李航《统计学习方法》CH02
CH02 感知机
前言
章节目录
- 感知机模型
- 感知机学习策略
- 数据集的线性可分性
- 感知机学习策略
- 感知机学习算法
- 感知机学习算法
- 感知机学习算法的原始形式
- 算法的收敛性
- 感知机学习算法的对偶形式
导读
感知机是二类分类的线性分类模型。
- $L(w,b)$的经验风险最小化
- 本章中涉及到向量内积,有超平面的概念,也有线性可分数据集的说明,在策略部分有说明损关于失函数的选择的考虑,可以和CH07一起看。
- 本章涉及的两个例子,思考一下为什么$\eta=1$,进而思考一下参数空间,这两个例子设计了相应的测试案例实现, 在后面的内容中也有展示。
- 在收敛性证明那部分提到了偏置合并到权值向量的技巧,这点在LR和SVM中都有应用。
- 第一次涉及Gram Matrix $G=[x_i\cdot x_j]_{N\times N}$
- 感知机的激活函数是符号函数.
- 感知机是神经网络和支持向量机的基础.
- 当我们讨论决策边界的时候, 实际上是在考虑算法的几何解释.
- 关于感知机为什么不能处理异或问题, 可以借助下图理解.
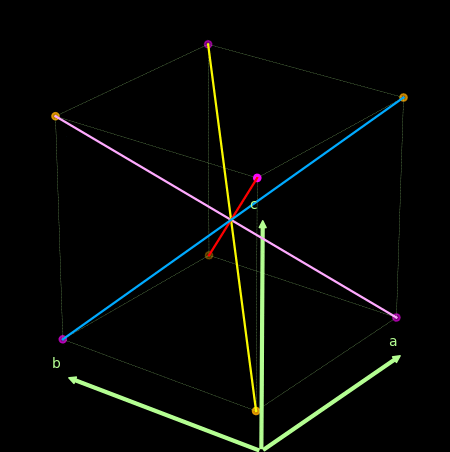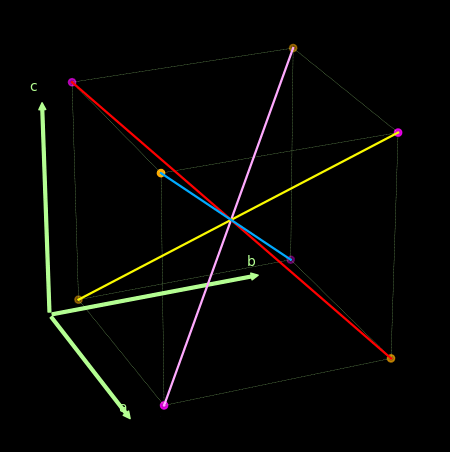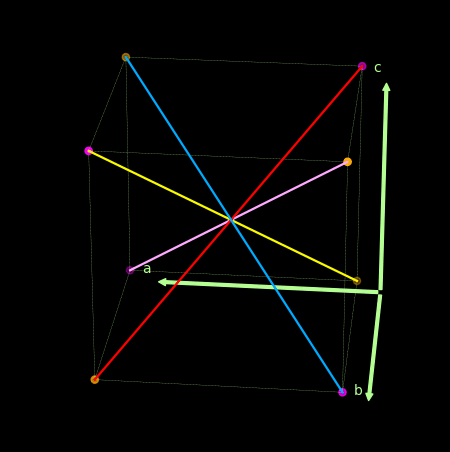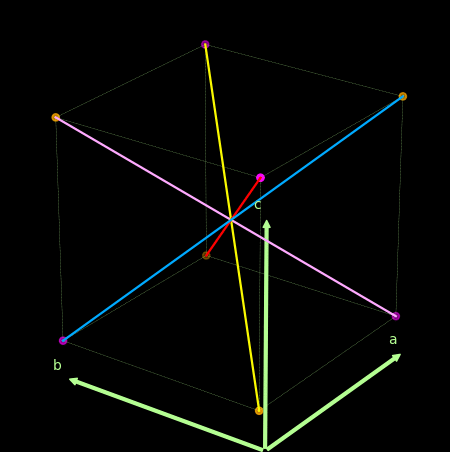
上面紫色和橙色为两类点, 线性的分割超平面应该要垂直于那些红粉和紫色的线.
三要素
模型
输入空间:$\mathcal X \subseteq \bf R^n$
输出空间:$\mathcal Y= {+1,-1} $
决策函数:$f(x)=sign (w\cdot x+b)$
策略
确定学习策略就是定义**(经验)**损失函数并将损失函数最小化。
注意这里提到了经验,所以学习是base在训练数据集上的操作
损失函数选择
损失函数的一个自然选择是误分类点的总数,但是,这样的损失函数不是参数$w,b$的连续可导函数,不易优化
损失函数的另一个选择是误分类点到超平面$S$的总距离,这是感知机所采用的
感知机学习的经验风险函数(损失函数)定义为误分类点到超平面S的总距离 $$ L(w,b)=-\sum_{x_i\in M}y_i(w\cdot x_i+b) $$ 其中$M$是误分类点的集合
给定训练数据集$T$,损失函数$L(w,b)$是$w$和$b$的连续可导函数.
算法
原始形式
输入:$T={(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)}\ x_i\in \cal X=\bf R^n\mit , y_i\in \cal Y ={-1,+1}, i=1,2,\dots,N; 0<\eta\leqslant 1$
输出:$w,b;f(x)=sign(w\cdot x+b)$
选取初值$w_0,b_0$
训练集中选取数据$(x_i,y_i)$
如果$y_i(w\cdot x_i+b)\leqslant 0$ $$ w\leftarrow w+\eta y_ix_i \\ b\leftarrow b+\eta y_i $$
转至(2),直至训练集中没有误分类点
注意这个原始形式中的迭代公式,可以对$x$补1,将$w$和$b$合并在一起.
对偶形式
输入:$T={(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)}\ x_i\in \cal X=\bf R^n\mit , y_i\in \cal Y ={-1,+1}, i=1,2,\dots,N; \ \ 0<\eta\leqslant 1$
输出: $$ \alpha ,b; f(x)=sign\left(\sum_{j=1}^N\alpha_jy_jx_j\cdot x+b\right)\nonumber\ \alpha=(\alpha_1,\alpha_2,\cdots,\alpha_N)^T $$
$\alpha \leftarrow 0,b\leftarrow 0$
训练集中选取数据$(x_i,y_i)$
如果$y_i\left(\sum_{j=1}^N\alpha_jy_jx_j\cdot x+b\right) \leqslant 0$ $$ \alpha_i\leftarrow \alpha_i+\eta \nonumber\ \\ b\leftarrow b+\eta y_i $$
转至(2),直至训练集中没有误分类点
Gram matrix
对偶形式中,训练实例仅以内积的形式出现。
为了方便可预先将训练集中的实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是所谓的Gram矩阵 $$ G=[x_i\cdot x_j]_{N\times N} \nonumber $$

例子
例2.1
这个例子里面$\eta = 1$
感知机学习算法由于采用不同的初值或选取不同的误分类点,解可以不同。
另外,在这个例子之后,证明算法收敛性的部分,有一段为了便于叙述与推导的描述,提到了将偏置并入权重向量的方法,这个在涉及到内积计算的时候可能都可以用到,可以扩展阅读CH06,CH07部分的内容描述。
例2.2
这个例子也简单,注意两点
- $\eta=1$
- $\alpha_i\leftarrow \alpha_i+1, b\leftarrow b+y_i$
以上:
- 为什么$\eta$选了1,这样得到的值数量级是1
- 这个表达式中用到了上面的$\eta=1$这个结果,已经做了简化
所以,这里可以体会下,调整学习率$\eta $的作用。学习率决定了参数空间。
Logic_01
经常被举例子的异或问题^1,用感知机不能实现,因为对应的数据非线性可分。但是可以用感知机实现其他逻辑运算,也就是提供对应的逻辑运算的数据,然后学习模型。
这个例子的数据是二元的,其中NOT运算只针对输入向量的第一个维度
Logic_02
这个例子的数据是三元的.
MNIST_01
这个选择两类数据进行区分,不同的选择应该得到的结果会有一定差异,数据不上传了,在sklearn里面有相应的数据,直接引用了,注意测试案例里面用的是01,相对来讲好区分一些。
李航《统计学习方法》CH02的更多相关文章
- 李航统计学习方法——算法2k近邻法
2.4.1 构造kd树 给定一个二维空间数据集,T={(2,3),(5,4),(9,6)(4,7),(8,1),(7,2)} ,构造的kd树见下图 2.4.2 kd树最近邻搜索算法 三.实现算法 下面 ...
- 李航-统计学习方法-笔记-3:KNN
KNN算法 基本模型:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例.这k个实例的多数属于某个类,就把输入实例分为这个类. KNN没有显式的学习过程. KNN使用的模型 ...
- 李航统计学习方法(第二版)(六):k 近邻算法实现(kd树(kd tree)方法)
1. kd树简介 构造kd树的方法如下:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行切分,生成子结点.在超矩形区域(结点)上选择一个坐标轴和 ...
- 李航统计学习方法(第二版)(五):k 近邻算法简介
1 简介 k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类.k近邻法假设给定一个训练数据集,其中的实例类别已定.分类时,对新的实例,根据其k个最近邻的训练实例的类别,通 ...
- 李航统计学习方法(第二版)(十):决策树CART算法
1 简介 1.1 介绍 1.2 生成步骤 CART树算法由以下两步组成:(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;(2)决策树剪枝:用验证数据集对己生成的树进行剪枝并选择最优子 ...
- Adaboost算法的一个简单实现——基于《统计学习方法(李航)》第八章
最近阅读了李航的<统计学习方法(第二版)>,对AdaBoost算法进行了学习. 在第八章的8.1.3小节中,举了一个具体的算法计算实例.美中不足的是书上只给出了数值解,这里用代码将它实现一 ...
- 统计学习方法学习(四)--KNN及kd树的java实现
K近邻法 1基本概念 K近邻法,是一种基本分类和回归规则.根据已有的训练数据集(含有标签),对于新的实例,根据其最近的k个近邻的类别,通过多数表决的方式进行预测. 2模型相关 2.1 距离的度量方式 ...
- 统计学习方法(李航)朴素贝叶斯python实现
朴素贝叶斯法 首先训练朴素贝叶斯模型,对应算法4.1(1),分别计算先验概率及条件概率,分别存在字典priorP和condP中(初始化函数中定义).其中,计算一个向量各元素频率的操作反复出现,定义为c ...
- 李航《统计学习方法》CH01
CH01 统计学方法概论 前言 章节目录 统计学习 监督学习 基本概念 问题的形式化 统计学习三要素 模型 策略 算法 模型评估与模型选择 训练误差与测试误差 过拟合与模型选择 正则化与交叉验证 正则 ...
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
随机推荐
- phpStudy环境安装SSL证书教程
第一步:修改apache目录下的httpd.conf配置文件(D:\phpStudy\PHPTutorial\Apache\conf\ ) #LoadModule ssl_module modules ...
- 【转载】Sikuli安装及使用——基于图像识别自动化工具
一.Sikuli能做什么? 用屏幕截图的方式,用截出来的图形元素组合出神奇的程序实现自动化安装.卸载软件,自动化测试(Windows.mac应用测试,Web测试,移动端测试) 二.安装Sikuli 预 ...
- Python 较为完善的猜数字游戏
import random def guess_bot(): bot = random.randint(1, 100) # time = int(input("你觉得能猜对需要的次数:&qu ...
- vue前端面试题知识点整理
vue前端面试题知识点整理 1. 说一下Vue的双向绑定数据的原理 vue 实现数据双向绑定主要是:采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty() 来劫 ...
- 什么是Referer?Referer的作用?空Referer是怎么回事?
什么是Referer? Referer是 HTTP请求header 的一部分,当浏览器(或者模拟浏览器行为)向web 服务器发送请求的时候,头信息里有包含 Referer.比如我在www.sojson ...
- python函数部分----函数初识
0.来源http://www.cnblogs.com/jin-xin/articles/8241942.html 1.return 返回0个返回值,返回一个返回值.返回多个返回值 None.如果一个变 ...
- [darknet]查看错误结果 sight of wrong
import os import numpy import cv2 bad_label_file = open("bad_valid.list",'r') names = [] f ...
- mfc双缓冲绘图
1.要求 在界面加载本地图片并显示,每过100ms改变一张图片显示 2.现象 通过定时器控制CImage,Load,Draw,Destroy,会非常的卡顿.因为Load图片时,会是非常大的数据[所有C ...
- <抽象工厂>比<工厂方法>多了啥
前言:仅当复习讨论,写得不好,多多指教! 上一篇文章<比多了啥>介绍了简单工厂模式和工厂方法模式.本篇文章则讲最后一个工厂----抽象工厂.如果对工厂方法比较模糊的,可以返回上一篇文章复习 ...
- 论文阅读: Siam FC
一.研究动机 一方面传统算法设计的跟踪模型过于简单,另一方面深度学习方法很难达到实时效果然而现实场景中的应用对速度要求较高. "shallow method"(HCFT)没有很好地 ...