搭建真正的zookeeper集群
搭建zookeeper伪分布式集群
zookeeper是Hadop Ecosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调服务,
提供的功能包括配置维护,域名服务,分布式同步和组服务。
zookeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效,功能稳定的系统提供给用户。
集群节点的主机名分别是guoyansi128 guoyansi129 guoyansi130
搭建过程:
1.下载zookeeper.tar.gz
2.上传至 /user/local/src中
3.解压缩
tar -zxvf zookeeper-3.4..tar.gz
4.复制到上级目录
cp zookeeper-3.4. /usr/local
5.进入配置文件目录
cd /usr/local/zookeeper/conf
6.将zoo_sample.cfg复制成zoo.cfg
cp z00_sample.cfg zoo.cfg
7.修改zoo.cfg
vim zoo.cfg
8.末尾添加如下配置
server.=guoyansi128::
server.=guoyansi129::
server.=guoyansi130::
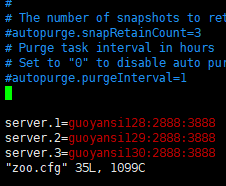
9.保存 esc :wq
10.进入dataDir目录
cd /usr/local/zookeeper/dataDir
11.添加配置文件myid;内容为1 (zookeeper中服务器编号)
vim myid
12.将该安装目录分别复制到另外两台机子上
scp -r /usr/local/zookeeper guoyans129: /usr/local/
scp -r /usr/local/zookeeper guoyans130: /usr/local/
13.分别启动节点中zookeeper
cd /usr/local/zookeeper/bin
./zkServer.sh start
如果启动成功了会有如下提示:

14.查看集群状态
./zkServer.sh status


leader和follower分别表示主从节点。
至少启动两个节点,才会出现leader。
这个leader是有zookeeper选举机制确定的。
zookeeper客户端:
./zkCli.sh -server guoyansi128:2181
ls /zk 查看znode
create /zk "gys"
help 帮助命令
quit 退出客户端。
搭建真正的zookeeper集群的更多相关文章
- ZooKeeper1 利用虚拟机搭建自己的ZooKeeper集群
前言: 前段时间自己参考网上的文章,梳理了一下基于分布式环境部署的业务系统在解决数据一致性问题上的方案,其中有一个方案是使用ZooKeeper,加之在大数据处理中,ZooKeeper确实起 ...
- CentOS7搭建 Hadoop + HBase + Zookeeper集群
摘要: 本文主要介绍搭建Hadoop.HBase.Zookeeper集群环境的搭建 一.基础环境准备 1.下载安装包(均使用当前最新的稳定版本,截止至2017年05月24日) 1)jdk-8u131 ...
- STORM_0001_用vmware拷贝出三个相同的ubuntu搭建小的zookeeper集群
第一次配置zookeeper的集群 因为想运行storm必须搭建集群在自己的电脑上拷贝了自己的ubuntu虚拟机采用的是vmware给虚拟机分配的地址三个机器的配置基本上一样除了myid这个文件看了这 ...
- Kafka+Zookeeper集群搭建
上次介绍了ES集群搭建的方法,希望能帮助大家,这儿我再接着介绍kafka集群,接着上次搭建的效果. 首先我们来简单了解下什么是kafka和zookeeper? Apache kafka 是一个分布式的 ...
- docker-compose搭建zookeeper集群环境 CodingCode
docker-compose搭建zookeeper集群环境 使用docker-compose搭建zookeeper集群环境 zookeeper是一个集群环境,用来管理微服务架构下面的配置管理功能. 这 ...
- Kafka1 利用虚拟机搭建自己的Kafka集群
前言: 上周末自己学习了一下Kafka,参考网上的文章,学习过程中还是比较顺利的,遇到的一些问题最终也都解决了,现在将学习的过程记录与此,供以后自己查阅,如果能帮助到其他人,自然是更好的. ...
- zookeeper集群的安装和配置
Zookeeper的目的是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的系统提供给用户.Zookeeper有两种运行模式,单机模式(Standalone)和集群模式(Distrib ...
- 8.3.ZooKeeper集群安装配置
1.Zookeeper的搭建方式 Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式. 单机模式:Zookeeper只运行在一台服务器上,适合测试环境: 伪集群模式:就是在一台物理机上 ...
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
随机推荐
- JAVA 集合 按照某个字段(依据一定条件)进行分组
由于数据不能够在本地化实现, 无法通过sql语句得到对应的结果,小编只好在业务层处理.通过调用接口得到集合,拿到集合后,通过年来分组,以此来达到对应的Map集合... 在这里小编给大家提供一个封装了一 ...
- 【Spring】文件上传
一:引入所需jar包 // https://mvnrepository.com/artifact/commons-fileupload/commons-fileuploadcompile group: ...
- 关于使用 myeclipse连接MySql的问题
配置Hibernate.cfg.xml测试连接Mysql数据库时老是报错,如下图: 想想这样配置也没有错啊,可是一直测试连接不上.后面上查了一下,需要在连接字符串后面加上?serverTimezone ...
- 在LINUX上查询哪个用户从哪个IP登录,登录时间,执行了什么命令?
在/etc/profile里面加入以下代码 PS1="`whoami`@`hostname`:"'[$PWD]' history USER_IP=`>/dev/null| a ...
- JDBC中执行SQL语句的方式
一.执行DDL.DML语句 DDL.DML分别表示数据库定义语言.数据库操纵语言,操控这两种语言应该使用Statement对象的executeUpdate方法. 代码如下: public static ...
- Spark SQL / Catalyst 内部原理 与 RBO
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/spark/rbo/ 本文所述内容均基于 2018年9月10日 Spark ...
- Dictionary用法
https://www.cgjoy.com/thread-106639-1-1.html 1.新建字典,添加元素 dictionary<string,string>dic=newdict ...
- css flex方法标题左右两边平衡线
<html> <div class="title"> <div class="line"></div> < ...
- 安装并激活pycharm
进入 pycharm官网 https://www.jetbrains.com/pycharm/ 或直接百度pycharm进入官网 点击download now 下载专业版: 点击保存文件: 双击 py ...
- Springboot框架,实现请求数据解密,响应数据加密的功能。
一.简要说明: 在做这个功能的时候,参考了很多文章,也试了用过滤器解决.但总体来说还是很麻烦,所以换了另一种解决方案.直接实现RequestBodyAdvice和ResponseBodyAdvice两 ...