详细介绍Mybatis的缓存机制
一、缓存机制
1、缓存概述
缓存:缓存就是一块内存空间,保存临时数据
作用:将数据源(数据库或者文件)中的数据读取出来存放到缓存中,再次获取时直接从缓存中获取,可以减少和数据库交互的次数,提升程序的性能
缓存适用:
适用于缓存的:经常查询但不经常修改的,数据的正确与否对最终结果影响不大的
不适用缓存的:经常改变的数据 , 敏感数据(例如:股市的牌价,银行的汇率,银行卡里面的钱)等等
缓存类别:
一级缓存:SqlSession 级别的缓存,又叫本地会话缓存,自带的(不需要配置),一级缓存的生命周期与 SqlSession 一致。在操作数据库时需要构造 SqlSession 对象,在对象中有一个数据结构(HashMap)用于存储缓存数据,不同的 SqlSession 之间的缓存数据区域是互相不影响的
二级缓存:mapper(namespace)级别的缓存,二级缓存的使用,需要手动开启(需要配置)。多个 SqlSession 去操作同一个 Mapper 的 SQL 可以共用二级缓存,二级缓存是跨 SqlSession
开启缓存:配置核心配置文件中标签
- cacheEnabled:true 表示全局性地开启所有映射器配置文件中已配置的任何缓存,默认 true
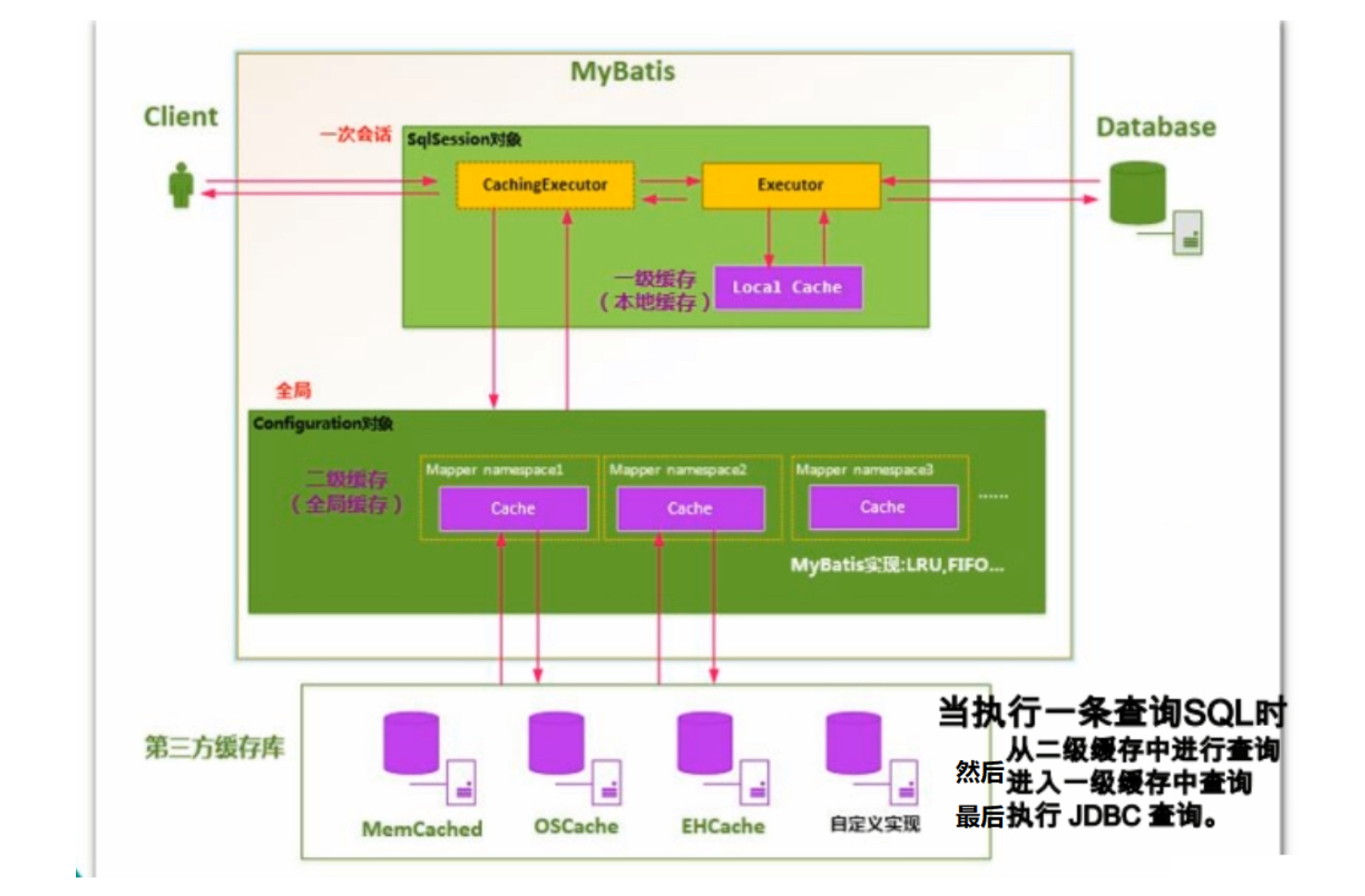
二、一级缓存
一级缓存是 SqlSession 级别的缓存
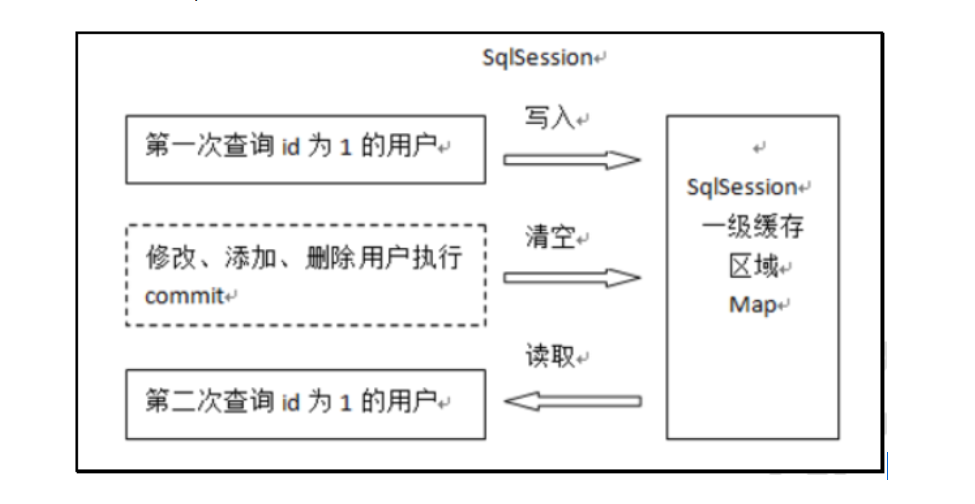
工作流程:第一次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,如果没有,从数据库查询用户信息,得到用户信息,将用户信息存储到一级缓存中;
第二次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,缓存中有,直接从缓存中获取用户信息
一级缓存的失效:
SqlSession 不同
SqlSession 相同,查询条件不同时(还未缓存该数据)
SqlSession 相同,手动清除了一级缓存,调用 sqlSession.clearCache()
SqlSession 相同,执行 commit 操作或者执行插入、更新、删除,清空 SqlSession 中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读
Spring 整合 MyBatis 后,一级缓存作用:
未开启事务的情况,每次查询 Spring 都会创建新的 SqlSession,因此一级缓存失效
开启事务的情况,Spring 使用 ThreadLocal 获取当前资源绑定同一个 SqlSession,因此此时一级缓存是有效的
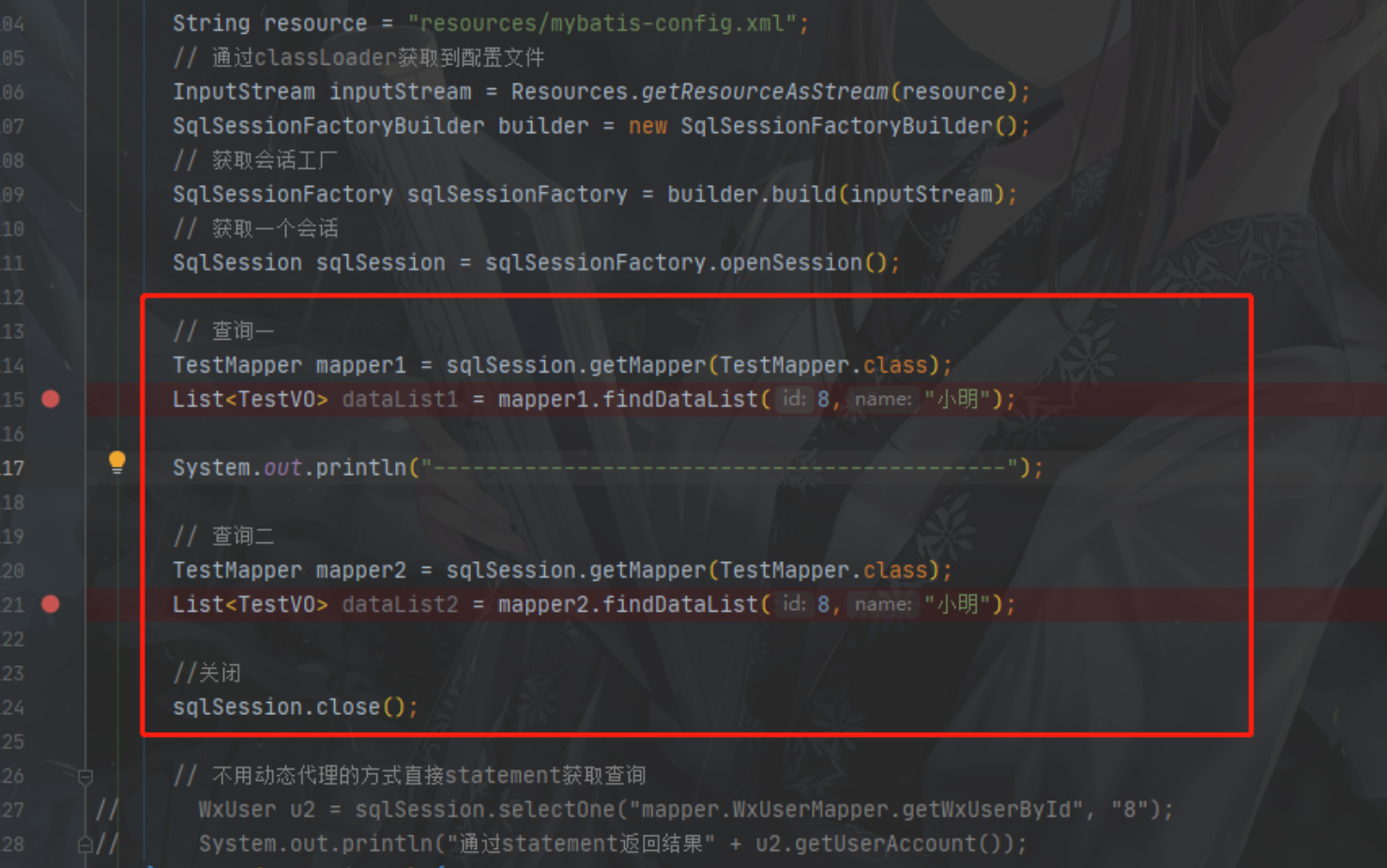
测试示例:
我们在同一个SqlSession整两个一样的查询,并用分隔符分开,执行查看结果
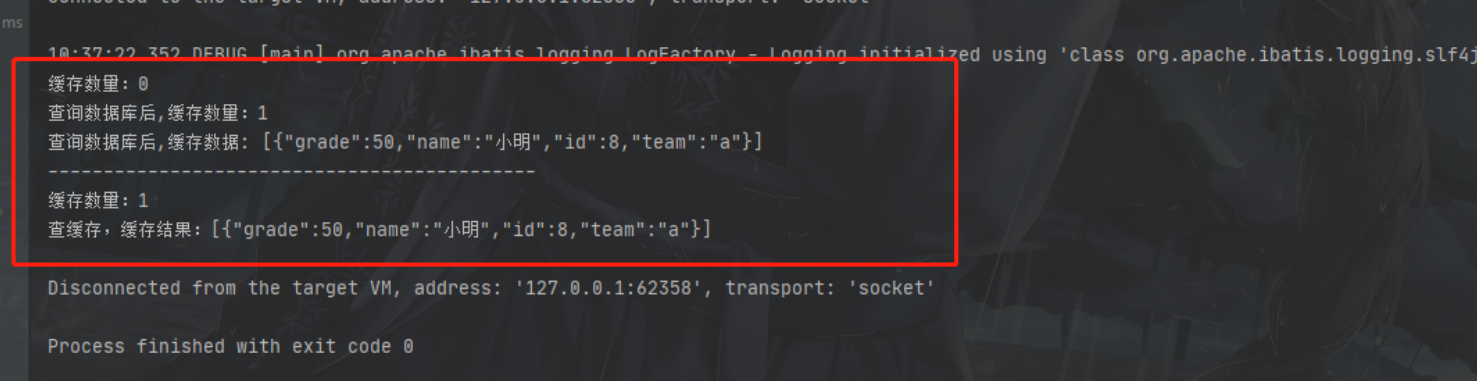
结果:
看分割线上是第一次查询,所以开始缓存数量为0,之后缓存数量为1,并缓存了一条数据,第二次查询直接就命中了缓存并返回了结果
三、二级缓存
1、基本介绍
定义:二级缓存是 mapper 的缓存,只要是同一个命名空间(namespace)的 SqlSession 就共享二级缓存的内容,并且可以操作二级缓存
作用:作用范围是整个应用,可以跨线程使用,适合缓存一些修改较少的数据
工作流程:一个会话查询数据,这个数据就会被放在当前会话的一级缓存中,如果会话关闭 或 提交一级缓存中的数据会保存到二级缓存
二级缓存的基本使用:
1、在 MyBatisConfig.xml 文件开启二级缓存,cacheEnabled 默认值为 true,所以这一步可以省略不配置
<!--配置开启二级缓存-->
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
2、配置 Mapper 映射文件, 标签表示当前这个 mapper 映射将使用二级缓存,区分的标准就看 mapper 的 namespace 值
<mapper namespace="dao.UserDao">
<!--开启user支持二级缓存-->
<cache eviction="FIFO" flushInterval="6000" readOnly="" size="1024"/>
<cache></cache> <!--则表示所有属性使用默认值-->
</mapper>
eviction(清除策略):
LRU、最近最少使用:移除最长时间不被使用的对象,默认
FIFO、先进先出:按对象进入缓存的顺序来移除它们
SOFT、软引用:基于垃圾回收器状态和软引用规则移除对象
WEAK、弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象
flushInterval(刷新间隔):可以设置为任意的正整数, 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新
size(引用数目):缓存存放多少元素,默认值是 1024
readOnly(只读):可以被设置为 true 或 false
只读的缓存会给所有调用者返回缓存对象的相同实例,因此这些对象不能被修改,促进了性能提升
可读写的缓存会(通过序列化)返回缓存对象的拷贝, 速度上会慢一些,但是更安全,因此默认值是 false
type:指定自定义缓存的全类名,实现 Cache 接口即可
3、要进行二级缓存的类必须实现 java.io.Serializable 接口,可以使用序列化方式来保存对象
public class User implements Serializable{}
2、相关属性
a、select 标签的 useCache 属性
映射文件中的 select 标签中设置 useCache="true" 代表当前 statement 要使用二级缓存(默认)
注意:如果每次查询都需要最新的数据 sql,要设置成 useCache=false,禁用二级缓存
<select id="findAll" resultType="user" useCache="true">
select * from user
</select>
b、每个增删改标签都有 flushCache 属性,默认为 true,代表在执行增删改之后就会清除一、二级缓存,保证缓存的一致性;而查询标签默认值为 false,所以查询不会清空缓存
c、localCacheScope:本地缓存作用域, 中的配置项,默认值为 SESSION,当前会话的所有数据保存在会话缓存中,设置为 STATEMENT 禁用一级缓存
3、源码解析
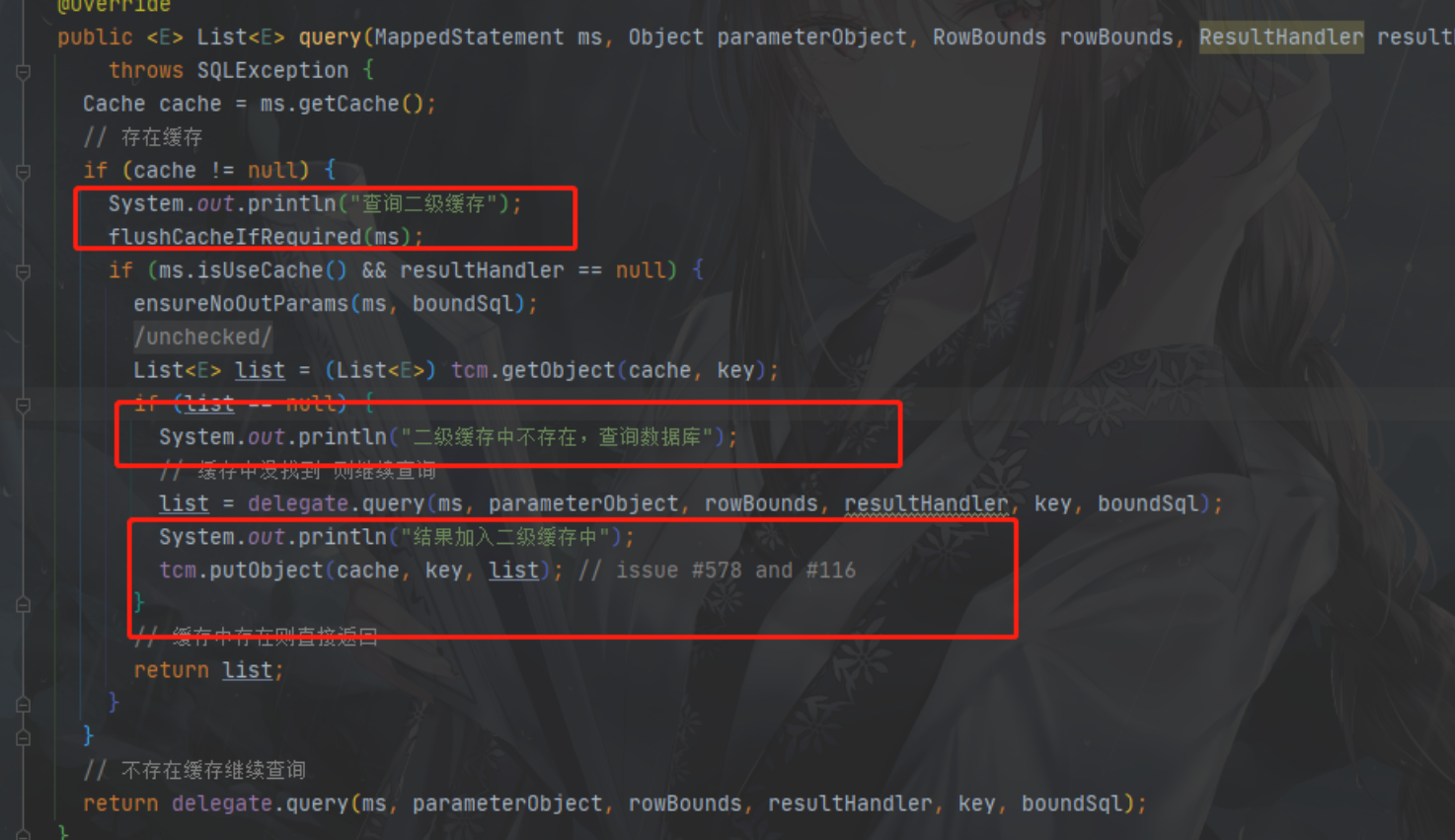
事务提交二级缓存才生效:DefaultSqlSession 调用 commit() 时会回调 executor.commit()
CachingExecutor#query():执行查询方法,查询出的数据会先放入 entriesToAddOnCommit 集合暂存
// 从二缓存中获取数据,获取不到去一级缓存获取
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 回调 BaseExecutor#query
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将数据放入 entriesToAddOnCommit 集合暂存,此时还没放入二级缓存
tcm.putObject(cache, key, list);
}
commit():事务提交,清空一级缓存,放入二级缓存,二级缓存使用 TransactionalCacheManager(tcm)管理
public void commit(boolean required) throws SQLException {
// 首先调用 BaseExecutor#commit 方法,【清空一级缓存】
delegate.commit(required);
tcm.commit();
}
TransactionalCacheManager#commit:将查询出的数据放入二级缓存
public void commit() {
// 获取所有的缓存事务,挨着进行提交
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
} public void commit() {
if (clearOnCommit) {
delegate.clear();
}
// 将 entriesToAddOnCommit 中的数据放入二级缓存
flushPendingEntries();
// 清空相关集合
reset();
} private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
// 将数据放入二级缓存
delegate.putObject(entry.getKey(), entry.getValue());
}
}
增删改操作会清空缓存:
update():CachingExecutor 的更新操作
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
flushCacheIfRequired(ms);
// 回调 BaseExecutor#update 方法,也会清空一级缓存
return delegate.update(ms, parameterObject);
}
flushCacheIfRequired():判断是否需要清空二级缓存
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
// 判断二级缓存是否存在,然后判断标签的 flushCache 的值,增删改操作的 flushCache 属性默认为 true
if (cache != null && ms.isFlushCacheRequired()) {
// 清空二级缓存
tcm.clear(cache);
}
}
4、自定义
自定义缓存
<cache type="com.domain.something.MyCustomCache"/>
type 属性指定的类必须实现 org.apache.ibatis.cache.Cache 接口,且提供一个接受 String 参数作为 id 的构造器
public interface Cache {
String getId();
int getSize();
void putObject(Object key, Object value);
Object getObject(Object key);
boolean hasKey(Object key);
Object removeObject(Object key);
void clear();
}
缓存的配置,只需要在缓存实现中添加公有的 JavaBean 属性,然后通过 cache 元素传递属性值,例如在缓存实现上调用一个名为 setCacheFile(String file) 的方法:
<cache type="com.domain.something.MyCustomCache">
<property name="cacheFile" value="/tmp/my-custom-cache.tmp"/>
</cache>
可以使用所有简单类型作为 JavaBean 属性的类型,MyBatis 会进行转换。
可以使用占位符(如 ${cache.file}),以便替换成在配置文件属性中定义的值
MyBatis 支持在所有属性设置完毕之后,调用一个初始化方法, 如果想要使用这个特性,可以在自定义缓存类里实现 org.apache.ibatis.builder.InitializingObject 接口
public interface InitializingObject {
void initialize() throws Exception;
}
注意:对缓存的配置(如清除策略、可读或可读写等),不能应用于自定义缓存
对某一命名空间的语句,只会使用该命名空间的缓存进行缓存或刷新,在多个命名空间中共享相同的缓存配置和实例,可以使用 cache-ref 元素来引用另一个缓存
<cache-ref namespace="com.someone.application.data.SomeMapper"/>
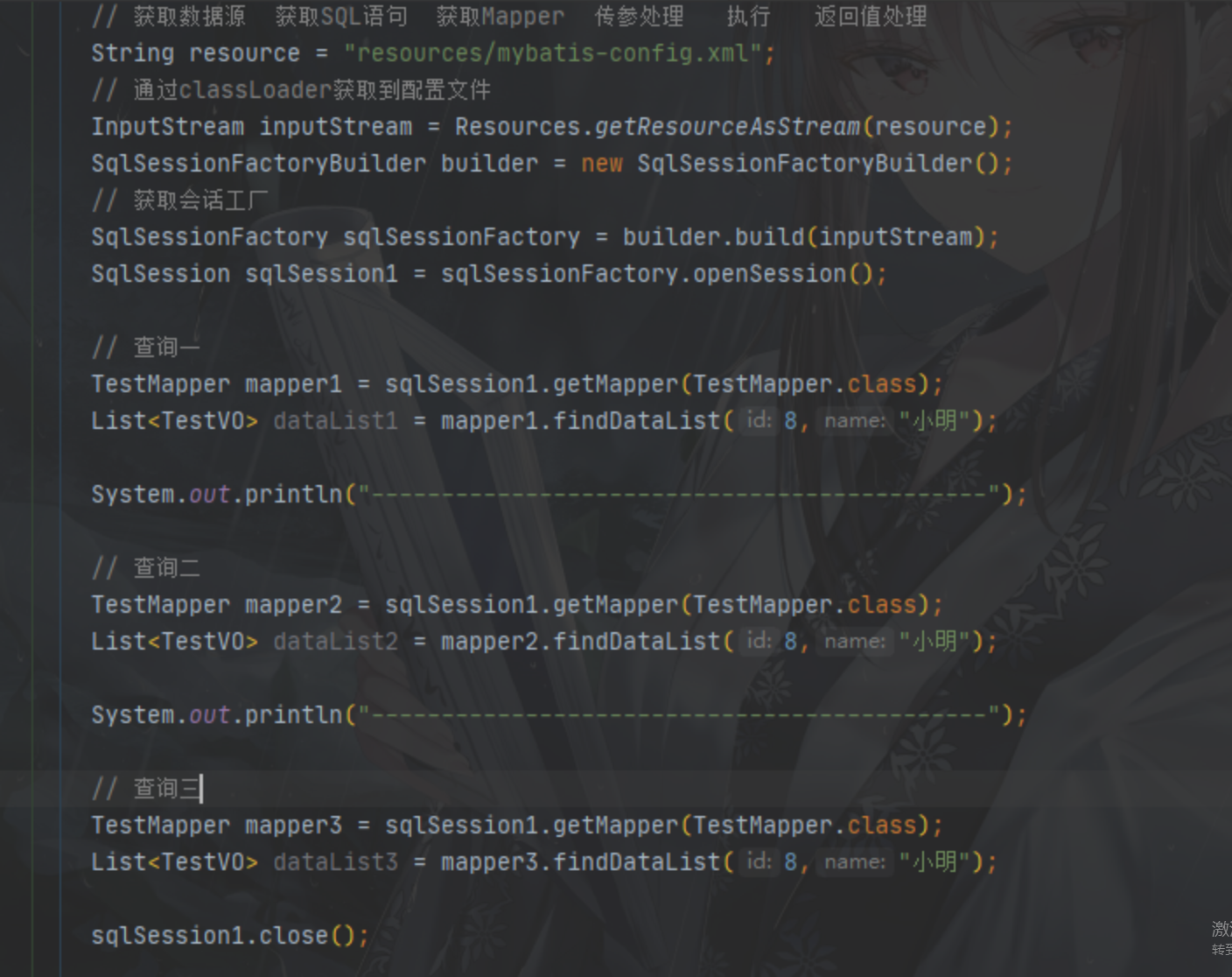
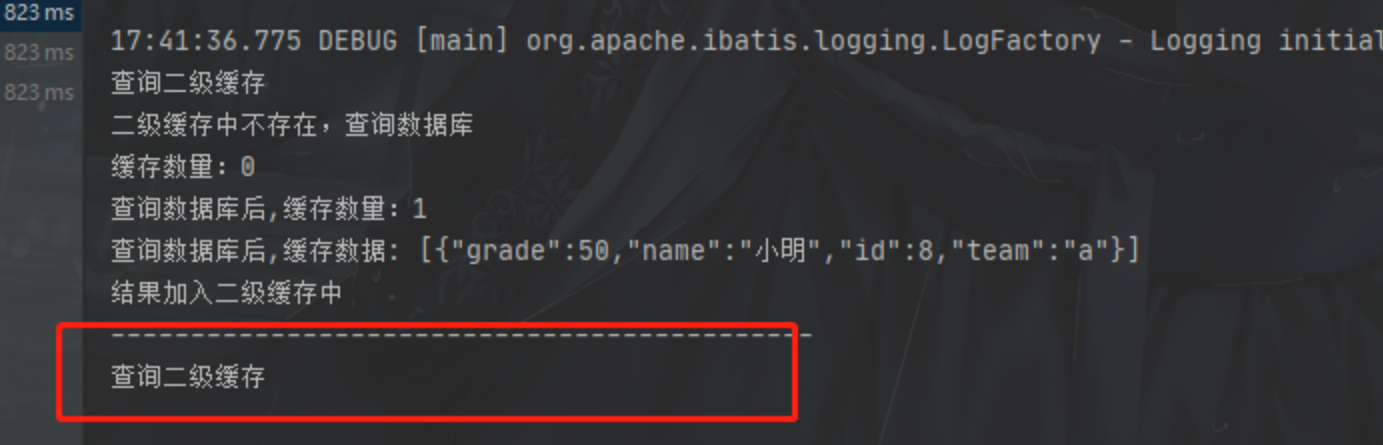
测试案例一:
我们在一个SqlSession中放了三个一样的查询
结果:
执行顺序是先二级再一级没错,但是你会发现之后的查询依旧没走二级缓存而是走了一级缓存,表示二级缓存中没查到
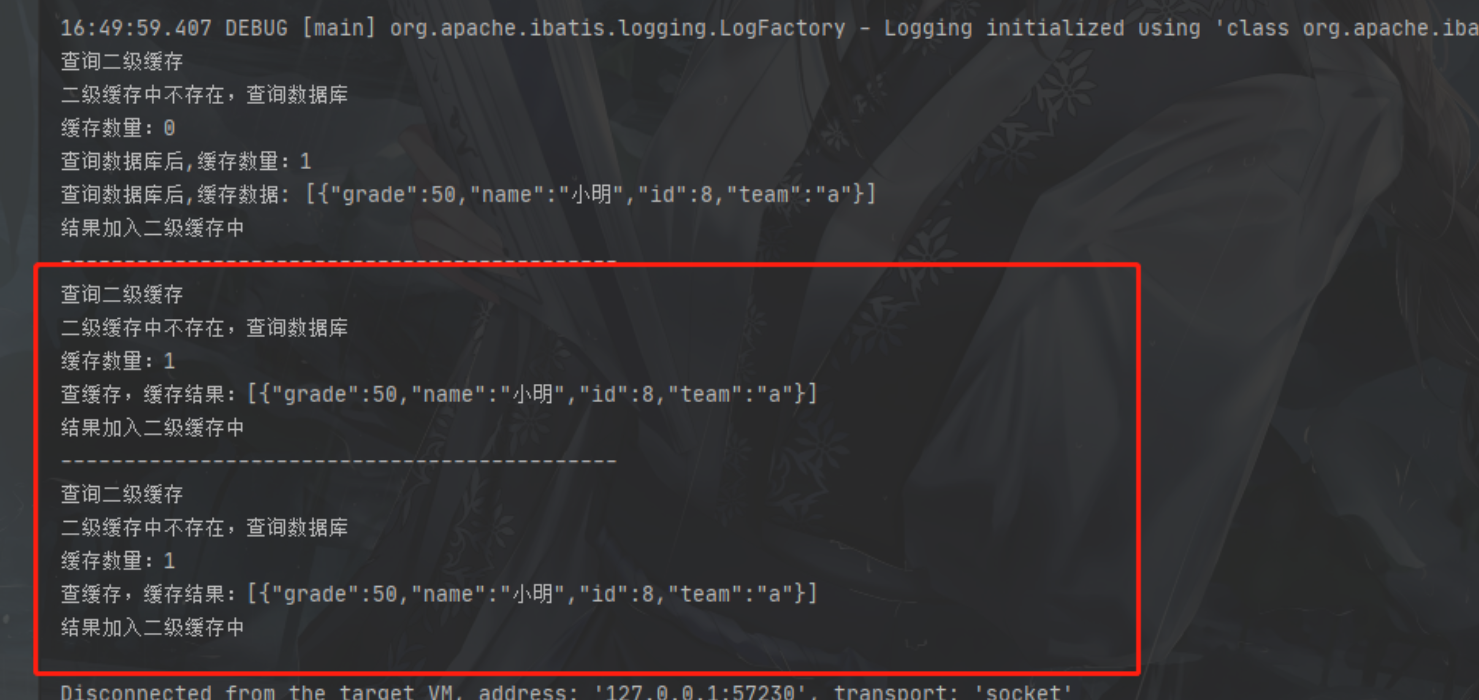
为啥会这样?不是都放进缓存了吗?
二级缓存不是有结果后立刻存储的,而是在事务commit之后才会存储,所以查不到
测试案例二:
与上面相反用了两个SqlSession
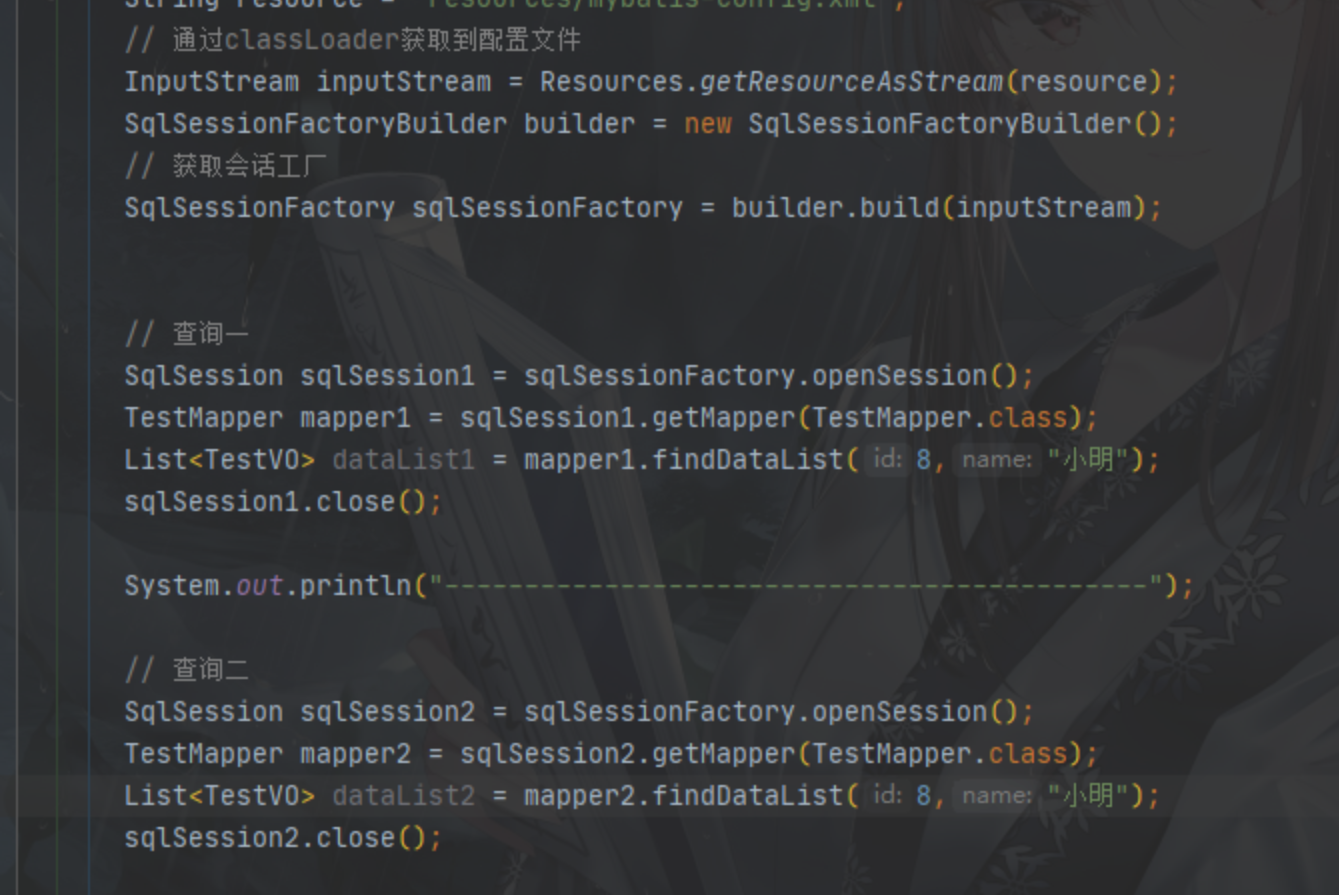
结果:
很明显第二个查询走了二级缓存,这也正好印证了上面我们说的
5、缓存执行顺序:
二级缓存 --> 一级缓存 ---> 数据库
总结
一级缓存在BaseExecutor中,作用域是SqlSession
二级缓存在CachingExecutor中,作用域是namespace
两者都会在修改操作时删除缓存,事务回滚时清除缓存
执行顺序为:二级缓存 --> 一级缓存 ---> 数据库
一级缓存默认开启,二级缓存默认关闭
详细介绍Mybatis的缓存机制的更多相关文章
- mybatis的缓存机制及用例介绍
在实际的项目开发中,通常对数据库的查询性能要求很高,而mybatis提供了查询缓存来缓存数据,从而达到提高查询性能的要求. mybatis的查询缓存分为一级缓存和二级缓存,一级缓存是SqlSessio ...
- 深入浅出mybatis之缓存机制
目录 前言 准备工作 MyBatis默认缓存设置 缓存实现原理分析 参数localCacheScope控制的缓存策略 参数cacheEnabled控制的缓存策略 总结 前言 提到缓存,我们都会不约而同 ...
- mybatis(四)缓存机制
转载:https://www.cnblogs.com/wuzhenzhao/p/11103043.html 缓存是一般的ORM 框架都会提供的功能,目的就是提升查询的效率和减少数据库的压力.跟Hibe ...
- MyBatis - 5.缓存机制
MyBatis 包含一个非常强大的查询缓存特性,它可以非常方便地配置和定制.缓存可以极大的提升查询效率. MyBatis系统中默认定义了两级缓存. 一级缓存和二级缓存. 1.默认情况下,只有一级缓存( ...
- MyBatis 的缓存机制
缓存机制可以减轻数据库的压力,原理是在第一查询时,将查询结果缓存起来,之后再查询同样的sql, 不是真的去查询数据库,而是直接返回缓存中的结果. 缓存可以降低数据库的压力,但同时可能无法得到最新的结果 ...
- MyBatis框架——缓存机制
使⽤缓存机制的作⽤也是减少 Java 应⽤程序与数据库的交互次数,从⽽提升程序的运⾏效率. ⽐如第 ⼀次查询出某个对象之后,MyBatis 会⾃动将其存⼊缓存,当下⼀次查询同⼀个对象时,就可以直接从 ...
- mybatis的缓存机制(一级缓存二级缓存和刷新缓存)和mybatis整合ehcache
1.1 什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存. 一级缓存是SqlSession级别的缓存.在操作数据库时需要构造 s ...
- mybatis的缓存机制
一级缓存: MyBatis的一级缓存指的是在一个Session域内,session为关闭的时候执行的查询会根据SQL为key被缓存(跟mysql缓存一样,修改任何参数的值都会导致缓存失效) packa ...
- 详细介绍Java垃圾回收机制
垃圾收集GC(Garbage Collection)是Java语言的核心技术之一,之前我们曾专门探讨过Java 7新增的垃圾回收器G1的新特性,但在JVM的内部运行机制上看,Java的垃圾回收原理与机 ...
- 聊聊MyBatis缓存机制【美团-推荐】
聊聊MyBatis缓存机制 2018年01月19日 作者: 凯伦 文章链接 18778字 38分钟阅读 前言 MyBatis是常见的Java数据库访问层框架.在日常工作中,开发人员多数情况下是使用My ...
随机推荐
- 多方安全计算(6):MPC中场梳理
学习&转载文章:多方安全计算(6):MPC中场梳理 前言 诚为读者所知,数据出域的限制约束与数据流通的普遍需求共同催生了数据安全计算的需求,近一两年业界又统将能够做到多方数据可用不可见的技术归 ...
- 图解红黑树RBT
rotation:
- JS深度理解
事件循环 程序运行需要有自己专属的内存空间,可以把这块内存简单理解为进程 每个应用至少有一个进程,进程间相互独立,要通信,也需要双方同意 线程 有进程后,就可以运行程序的代码 运行代码的 [人] 称为 ...
- Linux mint的hadoop安装方法
参考网址http://www.powerxing.com/install-hadoop/ 1.创建hadoop账户 这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 sh ...
- DataX - [02] 安装部署
操作系统:Alibaba Cloud Linux release 3 (Soaring Falcon) Java:1.8.0_372 Python:3.6.8 => 2.7.1 一.安装部署 ( ...
- mybatis - [08] mybatis-config.xml 详解
mybatis-config.xml中的标签需要按照一定顺序配置,否则会有以下提示. configuration(配置) properties(属性) settings(设置) typeAliases ...
- docker - [03] docker原理
题记 一.docker是怎么工作的 docker是一个CS(Client - Server)结构的系统,docker的守护进程运行在主机上,通过Socket从客户端访问. docker Server接 ...
- AGC015D题解
简要题意 给定一个区间 \([l,r]\),从中选出若干整数按位或,求可能出现的数的方案数. 数据范围:\(1\le l\le r\le2^{60}\). 思路 首先对于 \([l,r]\) 里的数全 ...
- Python基础-模块和面向对象-shutil、re、bs4、requests模块
概要: 模块 自定义模块(已经讲了) 内置模块 shutil re 正则表达式 第三方模块 requests 模块 bs4 模块 面向对象: 面向对象(Object-Oriented Programm ...
- 「二」nginx下载与安装
1.下载地址(开源版):https://nginx.org/en/download.html wget https://nginx.org/download/nginx-1.14.2.tar.gz 2 ...