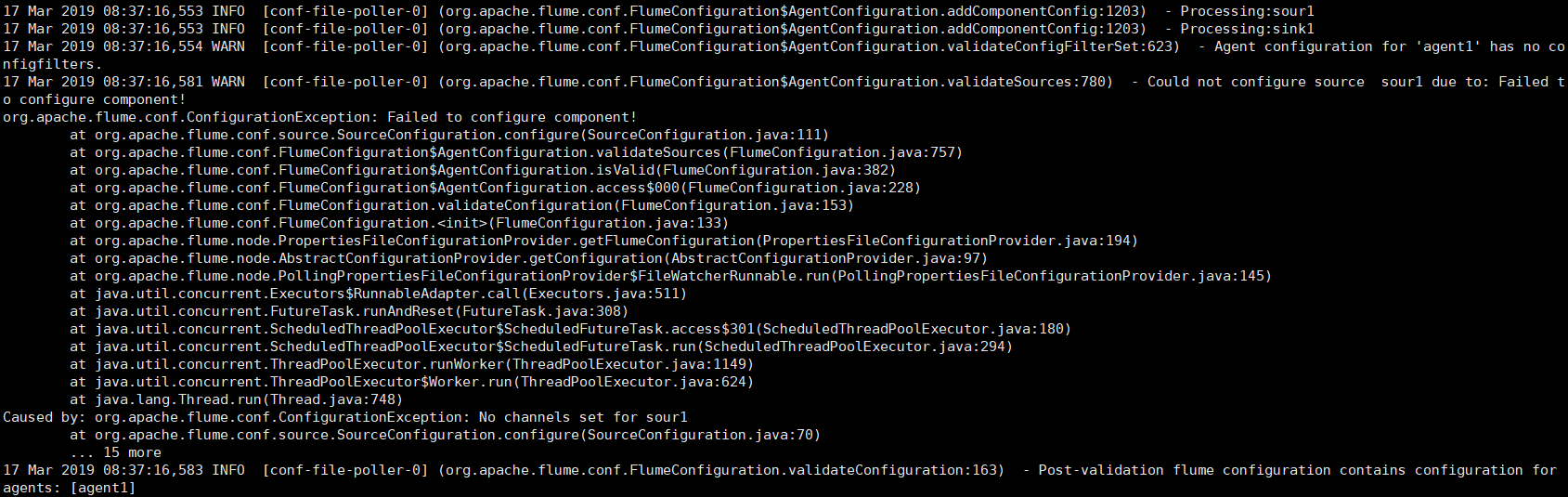
出现这个错误是自己的粗心大意,解决:
在配置flume-conf.properties文件时,source和channel的对应关系是:
myAgentName.sources.mySourceName.channels = myChannelName
myAgentName.sinks.mySinkName.channel = myChannelName
注意其中的后缀,带s和不带s后缀。
这也恰好说明
source可以“流向”多个channel,而sink只能接收一个channel的“流入”。
从channel的角度看:channel既可以接收多个source的“流入”,又可以“流向”多个sink
例如多对多关系:
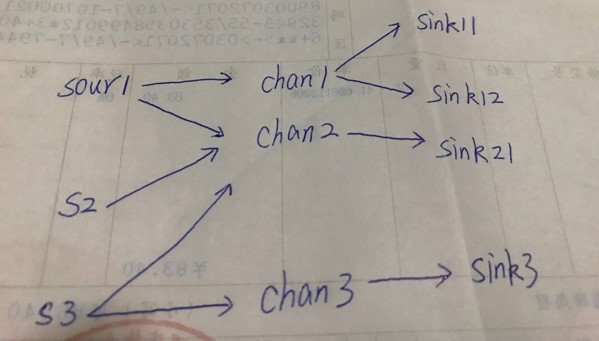
对应的配置如下:
# example.conf: A single-node Flume configuration # Name the components on this agent
agent1.sources=sour1 s2 s3
agent1.sinks=sink1 sink12 sink21 sink3
agent1.channels=chan1 chan2 chan3 # Describe/configure the source
agent1.sources.sour1.type=netcat
agent1.sources.sour1.bind=localhost
agent1.sources.sour1.port=44444 agent1.sources.s2.type=netcat
agent1.sources.s2.bind=localhost
agent1.sources.s2.port=44445 agent1.sources.s3.type=netcat
agent1.sources.s3.bind=localhost
agent1.sources.s3.port=44446 # Describe the sink
agent1.sinks.sink1.type=logger
agent1.sinks.sink12.type=logger
agent1.sinks.sink21.type=logger
agent1.sinks.sink3.type=logger # Use a channel which buffers events in memory
agent1.channels.chan1.type=memory
agent1.channels.chan1.capacity=1000
#agent1.channels.chan1.transactionCapacity=100 agent1.channels.chan2.type=memory
agent1.channels.chan2.capacity=1000 agent1.channels.chan3.type=memory
agent1.channels.chan3.capacity=1000 # Bind the source and sink to the channel
agent1.sources.sour1.channels=chan1 chan2
agent1.sources.s2.channels=chan2
agent1.sources.s3.channels=chan2 chan3 agent1.sinks.sink1.channel=chan1
agent1.sinks.sink12.channel=chan1
agent1.sinks.sink21.channel=chan2
agent1.sinks.sink3.channel=chan3
Hadoop之Flume 记录的更多相关文章
- Hadoop生态圈-Flume的主流source源配置
Hadoop生态圈-Flume的主流source源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Source,想要了解更详细的配置信息请参 ...
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- Hadoop生态圈-Flume的组件之sink处理器
Hadoop生态圈-Flume的组件之sink处理器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二.
- Hadoop生态圈-Flume的组件之拦截器与选择器
Hadoop生态圈-Flume的组件之拦截器与选择器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Interceptors,想要了解更详细 ...
- Hadoop生态圈-Flume的主流Channel源配置
Hadoop生态圈-Flume的主流Channel源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二. 三.
- Hadoop生态圈-Flume的主流Sinks源配置
Hadoop生态圈-Flume的主流Sinks源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Sinks,想要了解更详细的配置信息请参考官 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- Hadoop运维记录系列
http://slaytanic.blog.51cto.com/2057708/1038676 Hadoop运维记录系列(一) Hadoop运维记录系列(二) Hadoop运维记录系列(三) Hado ...
随机推荐
- time、datetime、calendar
time 1. Python中表示时间的方式 l 时间戳 l 格式化的时间字符串 l 元组(struct_time)共九个元素.由于Python的time模块实现主要调用C库,所以各个平台可能 ...
- redis-cli 通过管道 --pipe 快速导入数据到redis中
最近有个需求,需要把五千万条数据批量写入redis中,方法倒是有很多种!效率最高的就是通过redis-cl管道的方式写入 一:先看看命令 cat redis.txt | redis-cli -h 12 ...
- SQLServer版本
- Entity Framework系列教程汇总
翻译自http://www.entityframeworktutorial.net/,使用EF几年时间了,一直没有系统总结过,所以翻译这一系统文章作为总结,由于英语功底有限,翻译的可能有些问题,欢迎指 ...
- Redis源码 - 事件管理
Redis 的事件分类 分类 描述 定时器 线程内定时响应,更新缓存时间.关闭非活动的客户端连接等等 pipe 线程间通信,用于其他线程通知主线程退出aeApiPoll() unixsocket 本地 ...
- D3 learning notes
D3 https://d3js.org/ 数据驱动文档显示, 利用 SVG HTML CSS技术. D3.js is a JavaScript library for manipulating doc ...
- Hexo博客部署-使用github作为保存中转仓库
本篇是在VPS上搭建Hexo静态博客的第一篇博文,写本篇的目的一是纪念一下,二是作为一个部署文档保留. 博客地址 相关描述 VPS环境是在搬瓦工上安装的centos6(x86),1核,512MB,10 ...
- .Net 之 RPC 框架之Hprose(远程调用对象)
实现远程调用对象,跨进程访问对象,可实现分布式 首先给服务端和客户端 nuget Hprose 可使用tcp和http两种调用方式 服务端 using Hprose.Server; using Sys ...
- JavaScript的Document ,Histroy,Location对象
1. Document对象: a) 属性: 名称 描述 alinkColor 设置或检索文档中所有活动链接的颜色 bgColor 设置或检索 Document 对象的背景色 body ...
- 20175306 迭代和JDB调试
迭代和JDB调试 1.使用C(n,m)=C(n-1,m-1)+C(n-1,m)公式进行递归编程实现求组合数C(m,n)的功能 代码展示: public class C { public static ...