SQL Server中通过设置非聚集索引(Non-Clustered index)来达到性能优化的目的
首先我们一下,在SQL Server 2014 Management Studio中,如何为一张表设置Non-Clustered index
具体可以参考 https://docs.microsoft.com/en-us/sql/relational-databases/indexes/create-unique-indexes
在SQL Server Management Studio中,点击表,右键选择"Design". 然后在菜单栏中选择"Table Designer" => "Indexes/Keys"
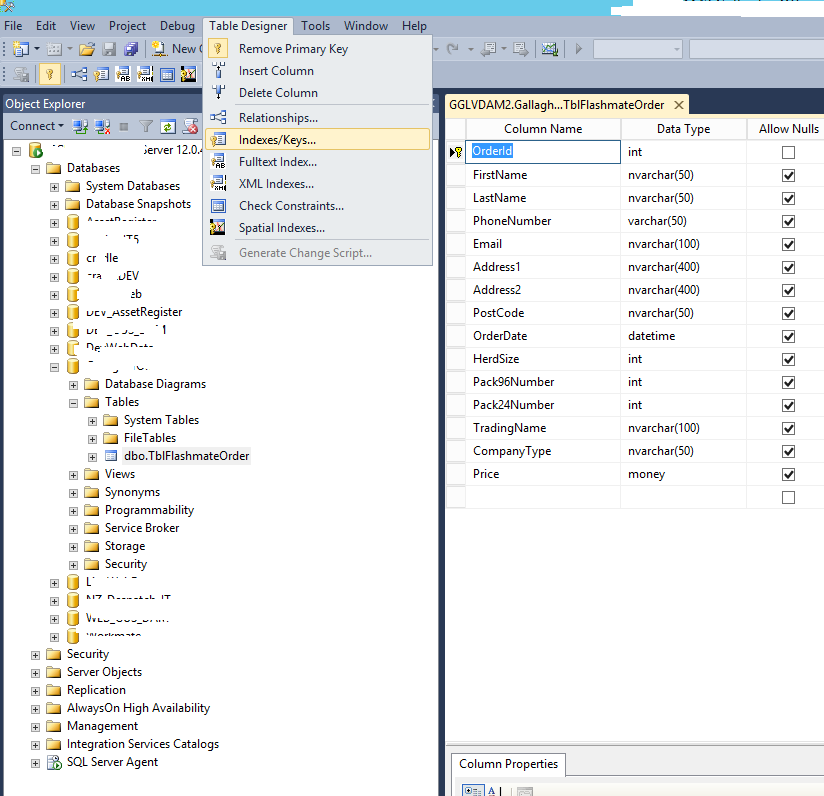
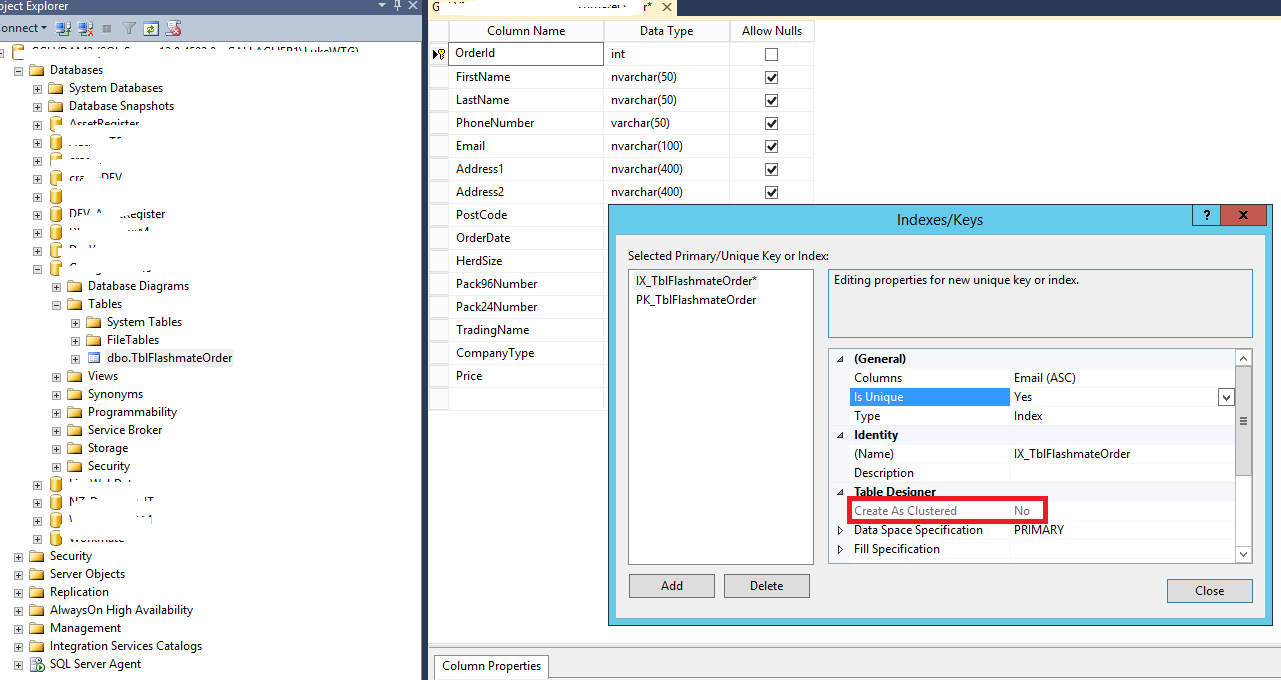
Click "Close" and "Save" button under the menu. Referesh the table and you can see the index folder under the table:
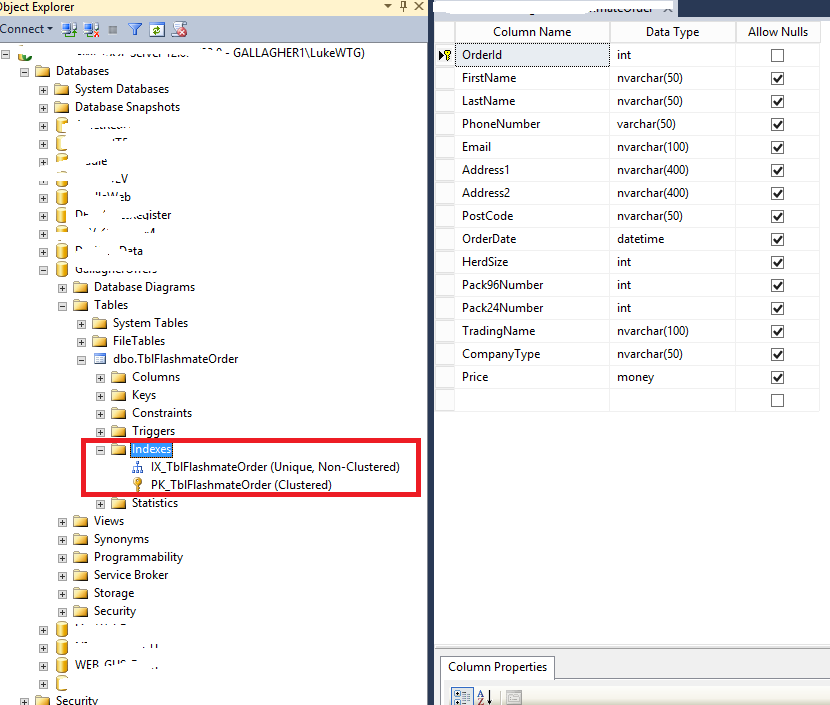
在上图中,右键点击“Indexes” ,可以新建 Non-Clustered Index.
在一个表需要Group by 一些字段 来计算一些数值字段的时候, 我们通常可以把Group by 的那些字段设置为Non-Clustered Index, 把那些需要计算的数值字段设置为Index中的包含列。 如下图:
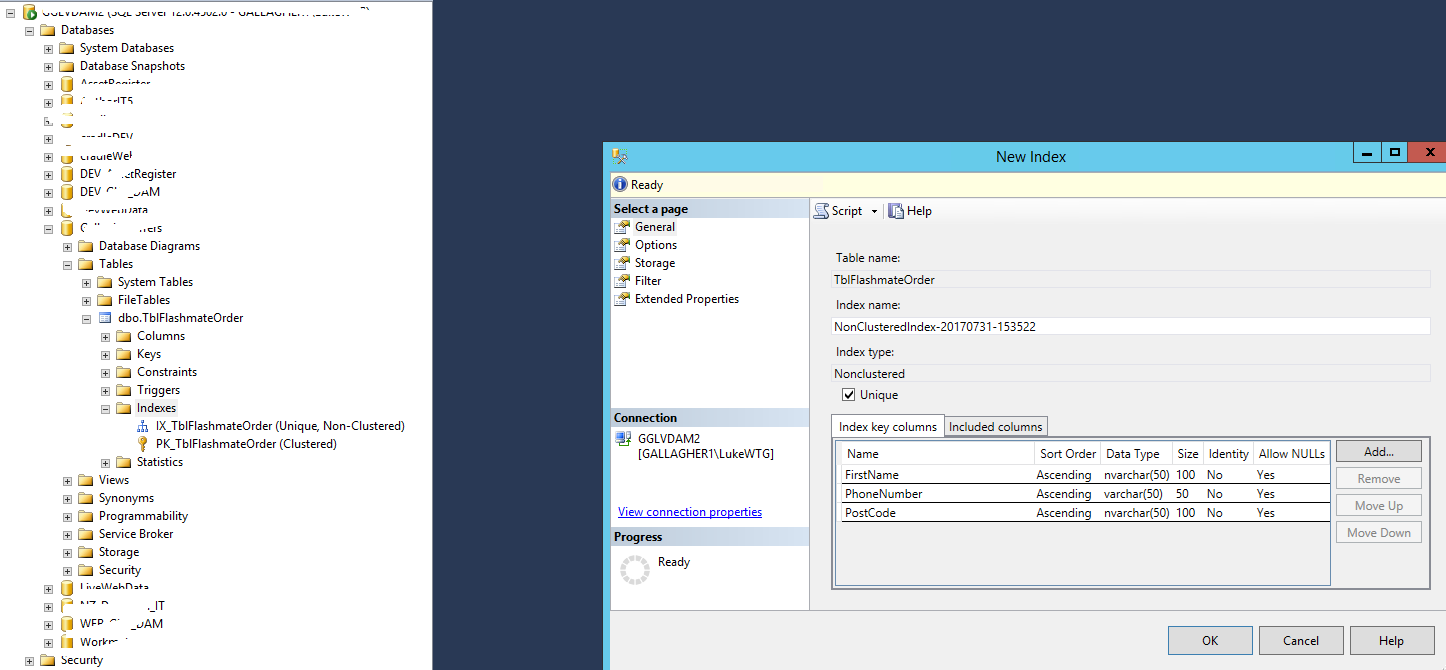
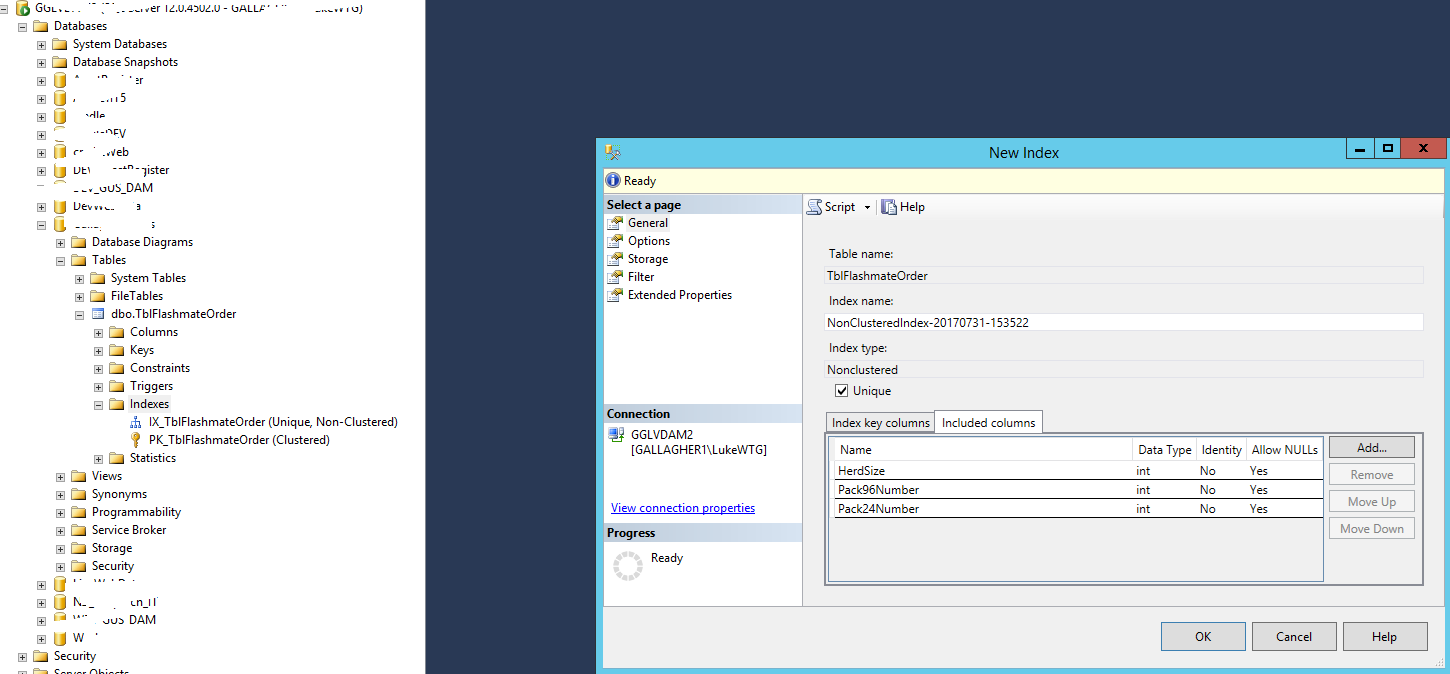
这样的话,可以大大提高这个SQL语句的性能(Performance)
请参考文章 http://www.cnblogs.com/emrys5/p/sqlserver_index.html
SQL Server中通过设置非聚集索引(Non-Clustered index)来达到性能优化的目的的更多相关文章
- sql server临时删除/禁用非聚集索引并重新创建加回/启用的简便编程方法研究对比
前言: 由于新型冠状病毒影响,博主(zhang502219048)在2020年1月份从广东广州工作地回到广东揭阳产业转移工业园磐东街道(镇里有阳美亚洲玉都.五金之乡,素以“金玉”闻名)老家后,还没过去 ...
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
- SQL SERVER 读书笔记:非聚集索引
对于有聚集索引的表,数据存储在聚集索引的叶子节点,而非聚集索引则存储 索引键值 和 聚集索引键值.对于非聚集索引,如果查找的字段没有包含在索引键值,则还要根据聚集索引键值来查找详细数据,此谓 Book ...
- SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析
在SQL SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table Scan).聚集索引表走聚集索引扫描(Clustered Index ...
- SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析 (转载)
在SQL SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table Scan).聚集索引表走聚集索引扫描(Clustered Index ...
- SQL Server中如何设置对列的权限
一.方式一:使用视图 将需要限制用户只能看到特定的几个列.设置成一个视图,然后对这个视图进行权限控制 二.方式二:使用GRANT语句 1.授予相关列的查询权限(SELECT) 在数据库db1中,登录名 ...
- Sql Server中的表访问方式Table Scan, Index Scan, Index Seek
1.oracle中的表访问方式 在oracle中有表访问方式的说法,访问表中的数据主要通过三种方式进行访问: 全表扫描(full table scan),直接访问数据页,查找满足条件的数据 通过row ...
- 转:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek
0.参考文献 Table Scan, Index Scan, Index Seek SQL SERVER – Index Seek vs. Index Scan – Diffefence and Us ...
- SQL Server中的聚集索引(clustered index) 和 非聚集索引 (non-clustered index)
本文转载自 http://blog.csdn.net/ak913/article/details/8026743 面试时经常问到的问题: 1. 什么是聚合索引(clustered index) / ...
随机推荐
- 剑指offer之 O(1)时间删除链表结点
问题描述:给定单向链表的头指针和一个结点指针,定义一个函数在O(1)时间删除该结点. package Problem13; /* * 问题描述:给定单向链表的头指针和一个结点指针,定义一个函数在O(1 ...
- 使用jQuery为博客生成目录
这段代码展示了如何为div#content中的内容生成目录,也无非是对h系列标记进行解析.当然,也早有一些人实现了.1. [代码][HTML]代码 <html> <h ...
- SSAS——基础
一.Analysis Services Analysis Services是用于决策支持和BI解决方案的数据引擎.它提供报表和客户端中使用的分析数据. 它可在多用途数据模型中创建高性能查询结构,业务逻 ...
- HashOperations
存储格式:Key=>(Map<HK,HV>) 1.put(H key, HK hashKey, HV value) putAll(H key, java.util.Map<? ...
- GridView设置多个DatakeyNames
1.aspx页面GridView直接绑定DataKeyNames aspx设置: <asp:GridView ID="grvGrid" runat="server& ...
- 十一 Django框架,Session
Django中默认支持Session,其内部提供了5种类型的Session供开发者使用: 1.数据库(默认)2.缓存3.文件4.缓存+数据库5.加密cookie 1.数据库Session,保存在数据库 ...
- NSArray用法
//类方法初始化一个数组对象 [array count] : 得到这个数组对象的长度. [array objectAtIndex index]: 传入数组的索引(index) 得到数据对象. [arr ...
- android获取时间差的方法
本文实例讲述了android获取时间差的方法.分享给大家供大家参考.具体分析如下: 有些时候我们需要获取当前时间和某个时间之间的时间差,这时如何获取呢? 1. 引用如下命名空间: import jav ...
- Poj 2304 Combination Lock(模拟顺、逆时钟开组合锁)
一.题目大意 模拟一个开组合的密码锁过程.就像电影你开保险箱一样,左转几圈右转几圈的就搞定了.这个牌子的锁呢,也有它独特的转法.这个锁呢,有一个转盘,刻度为0~39.在正北方向上有一个刻度指针.它的密 ...
- 使用cmd命令行方式登录ftp上传下载数据
部分用户在使用ftp工具登录空间上传下载过程中经常会遇到各种问题,如主动模式,被动模式,以及其他导致无法登陆ftp .上传数据.下载数据的问题,这时候不妨使用一下命令行方式.命令行下可以避免很多由于f ...