CUDA并行存储模型
CUDA将CPU作为主机(Host),GPU作为设备(Device)。一个系统中可以有一个主机和多个设备。CPU负责逻辑性强的事务处理和串行计算,GPU专注于执行高度线程化的并行处理任务。它们拥有相互独立的存储器(主机端的内存和显卡端的显存)。
运行在GPU上的函数称为kernel(内核函数)。一个完整的CUDA程序是由一些列的kernel函数和主机端的串行处理步骤共同完成的。CPU串行代码的工作包括在kernel启动前进行的数据准备、设备初始化以及在kernel之间进行一些串行化计算。
kernel函数以函数类型限定符_global_定义,并且只能在主机端代码中调用。调用时需要制定kernel的Grid中的block数目以及每个block中thread的数目。每个线程有自己的blockID和threadID,可用来区分其它的线程,这两个内建变量是只读的,由专用寄存器提供,只能有kernel函数调用。
CUDA将计算任务映射为大量的可并行执行的线程,并由硬件动态调度和执行这些线程。kernel是以线程网格Grid的形式组织,每个Grid又若干个线程块block组成,每个block又由若干线程thread组成。本质上,kernel是以block为单位执行的,grid只是用来表示一些列并行block的集合。Block之间是不能彼此通信的。目前一个kernel只支持一个grid,在多指令多数据(MIMD)构架中会存在多个grid。
为方便编程,CUDA使用了dim3类型的内建变量threadIdx和threadIdx。
对于一维的block,线程的编号是threadIdx.x。
对于二维(Dx,Dy)的block,线程的编号是threadIdx.x+threadIdx.y * Dx。
对于三维(Dx,Dy,Dz)的block,线程的编号是threadIdx.x+threadIdx.y * Dx+hreadIdx.z* Dx * Dy。
GPU的计算核心是流多处理器(SM),每个SM包含8个标量流处理器(SP)以及其它的运算单元。Kernel是以block为单位执行的,同一个block的线程需要共享数据,因此它们共享同一个SM。一个block必须分配到一个SM,但是可以一个SM中同一个时刻有多个活动块(active block)执行等待,即同一个SM可以有多个block上下文。实际运行中,block会被分为更小的线程束(wrap),线程束的大小由硬件的计算能力决定,Tesla的构架中一个wrap由32个线程组成。
CUDA采用了单指令多线程执行模型。这个模型是对单指令多数据的改进。CUDA中执行宽度可以在1——512个线程之间变化,但是在单指令多数据中执行宽度必须是一个wrap(32)。
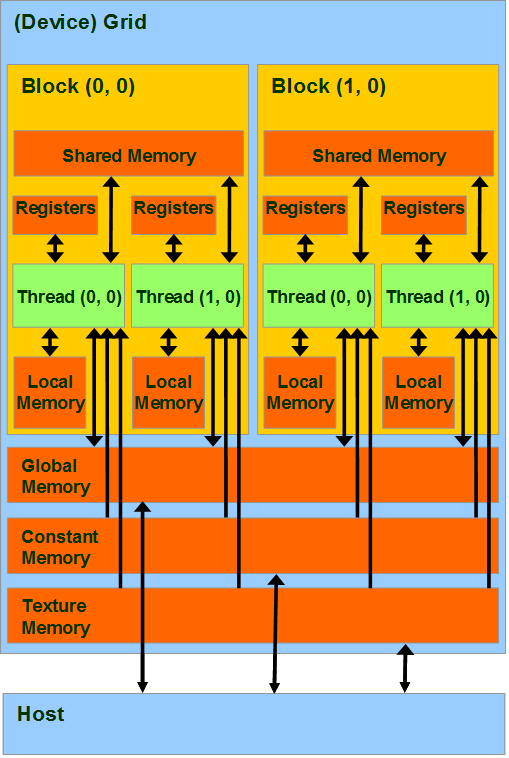
每一个线程拥有自己的私有存储器,每一个线程块拥有一块共享存储器(Shared memory);最后,grid中所有的线程都可以访问同一块全局存储器(global memory)。除此之外,还有两种可以被所有线程访问的只读存储器:常数存储器(constant memory)和纹理存储器(Texture memory),它们分别为不同的应用进行了优化。全局存储器、常数存储器和纹理存储器中的值在一个内核函数执行完成后将被继续保持,可以被同一程序中其也内核函数调用。
|
存储器 |
位置 |
拥有缓存 |
访问权限 |
变量生存周期 |
|
register |
GPU片内 |
N/A |
Device可读/写 |
与thread相同 |
|
Local memory |
板载显存 |
无 |
Device可读/写 |
与thread相同 |
|
Shared memory |
GPU片内 |
N/A |
Device可读/写 |
与block相同 |
|
Constant memory |
板载显存 |
有 |
Device可读,host要读写 |
可在程序中保持 |
|
Texture memory |
板载显存 |
有 |
Device可读,host要读写 |
可在程序中保持 |
|
Global memory |
板载显存 |
无 |
Device可读/写, host可读/写 |
可在程序中保持 |
|
Host memory |
Host内存 |
无 |
host可读/写 |
可在程序中保持 |
|
Pinned memory |
Host内存 |
无 |
host可读/写 |
可在程序中保持 |
CUDA存储器模型:
GPU片内:register,shared memory;
板载显存:local memory,constant memory,texture memory,global memory;
host 内存: host memory, pinned memory.
register: 访问延迟极低;
基本单元:register file (32bit/each)
计算能力1.0/1.1版本硬件:8192/SM;
计算能力1.2/1.3版本硬件: 16384/SM;
每个线程占有的register有限,编程时不要为其分配过多私有变量;
local memory:寄存器被使用完毕,数据将被存储在局部存储器中;
大型结构体或者数组;
无法确定大小的数组;
线程的输入和中间变量;
定义线程私有数组的同时进行初始化的数组被分配在寄存器中;
shared memory:访问速度与寄存器相似;
实现线程间通信的延迟最小;
保存公用的计数器或者block的公用结果;
硬件1.0~1.3中,16KByte/SM,被组织为16个bank;
声明关键字 _shared_ int sdata_static[16];
global memory:存在于显存中,也称为线性内存(显存可以被定义为线性存储器或者CUDA数组);
cudaMalloc()函数分配,cudaFree()函数释放,cudaMemcpy()进行主机端与设备端的数据传输;
初始化共享存储器需要调用cudaMemset();
二维三维数组:cudaMallocPitch()和cudaMalloc3D()分配线性存储空间,可以确保分配满足对齐要求;
cudaMemcpy2D(),cudaMemcpy3D()与设备端存储器进行拷贝;
host内存:分为pageable memory 和 pinned memory
pageable memory: 通过操作系统API(malloc(),new())分配的存储器空间;
pinned memory:始终存在于物理内存中,不会被分配到低速的虚拟内存中,能够通过DMA加速与设备端进行通信;cudaHostAlloc(), cudaFreeHost()来分配和释放pinned memory;
使用pinned memory优点:主机端-设备端的数据传输带宽高;某些设备上可以通过zero-copy功能映射到设备地址空间,从GPU直接访问,省掉主存与显存间进行数据拷贝的工作;pinned memory 不可以分配过多:导致操作系统用于分页的物理内存变,导致系统整体性能下降;通常由哪个cpu线程分配,就只有这个线程才有访问权限;
cuda2.3版本中,pinned memory功能扩充:
portable memory:让控制不同GPU的主机端线程操作同一块portable memory,实现cpu线程间通信;
使用cudaHostAlloc()分配页锁定内存时,加上cudaHostAllocPortable标志;
write-combined Memory:提高从cpu向GPU单向传输数据的速度;不使用cpu的L1,L2 cache对一块pinned memory中的数据进行缓冲,将cache资源留给其他程序使用;在pci-e总线传输期间不会被来自cpu的监视打断;在调用cudaHostAlloc()时加上cudaHostAllocWriteCombined标志;cpu从这种存储器上读取的速度很低;
mapped memory:两个地址:主机端地址(内存地址),设备端地址(显存地址)。
可以在kernnel程序中直接访问mapped memory中的数据,不必在内存和显存之间进行数据拷贝,即zero-copy功能;在主机端可以由cudaHostAlloc()函数获得,在设备端指针可以通过cudaHostGetDevicePointer()获得;通过cudaGetDeviceProperties()函数返回的canMapHostMemory属性知道设备是否支持mapped memory;在调用cudaHostAlloc()时加上cudaHostMapped标志,将pinned memory映射到设备地址空间;必须使用同步来保证cpu和GPu对同一块存储器操作的顺序一致性;显存中的一部分可以既是portable memory又是mapped memory;在执行CUDA操作前,先调用cudaSetDeviceFlags()(加cudaDeviceMapHost标志)进行页锁定内存映射。
constant memory:只读地址空间;位于显存,有缓存加速;64Kb;用于存储需要频繁访问的只读参数 ;只读;使用_constant_ 关键字,定义在所有函数之外;两种常数存储器的使用方法:直接在定义时初始化常数存储器;定义一个constant数组,然后使用函数进行赋值;
texture memory:只读;不是一块专门的存储器,而是牵涉到显存、两级纹理缓存、纹理拾取单元的纹理流水线;数据常以一维、二维或者三维数组的形式存储在显存中;缓存加速;可以声明大小比常数存储器大得多;适合实现图像树立和查找表;对大量数据的随机访问或非对齐访问有良好的加速效果;在kernel中访问纹理存储器的操作成为纹理拾取(texture fetching);纹理拾取使用的坐标与数据在显存中的位置可以不同,通过纹理参照系约定二者的映射方式;将显存中的数据与纹理参照系关联的操作,称为将数据与纹理绑定(texture binding);显存中可以绑定到纹理的数据有:普通线性存储器和cuda数组;存在缓存机制;可以设定滤波模式,寻址模式等;
CUDA并行存储模型的更多相关文章
- 【并行计算-CUDA开发】CUDA并行存储模型
CUDA并行存储模型 CUDA将CPU作为主机(Host),GPU作为设备(Device).一个系统中可以有一个主机和多个设备.CPU负责逻辑性强的事务处理和串行计算,GPU专注于执行高度线程化的并行 ...
- CUDA C++程序设计模型
CUDA C++程序设计模型 本章介绍了CUDA编程模型背后的主要概念,概述了它们在C++中的暴露方式.在编程接口中给出了CUDA C++的广泛描述. 使用的矢量加法示例的完整代码可以在矢量加法CUD ...
- 剖析Elasticsearch集群系列第一篇 Elasticsearch的存储模型和读写操作
剖析Elasticsearch集群系列涵盖了当今最流行的分布式搜索引擎Elasticsearch的底层架构和原型实例. 本文是这个系列的第一篇,在本文中,我们将讨论的Elasticsearch的底层存 ...
- MapReduce并行编程模型和框架
传统的串行处理方式 有四组文本数据: "the weather is good", "today is good", "good weather is ...
- 大数据学习笔记3 - 并行编程模型MapReduce
分布式并行编程用于解决大规模数据的高效处理问题.分布式程序运行在大规模计算机集群上,集群中计算机并行执行大规模数据处理任务,从而获得海量计算能力. MapReduce是一种并行编程模型,用于大规模数据 ...
- 剖析Elasticsearch集群系列之一:Elasticsearch的存储模型和读写操作
转载:http://www.infoq.com/cn/articles/analysis-of-elasticsearch-cluster-part01 1.辨析Elasticsearch的索引与Lu ...
- 【CUDA并行程序设计系列(1)】GPU技术简介
http://www.cnblogs.com/5long/p/cuda-parallel-programming-1.html 本系列目录: [CUDA并行程序设计系列(1)]GPU技术简介 [CUD ...
- 《CUDA并行程序设计:GPU编程指南》
<CUDA并行程序设计:GPU编程指南> 基本信息 原书名:CUDA Programming:A Developer’s Guide to Parallel Computing with ...
- 并发编程学习笔记之Java存储模型(十三)
概述 Java存储模型(JMM),安全发布.规约,同步策略等等的安全性得益于JMM,在你理解了为什么这些机制会如此工作后,可以更容易有效地使用它们. 1. 什么是存储模型,要它何用. 如果缺少同步,就 ...
随机推荐
- Ubuntu16.04安装Nvidia显卡驱动+Cuda8.0+Cudnn6.0
一.安装Nvidia显卡驱动(gtx1050ti) 参考链接:Ubuntu16.04.2 LTS 64bit系统装机记录中的显卡驱动安装部分. 二.安装Cuda8.0 1.确定自己的系统信息,以Ubu ...
- [Leetcode]012. Integer to Roman
public class Solution { public String intToRoman(int num) { String M[] = {"", "M" ...
- Dos窗口一闪而过,如何查看错误?
问:Dos窗口一闪而过,如何查看错误? 答:在执行程序最后追加pause或者read(,),即可查看错误信息.
- qrcode.js的识别解析二维码图片和生成二维码图片
qrcode只通过前端就能生成二维码和解析二维码图片, 首先要引入文件qrcode.js,下载地址为:http://static.runoob.com/download/qrcodejs-04f46c ...
- 子元素的margin-top会影响父元素
---恢复内容开始--- 之前在写项目的时候,发现原本想让父子元素之间加点边距,却让父元素产生了margin-top,于是百度之后发现了原因. 在css2.1盒模型中 In this specific ...
- mysql通过event和存储过程实时更新简单Demo
今天想稍微了解一下存储过程和EVENT事件,最好的方法还是直接做一个简单的demo吧 首先可以在mysql表中创建一个users表 除了设置一些username,password等必要字段以外还要设立 ...
- 响应式及Bootstrap
一丶CSS3的@media 查询 使用 @media 查询,你可以针对不同的屏幕大小定义不同的样式. @media 可以针对不同的屏幕尺寸设置不同的样式,特别是如果你需要设置设计响应式的页面,@med ...
- 分享几道经典的javascript面试题
这几道题目还是有一点意思的,大家可以研究一番,对自己的技能提升绝对有帮助. 1.调用过程中输出的内容是什么 function fun(n, o) { console.log(o); return { ...
- Garmin APP开发之入门
Garmin开发-入门 先附上几个已经开发完成的app日历 up down 翻月 start 回到当前月(就差农历了) 秒表和定时器一体app界面比较简单,但是实用,长按菜单键可以切换秒表和定时器,有 ...
- Elasticsearch-2.3 (OpenLogic CentOS 7.2)
平台: CentOS 类型: 虚拟机镜像 软件包: elasticsearch-2.3 application server basic software big data elasticsearch ...