大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)
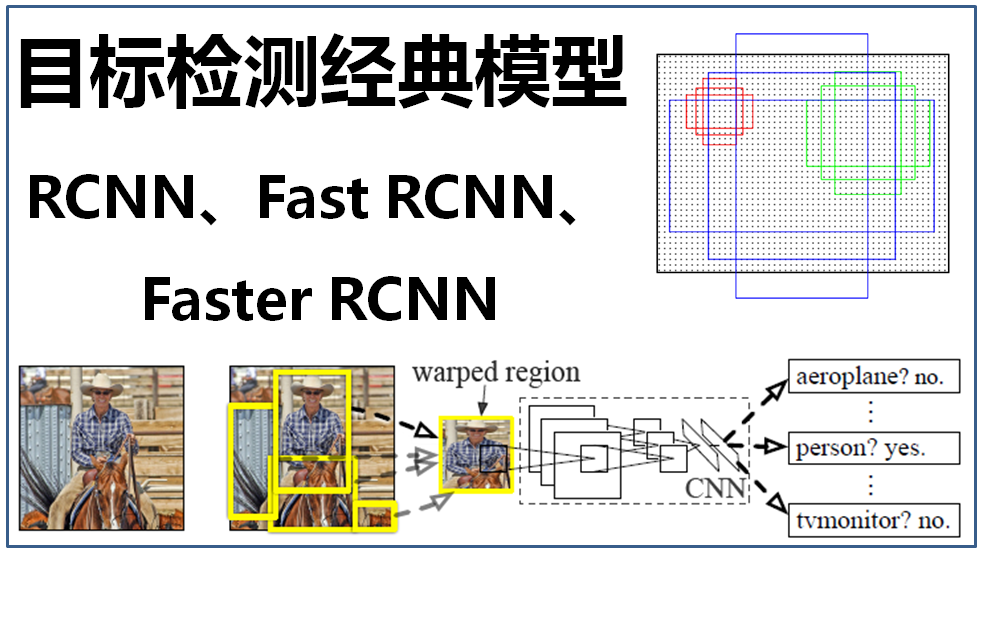
目标检测是深度学习的一个重要应用,就是在图片中要将里面的物体识别出来,并标出物体的位置,一般需要经过两个步骤:
1、分类,识别物体是什么
2、定位,找出物体在哪里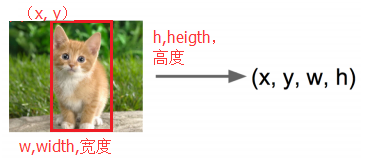
除了对单个物体进行检测,还要能支持对多个物体进行检测,如下图所示: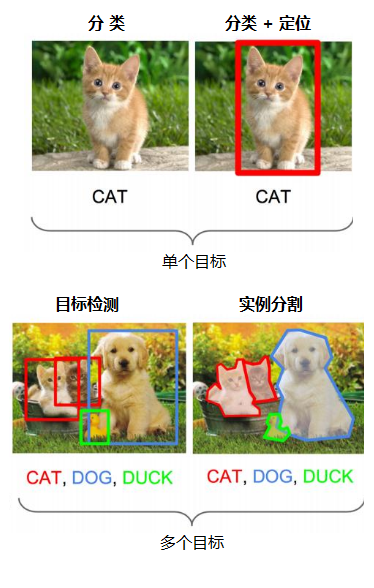
这个问题并不是那么容易解决,由于物体的尺寸变化范围很大、摆放角度多变、姿态不定,而且物体有很多种类别,可以在图片中出现多种物体、出现在任意位置。因此,目标检测是一个比较复杂的问题。
最直接的方法便是构建一个深度神经网络,将图像和标注位置作为样本输入,然后经过CNN网络,再通过一个分类头(Classification head)的全连接层识别是什么物体,通过一个回归头(Regression head)的全连接层回归计算位置,如下图所示: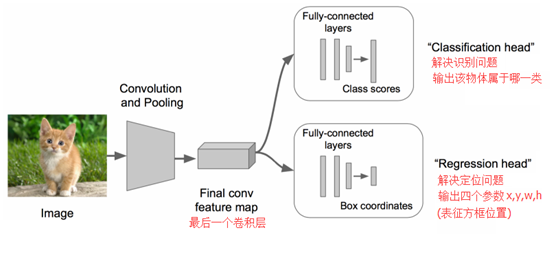
但“回归”不好做,计算量太大、收敛时间太长,应该想办法转为“分类”,这时容易想到套框的思路,即取不同大小的“框”,让框出现在不同的位置,计算出这个框的得分,然后取得分最高的那个框作为预测结果,如下图所示:
根据上面比较出来的得分高低,选择了右下角的黑框作为目标位置的预测。
但问题是:框要取多大才合适?太小,物体识别不完整;太大,识别结果多了很多其它信息。那怎么办?那就各种大小的框都取来计算吧。
如下图所示(要识别一只熊),用各种大小的框在图片中进行反复截取,输入到CNN中识别计算得分,最终确定出目标类别和位置。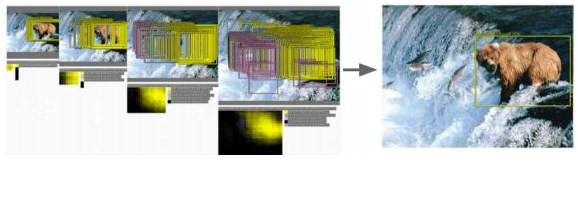
这种方法效率很低,实在太耗时了。那有没有高效的目标检测方法呢?
一、R-CNN 横空出世
R-CNN(Region CNN,区域卷积神经网络)可以说是利用深度学习进行目标检测的开山之作,作者Ross Girshick多次在PASCAL VOC的目标检测竞赛中折桂,2010年更是带领团队获得了终身成就奖,如今就职于Facebook的人工智能实验室(FAIR)。
R-CNN算法的流程如下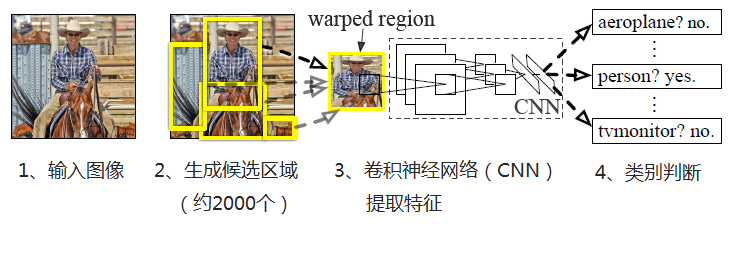
1、输入图像
2、每张图像生成1K~2K个候选区域
3、对每个候选区域,使用深度网络提取特征(AlextNet、VGG等CNN都可以)
4、将特征送入每一类的SVM 分类器,判别是否属于该类
5、使用回归器精细修正候选框位置
下面展开进行介绍
1、生成候选区域
使用Selective Search(选择性搜索)方法对一张图像生成约2000-3000个候选区域,基本思路如下:
(1)使用一种过分割手段,将图像分割成小区域
(2)查看现有小区域,合并可能性最高的两个区域,重复直到整张图像合并成一个区域位置。优先合并以下区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
- 合并后,总面积在其BBOX中所占比例大的
在合并时须保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其它小区域,保证合并后形状规则。
(3)输出所有曾经存在过的区域,即所谓候选区域
2、特征提取
使用深度网络提取特征之前,首先把候选区域归一化成同一尺寸227×227。
使用CNN模型进行训练,例如AlexNet,一般会略作简化,如下图: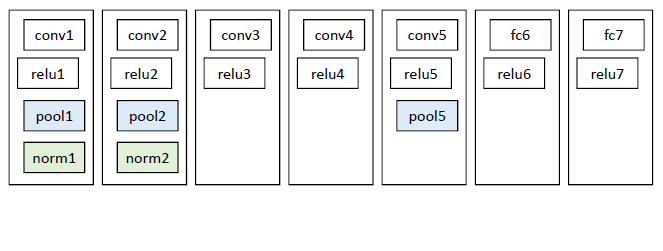
3、类别判断
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络(如上图的AlexNet)输出的4096维特征,输出是否属于此类。
4、位置精修
目标检测的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小,故需要一个位置精修步骤,对于每一个类,训练一个线性回归模型去判定这个框是否框得完美,如下图:
R-CNN将深度学习引入检测领域后,一举将PASCAL VOC上的检测率从35.1%提升到53.7%。
二、Fast R-CNN大幅提速
继2014年的R-CNN推出之后,Ross Girshick在2015年推出Fast R-CNN,构思精巧,流程更为紧凑,大幅提升了目标检测的速度。
Fast R-CNN和R-CNN相比,训练时间从84小时减少到9.5小时,测试时间从47秒减少到0.32秒,并且在PASCAL VOC 2007上测试的准确率相差无几,约在66%-67%之间。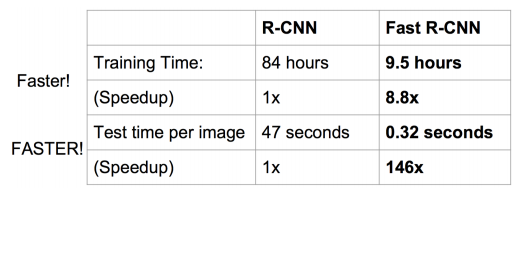
Fast R-CNN主要解决R-CNN的以下问题:
1、训练、测试时速度慢
R-CNN的一张图像内候选框之间存在大量重叠,提取特征操作冗余。而Fast R-CNN将整张图像归一化后直接送入深度网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
2、训练所需空间大
R-CNN中独立的分类器和回归器需要大量特征作为训练样本。Fast R-CNN把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
下面进行详细介绍
1、在特征提取阶段,通过CNN(如AlexNet)中的conv、pooling、relu等操作都不需要固定大小尺寸的输入,因此,在原始图片上执行这些操作后,输入图片尺寸不同将会导致得到的feature map(特征图)尺寸也不同,这样就不能直接接到一个全连接层进行分类。
在Fast R-CNN中,作者提出了一个叫做ROI Pooling的网络层,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量。ROI Pooling层将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。这样虽然输入的图片尺寸不同,得到的feature map(特征图)尺寸也不同,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,就可再通过正常的softmax进行类型识别。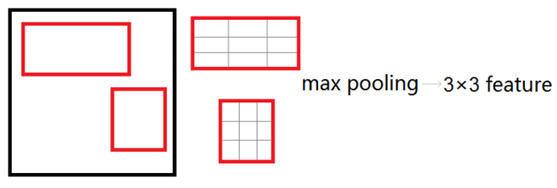
2、在分类回归阶段,在R-CNN中,先生成候选框,然后再通过CNN提取特征,之后再用SVM分类,最后再做回归得到具体位置(bbox regression)。而在Fast R-CNN中,作者巧妙的把最后的bbox regression也放进了神经网络内部,与区域分类合并成为了一个multi-task模型,如下图所示: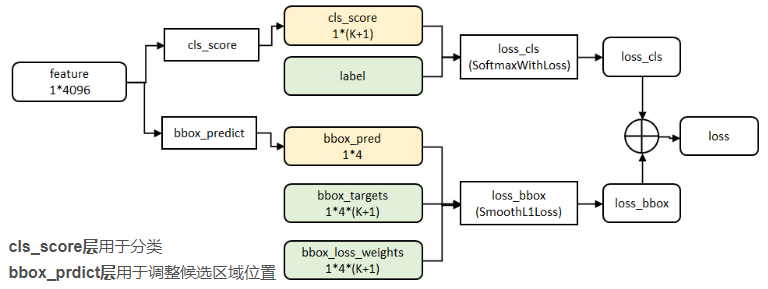
实验表明,这两个任务能够共享卷积特征,并且相互促进。
Fast R-CNN很重要的一个贡献是成功地让人们看到了Region Proposal+CNN(候选区域+卷积神经网络)这一框架实时检测的希望,原来多类检测真的可以在保证准确率的同时提升处理速度。
三、Faster R-CNN更快更强
继2014年推出R-CNN,2015年推出Fast R-CNN之后,目标检测界的领军人物Ross Girshick团队在2015年又推出一力作:Faster R-CNN,使简单网络目标检测速度达到17fps,在PASCAL VOC上准确率为59.9%,复杂网络达到5fps,准确率78.8%。
在Fast R-CNN还存在着瓶颈问题:Selective Search(选择性搜索)。要找出所有的候选框,这个也非常耗时。那我们有没有一个更加高效的方法来求出这些候选框呢?
在Faster R-CNN中加入一个提取边缘的神经网络,也就说找候选框的工作也交给神经网络来做了。这样,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。如下图所示: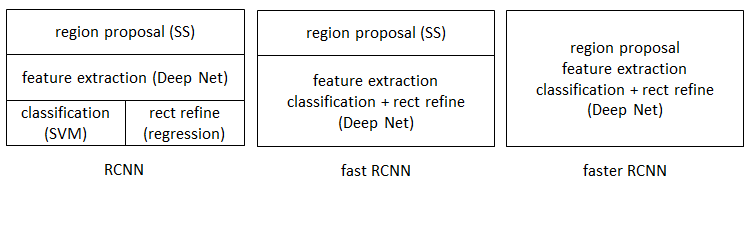
Faster R-CNN可以简单地看成是“区域生成网络+Fast R-CNN”的模型,用区域生成网络(Region Proposal Network,简称RPN)来代替Fast R-CNN中的Selective Search(选择性搜索)方法。
如下图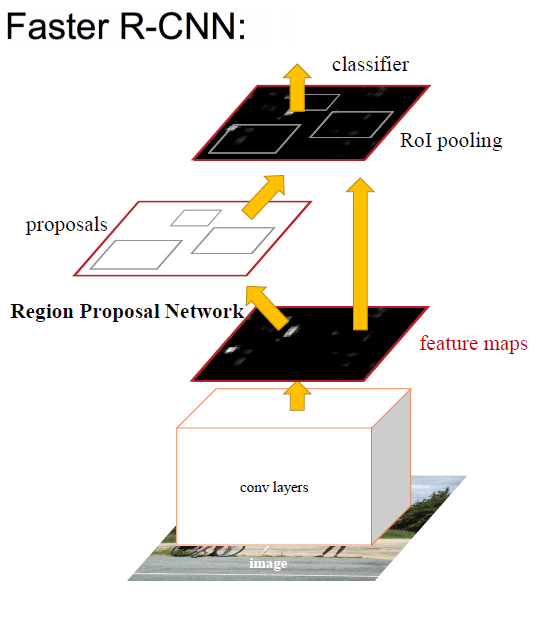
RPN如下图: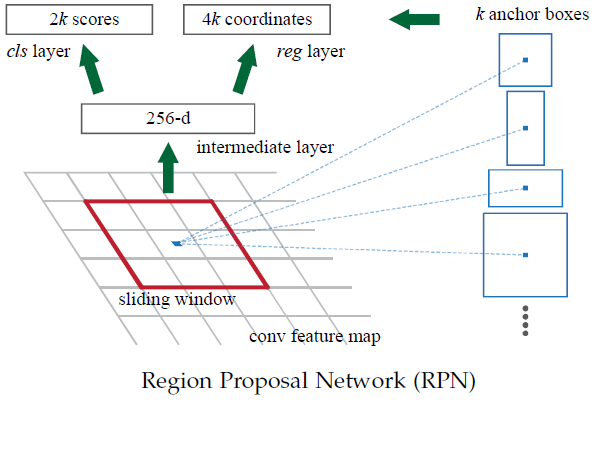
RPN的工作步骤如下:
- 在feature map(特征图)上滑动窗口
- 建一个神经网络用于物体分类+框位置的回归
- 滑动窗口的位置提供了物体的大体位置信息
- 框的回归提供了框更精确的位置
Faster R-CNN设计了提取候选区域的网络RPN,代替了费时的Selective Search(选择性搜索),使得检测速度大幅提升,下表对比了R-CNN、Fast R-CNN、Faster R-CNN的检测速度:
总结
R-CNN、Fast R-CNN、Faster R-CNN一路走来,基于深度学习目标检测的流程变得越来越精简、精度越来越高、速度也越来越快。基于region proposal(候选区域)的R-CNN系列目标检测方法是目标检测技术领域中的最主要分支之一。
大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)的更多相关文章
- R2CNN模型——用于文本目标检测的模型
引言 R2CNN全称Rotational Region CNN,是一个针对斜框文本检测的CNN模型,原型是Faster R-CNN,paper中的模型主要针对文本检测,调整后也可用于航拍图像的检测中去 ...
- 目标检测(三)Fast R-CNN
作者:Ross Girshick 该论文提出的目标检测算法Fast Region-based Convolutional Network(Fast R-CNN)能够single-stage训练,并且可 ...
- 目标检测 | 经典算法 Cascade R-CNN: Delving into High Quality Object Detection
作者从detector的overfitting at training/quality mismatch at inference问题入手,提出了基于multi-stage的Cascade R-CNN ...
- 目标检测(六)YOLOv2__YOLO9000: Better, Faster, Stronger
项目链接 Abstract 在该论文中,作者首先介绍了对YOLOv1检测系统的各种改进措施.改进后得到的模型被称为YOLOv2,它使用了一种新颖的多尺度训练方法,使得模型可以在不同尺寸的输入上运行,并 ...
- 目标检测论文解读3——Fast R-CNN
背景 deep ConvNet兴起,VGG16应用在图像分类任务上表现良好,本文用VGG16来解决检测任务.SPP NET存在CNN层不能fine tuning的缺点,且之前的方法训练都是分为多个阶段 ...
- tensorflow C++接口调用目标检测pb模型代码
#include <iostream> #include "tensorflow/cc/ops/const_op.h" #include "tensorflo ...
- Faster-rcnn实现目标检测
Faster-rcnn实现目标检测 前言:本文浅谈目标检测的概念,发展过程以及RCNN系列的发展.为了实现基于Faster-RCNN算法的目标检测,初步了解了RCNN和Fast-RCNN实现目标检 ...
- 从编程实现角度学习Faster R-CNN(附极简实现)
https://www.jianshu.com/p/9da1f0756813 从编程实现角度学习Faster R-CNN(附极简实现) GoDeep 关注 2018.03.11 15:51* 字数 5 ...
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
随机推荐
- 【干货】Html与CSS入门学习笔记9-11
九.盒模型 与元素亲密接触 1.盒模型 css将每个元素都看做一个盒子,包括以下属性: 内容区content area:包含内容,内容可以决定大小,也可以自行设定宽度和高度.元素的width属性指定的 ...
- Design Pattern ->Prototype
Layering & Contract Philosophy With additional indirection Prototype The example code is as foll ...
- Razor 语法糖常规用法
1.隐匿代码表达式 例: @model.name 会将表达式的值计算并写入到响应中,输入时采用html编码方式 2.显示表达式 例:@(model.name)会将输入@model.name字符串 3. ...
- tomcat下部署项目的流程和遇到的问题笔记
简单部署流程: 1,解析域名关联到服务器ip 2,配置服务器jre运行环境 3,安装tomcat 4,项目打war包,放入tomcat根目录下webapps(tomcat默认加载的项目目录)目录下 5 ...
- 数据结构(C#):图的最短路径问题、(Dijkstra算法)
今天曾洋老师教了有关于图的最短路径问题,现在对例子进行一个自己的理解和整理: 题目: 要求:变成计算出给出结点V1到结点V8的最短路径 答: 首先呢,我会先通过图先把从V1到V8的各种路径全部计算下来 ...
- April 17 2017 Week 16 Monday
You will find that it is necessary to let things go; simply for the reason that they are heavy. 你会明白 ...
- ARM实验6——ADC实验
实验内容: 编写ADC程序,通过FS4412开发板上的电位器,改变ADC通道输入的电压值,经过ADC转换的值打印到终端. 实验目的: 熟悉开发环境: 掌握猎户座4412处理器ADC模块的使用和编程. ...
- LA 3635 派
题目链接:https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_ ...
- CentOS 5 - 安装PHP MongoDB扩展
For driver developers and people interested in the latest bugfixes, you can compile the driver from ...
- 【造轮子】开发vue组件库MeowMeowUI
项目示例 github 1. 创建项目 # 全局安装 vue-cli $ npm install --global vue-cli # 创建一个基于 webpack 模板的新项目 $ vue in ...