R语言统计学习-1简介
一、 统计学习概述
统计学习是指一组用于理解数据和建模的工具集。这些工具可分为有监督或无监督。
1、监督学习:用于根据一个或多个输入预测或估计输出。常用于商业、医学、天体物理学和公共政策等领域。
2、无监督学习:有输入变量,但没有输出变量,可以从这些数据中学习潜在关系和数据结构。
以下简单的用3个数据集来说明。
1、工资数据
我们希望了解雇员的年龄、教育和年份对他的工资之间的联系。下图是对这三个因素的一个分析和统计。
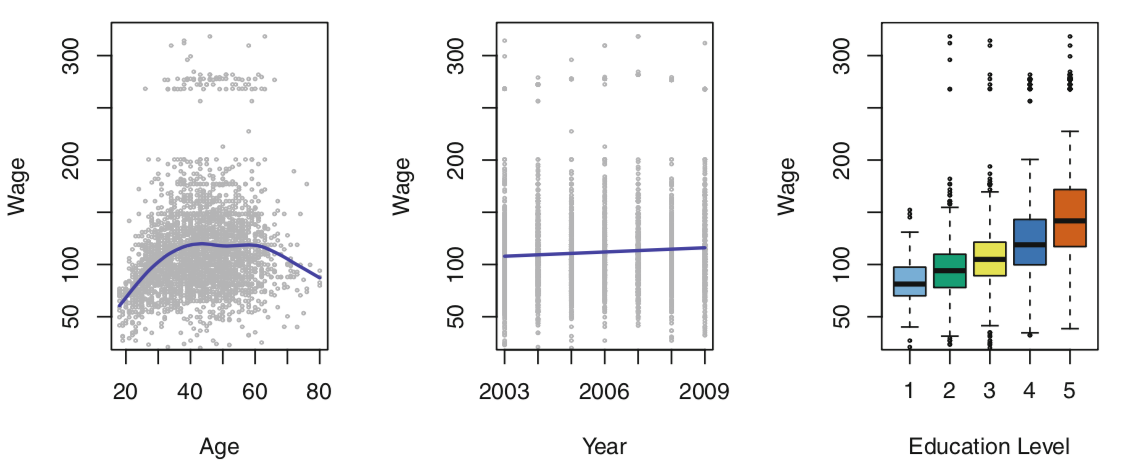
- 左图:工资随着年龄的增长而增加,但在大约60岁之后又下降了。蓝线提供了对该年龄段平均工资的估计,使这一趋势更加明朗化。考虑到雇员的年龄,我们可以用这个曲线来预测他的工资。然而,从图1中可以清楚地看出,这一平均值存在大量的可变性,因此仅仅年龄是不可能准确预测某个人的工资的。
- 中间:工资与年份的关系。工资在2003到2009之间大致以直线(或直线)方式增长,尽管这一增长相对于数据的变化性来说非常轻微。
- 右图:盒状图显示工资与教育程度的关系,1表示最低水平(没有高中文凭)和5的最高水平(高级学位)。平均而言,工资随着教育水平的提高而增加。
综上,对一个人工资的最准确的预测将通过结合他的年龄、教育程度和年份来得到。
2、股票市场数据
工资数据包括预测连续或定量的产出值。这通常被称为回归问题。然而,在某些情况下,我们可能希望预测一个非数值,即分类或定性输出。 股票市场数据的目的是利用过去5天指数的百分比变化来预测某一天的指数是增加还是减少。在这里,统计学习问题并不自动预测数值。相反,它涉及预测某一天的股市表现是上升还是下跌。这就是所谓的分类问题。一个能够准确预测市场走向的模型将非常有用!
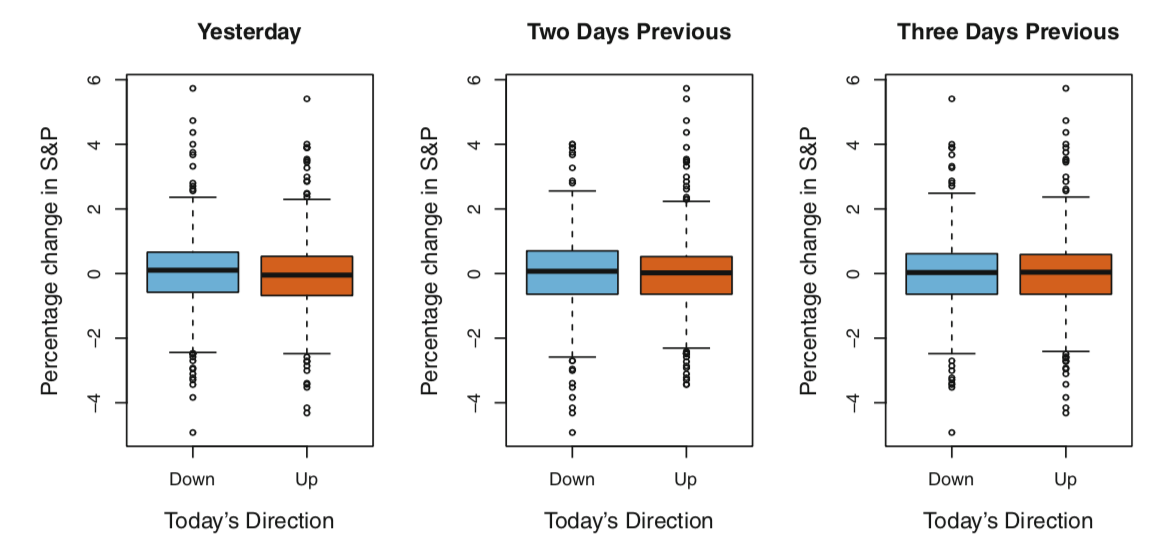
图2的左图显示了在股票指数前一天百分比变化的两盒状图:一个框线表示下一天市场上涨的648天,另一个框线表示下一天市场下跌的602天。这两个块看起来几乎完全相同,这表明,没有一个简单的策略可以用昨天的标准普尔指数来预测今天的收益。其余的面板显示的是今天前2天和3天百分比变化的方框图,同样地显示过去和现在的回报之间几乎没有关联。当然,这种模式的缺乏是可以预料的:在连续几天的收益之间强相关性的情况下,人们可以采用简单的交易策略来从市场获得利润。
有趣的是,数据中有一些微弱的趋势暗示着,至少在这5年期间,大约60%的时间有可能正确地预测市场的移动方向。
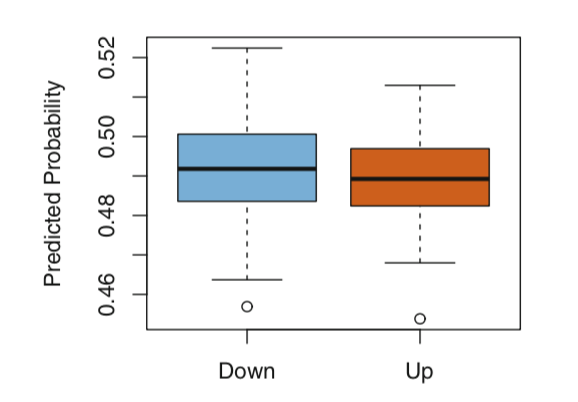
上图采用二次判别分析模型拟合2001-2004年时间段对应的市场数据子集,并利用2005年数据预测股市下跌的概率。平均而言,在市场确实下跌的日子里,预测的下跌概率更高。基于这些结果,能够正确预测市场60%的运动方向。
3、基因表达数据
前两个应用程序用输入和输出变量来说明数据集。一类重要的问题涉及这样的情况:我们只能观察输入变量,而没有相应的输出。例如,在营销环境中,我们可能有许多当前或潜在客户的人口统计信息。我们可能希望通过根据观察到的特征对个人进行分组,从而了解哪些类型的客户彼此相似。这就是所谓的聚类问题。与前面的示例不同,这里我们不尝试预测输出变量。
在NCI60数据集,该数据集由64个癌细胞系的6830个基因表达测量组成。与预测特定的输出变量不同,我们更感兴趣的是根据细胞系的基因表达测量来确定细胞系中是否存在群或簇。这是一个很难解决的问题,部分原因是每个细胞系都有成千上万的基因表达测量,这使得数据难以可视化。
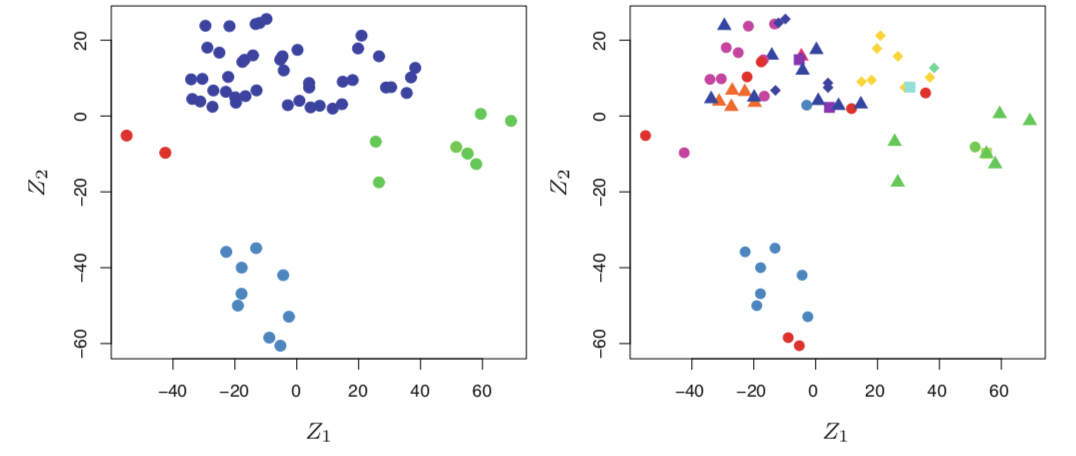
左图通过只使用两个数字(z1和z2)来表示64个细胞中的每一个细胞数据,每个点表示一个细胞,这里显示有四个组。这是数据的前两个主要组成部分,它将每个单元格行的6830个表达式度量汇总为两个数字或维度。虽然这种维度的减少可能导致一些信息丢失,但现在可以直观地检查数据以获取聚类的证据。决定聚类簇的数量通常是一个困难的问题。但是左图显示了至少四组细胞系,我们用单独的颜色表示。我们现在可以检查每个簇中的细胞系在癌症类型上的相似性,以便更好地了解基因表达水平与癌症之间的关系。
右图在显示这个特定的数据集中,结果表明细胞系对应于14种不同类型的癌症。右图和左图相同,但14种癌症类型使用不同的彩色符号显示。有明显的证据表明,具有相同癌症类型的细胞株在这一二维表征中倾向于彼此靠近。此外,尽管癌症信息没有用于生成左图,但所获得的聚类确实与在右图中观察到的某些实际癌症类型有些相似。这为我们的聚类分析的准确性提供了一些独立的验证。
二、统计学习简史
尽管术语统计学习是相当新的,但许多构成该领域基础的概念是很久以前发展起来的。在十九世纪初,勒让德Legendre和高斯Gauss发表了关于最小二乘法的论文,该方法实现了现在被称为线性回归的最早形式。该方法首次成功地应用于天文学问题。线性回归用于预测定量值,如个人工资。为了预测患者的生存或死亡,或股市的涨跌,Fisher在1936年提出了线性判别分析(linear discriminant analysis)。在20世纪40年代,不同的作者提出了另一种方法,逻辑回归。在20世纪70年代早期,Nelder和Wedderburn为一类统计学习方法创造了术语“广义线性模型”,这类方法将线性回归和逻辑回归作为特殊情况包括在内。
到20世纪70年代末,已有更多的数据学习技术。然而,它们几乎都是线性方法,因为拟合非线性关系在当时是不可行的。到20世纪80年代,计算技术终于得到了充分的改进,非线性方法不再是计算上的禁忌。20世纪80年代中期,布雷曼Breiman、弗里德曼Friedman、奥尔森Olshen和斯通Stone引入了分类和回归树,并率先证明了一种方法的详细实际实现的能力,包括模型选择的交叉验证。1986年,黑斯迪和蒂比西拉尼为广义线性模型的一类非线性扩展创造了广义加性模型这一术语,并提供了一个实用的软件实现。
从那时起,在机器学习和其他学科的启发下,统计学习已经成为统计学的一个新的分支领域,其重点是有监督和无监督的建模和预测。近年来,统计学习的进展以功能强大且相对用户友好的软件(如流行的、免费提供的R语言)的可用性不断提高为标志。这有可能继续将该领域从统计学家和计算机科学家使用和开发的一套技术转变为更广泛社区的基本工具包。
三、符号与简单矩阵代数
我们将使用$n$来表示样本中不同数据点或观测的数量,用$p$表示可用于预测的变量数。例如,工资数据为3000人设置了12个变量,因此我们有$n$=3000个观察值和$p$=12个变量(如年、年龄、工资等)。 在一些例子中,$p$可能相当大,比如数千甚至数百万,例如在分析现代生物数据或网络广告数据。
一般来说,我们会让$x_{ij}$代表第$i$次观测的第$j$变量的值,其中$i=1,2,...,n$和$j=1,2,...,p$。在本书中,$i$将用于表示样本或观测点的索引(从1到$n$),$j$将用于变量的索引(从1到$p$)。我们让$X$表示一个$n\times p$矩阵,它的第$\left ( i,j \right )$元素是$x_{ij}$。也就是说(也可以认为$X$是一个具有n行和p列的表格),
$X =\left ( \begin{matrix}
x_{11} &x_{12} &... &x_{1p} \\
x_{21} &x_{22} &... &x_{2p} \\
...& ... & ... &... \\
x_{n1}&x_{n2} &... &x_{np}
\end{matrix} \right )$
有时我们会对$X$的行感兴趣,可以写成$x_{1},x_{2},...,x_{n}$。这里的$x_{i}$是长度$p$的向量,包含用于第$i$次观测的p个变量测量。也就是说,
$x_{i}=\left ( \begin{matrix}
x_{i1}\\
x_{i2}\\
...\\
x_{ip}\end{matrix} \right )$
比如在工资数据中(Wage data)中,$x_{i}$表示长度为12的向量,由第$i$个人的年份、年龄、工资和其他的元素组成。
但在其他时候,我们会对$X$的列感兴趣,这里可以写成$x_{1},x_{2},...,x_{p}$,每个向量的长度都为$n$。
$\mathbf{x}_{j}=\left ( \begin{matrix}
x_{1j}\\
x_{2j}\\
...\\
x_{nj}\end{matrix} \right )$
比如在工资数据中(Wage data)中,$x_{1}$包含$n = 3000$的年份数据。
使用这个公式,可以将$X$写成$X=\left ( \begin{matrix}
x_{1} &x_{2} & ... & x_{p}
\end{matrix} \right )$。
我们使用$y_{i}$表示第$i$个观察点的响应变量,通常希望用于预测,比如工资,因此我们可以写上所有观察点的响应变量:
$\mathbf{y}=\left ( \begin{matrix}
y_{1}\\
y_{2}\\
...\\
y_{n}\end{matrix} \right )$
于是观察点可以由$\left \{ \left ( x_{1},y_{1} \right ),(x_{2},y_{2}),...,(x_{n},y_{n}) \right \}$组成,一般向量可以使用粗体标示。
参考资料:
1、《introduction to statistical learning with R》,G. Casella
R语言统计学习-1简介的更多相关文章
- R语言可视化学习笔记之添加p-value和显著性标记
R语言可视化学习笔记之添加p-value和显著性标记 http://www.jianshu.com/p/b7274afff14f?from=timeline 上篇文章中提了一下如何通过ggpubr ...
- 通过R语言统计考研英语(二)单词出现频率
通过R语言统计考研英语(二)单词出现频率 大家对英语考试并不陌生,首先是背单词,就是所谓的高频词汇.厚厚的一本单词,真的看的头大.最近结合自己刚学的R语言,为年底的考研做准备,想统计一下最近考研英语( ...
- R语言的学习笔记 (持续更新.....)
1. DATE 处理 1.1 日期格式一个是as.Date(XXX) 和strptime(XXX),前者为Date格式,后者为POSIXlt格式 1.2 用法:as.Date(XXX,"%Y ...
- 从零开始系列-R语言基础学习笔记之二 数据结构(二)
在上一篇中我们一起学习了R语言的数据结构第一部分:向量.数组和矩阵,这次我们开始学习R语言的数据结构第二部分:数据框.因子和列表. 一.数据框 类似于二维数组,但不同的列可以有不同的数据类型(每一列内 ...
- 从零开始系列--R语言基础学习笔记之一 环境搭建
R是免费开源的软件,具有强大的数据处理和绘图等功能.下面是R开发环境的搭建过程. 一.点击网址 https://www.r-project.org/ ,进入"The R Project fo ...
- R 语言的学习(一)
1. 基本 "hello world!" > "hello world!" [1] "hello world!" 这在 R 中并不是一 ...
- 吴裕雄--天生自然 R语言开发学习:R语言的安装与配置
下载R语言和开发工具RStudio安装包 先安装R
- R语言数据处理利器——dplyr简介
dplyr是由Hadley Wickham主持开发和维护的一个主要针对数据框快速计算.整合的函数包,同时提供一些常用函数的高速写法以及几个开源数据库的连接.此包是plyr包的深化功能包,其名字中的字母 ...
- R语言可视化学习笔记之添加p-value和显著性标记--转载
https://www.jianshu.com/p/b7274afff14f?from=timeline #先加载包 library(ggpubr) #加载数据集ToothGrowth data(&q ...
随机推荐
- Keepalived脑裂
问题描述:开启防火墙后,Keepalived出现脑裂. 背景架构:两台centos7通过Keepalived实现高可用 问题具体表现形式:两台主机通过ip addr (ip a)查看,发现两台主机都 ...
- c/c++ 拷贝控制 构造函数的问题
拷贝控制 构造函数的问题 问题1:下面①处的代码注释掉后,就编译不过,为什么??? 问题2:但是把②处的也注释掉后,编译就过了,为什么??? 编译错误: 001.cpp: In copy constr ...
- oracle nvl2函数
nvl2(v1, v2, v3) 定义:如果v1为空,返回v3: 不为空,返回v2 nvl2要求v2,v3的类型一致,不一致会发生类型转换.问题:最终返回值类型是v2的类型还是v3的类型? 看题目:n ...
- SQLServer之创建INSTEAD OF INSERT,UPDATE,DELETE触发器
INSTEAD OF触发器工作原理 INSTEAD OF表示并不执行其所定义的操作INSERT,UPDATE ,DELETE,而仅是执行触发器本身,即当对表进行INSERT.UPDATE 或 DELE ...
- LeetCode算法题-Diameter of Binary Tree(Java实现)
这是悦乐书的第257次更新,第270篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第124题(顺位题号是543).给定二叉树,您需要计算树的直径长度. 二叉树的直径是树中 ...
- python selenium2 中的显示等待WebDriverWait与条件判断expected_conditions举例
#coding=utf-8from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium. ...
- VS2017离线安装包[百度云盘](收藏了)
*************************************************************************************************** ...
- RabbitMQ远程执行任务RPC。
如果想发一条命令给远程机器,再把结果返回 这种模式叫RPC:远程过程调用 发送方将发送的消息放在一个queue里,由接收方取. 接收方再把执行结果放在另外一个queue里,由发送方取 实际上,发送方把 ...
- SQL CREATE INDEX 语句
CREATE INDEX 语句用于在表中创建索引. 在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据. 索引 您可以在表中创建索引,以便更加快速高效地查询数据. 用户无法看到索引,它们只 ...
- Mapreduce数据分析实例
数据包 百度网盘 链接:https://pan.baidu.com/s/1v9M3jNdT4vwsqup9N0mGOA提取码:hs9c 复制这段内容后打开百度网盘手机App,操作更方便哦 1. ...