Hadoop之Flume 记录
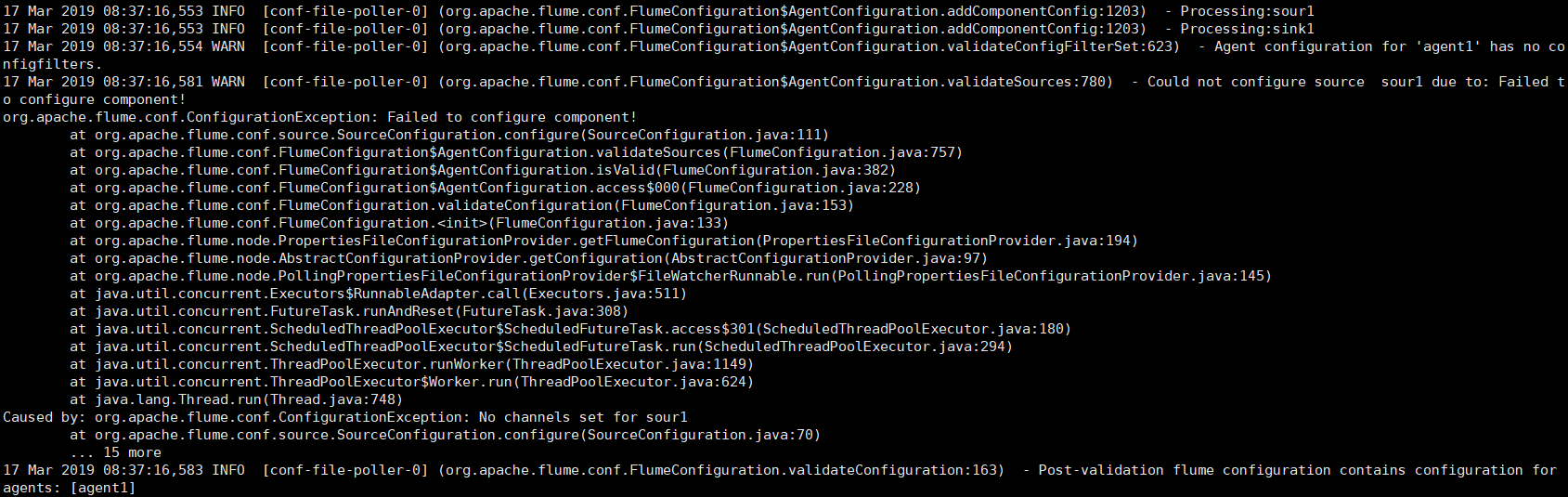
出现这个错误是自己的粗心大意,解决:
在配置flume-conf.properties文件时,source和channel的对应关系是:
myAgentName.sources.mySourceName.channels = myChannelName
myAgentName.sinks.mySinkName.channel = myChannelName
注意其中的后缀,带s和不带s后缀。
这也恰好说明
source可以“流向”多个channel,而sink只能接收一个channel的“流入”。
从channel的角度看:channel既可以接收多个source的“流入”,又可以“流向”多个sink
例如多对多关系:
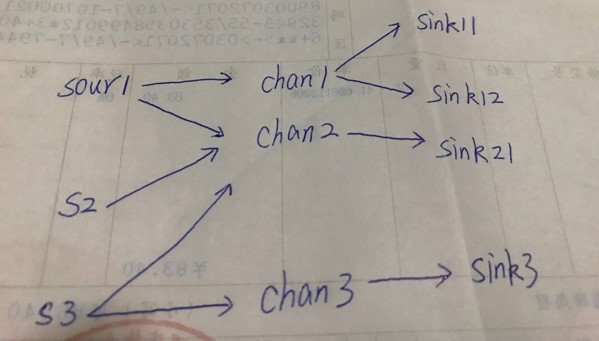
对应的配置如下:
# example.conf: A single-node Flume configuration # Name the components on this agent
agent1.sources=sour1 s2 s3
agent1.sinks=sink1 sink12 sink21 sink3
agent1.channels=chan1 chan2 chan3 # Describe/configure the source
agent1.sources.sour1.type=netcat
agent1.sources.sour1.bind=localhost
agent1.sources.sour1.port=44444 agent1.sources.s2.type=netcat
agent1.sources.s2.bind=localhost
agent1.sources.s2.port=44445 agent1.sources.s3.type=netcat
agent1.sources.s3.bind=localhost
agent1.sources.s3.port=44446 # Describe the sink
agent1.sinks.sink1.type=logger
agent1.sinks.sink12.type=logger
agent1.sinks.sink21.type=logger
agent1.sinks.sink3.type=logger # Use a channel which buffers events in memory
agent1.channels.chan1.type=memory
agent1.channels.chan1.capacity=1000
#agent1.channels.chan1.transactionCapacity=100 agent1.channels.chan2.type=memory
agent1.channels.chan2.capacity=1000 agent1.channels.chan3.type=memory
agent1.channels.chan3.capacity=1000 # Bind the source and sink to the channel
agent1.sources.sour1.channels=chan1 chan2
agent1.sources.s2.channels=chan2
agent1.sources.s3.channels=chan2 chan3 agent1.sinks.sink1.channel=chan1
agent1.sinks.sink12.channel=chan1
agent1.sinks.sink21.channel=chan2
agent1.sinks.sink3.channel=chan3
Hadoop之Flume 记录的更多相关文章
- Hadoop生态圈-Flume的主流source源配置
Hadoop生态圈-Flume的主流source源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Source,想要了解更详细的配置信息请参 ...
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- Hadoop生态圈-Flume的组件之sink处理器
Hadoop生态圈-Flume的组件之sink处理器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二.
- Hadoop生态圈-Flume的组件之拦截器与选择器
Hadoop生态圈-Flume的组件之拦截器与选择器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Interceptors,想要了解更详细 ...
- Hadoop生态圈-Flume的主流Channel源配置
Hadoop生态圈-Flume的主流Channel源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二. 三.
- Hadoop生态圈-Flume的主流Sinks源配置
Hadoop生态圈-Flume的主流Sinks源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Sinks,想要了解更详细的配置信息请参考官 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- Hadoop运维记录系列
http://slaytanic.blog.51cto.com/2057708/1038676 Hadoop运维记录系列(一) Hadoop运维记录系列(二) Hadoop运维记录系列(三) Hado ...
随机推荐
- Spring cloud zuul跨域(二)
使用 CorsFilter 解决ajax跨域问题 直接在zuul的main下面,创建corsFilter就可以了. @SpringBootApplication @EnableZuulProxy ...
- mysql left join 优化
参考 https://www.cnblogs.com/zedosu/p/6555981.html
- 微信小程序之:wepy框架
1.介绍 WePY 是 腾讯 参考了Vue 等框架对原生小程序进行再次封装的框架,更贴近于 MVVM 架构模式, 并支持ES6/7的一些新特性. 2.使用 npm install -g wepy-cl ...
- 一道简单的CTF登录题题解
一.解题感受 这道题50分,在实验吧练习场算比较高分,而且通过率只有14%,比较低的水平. 看到这两个数据,一开始就心生惬意,实在不应该呀! 也是因为心态原因,在发现test.php之后,自以为在SQ ...
- django-crontab实现定时任务
django-crontab实现服务端的定时任务 安装 pip install django-crontab 在Django项目中使用 settings.py INSTALLED_APPS = ( ' ...
- oracle利用job创建一个定时任务,定时调用存储过程
--创建表 create table TESTWP ( ID ), C_DATE DATE ); select * from TESTWP; --2.创建一个sequence create seque ...
- jenkins_jmeter配置
echo "job begin" date export current_time=`date "+%Y%m%d_%H%M%S"` mkdir -p ${WOR ...
- DirectX11--HR宏关于dxerr库的替代方案
DirectX11 With Windows SDK完整目录 欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报. 综述 参考文章:https://blogs. ...
- ./runInstaller: Permission denied
一:问题描述 安装oracle过程中出现 二:解决 /usr/local/Oracle11./database/runInstaller /usr/local/Oracle11./database/i ...
- Visual Studio 使用 Web Deploy 发布远程站点
Ø 简介 本文介绍 Visual Studio 如何使用 Web Deploy发布远程站点,有时候我们开发完某个功能时,需要快速将更改发布至服务器.通常 Visual Studio 可以采用两种方式 ...