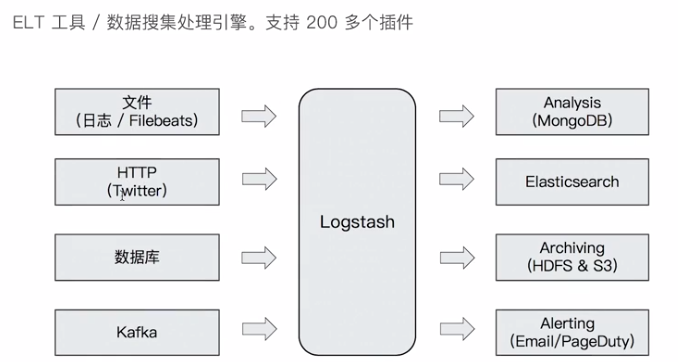
使用LOGSTASH 将数据导入到ES
logstash 执行过程
input -->filter -->output
filter 可以对数据进行处理


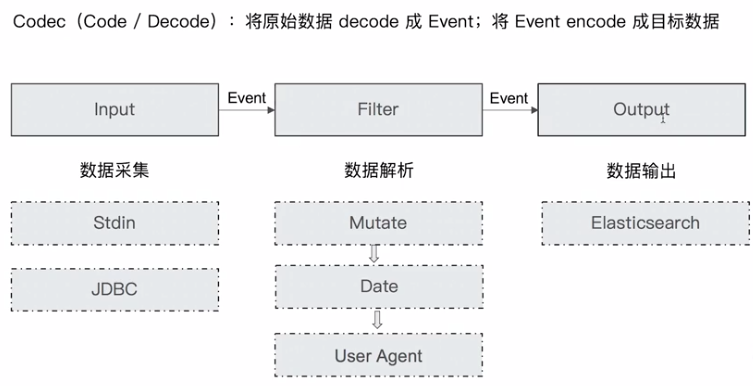


输出插件

codec plugin

使用脚本将数据导入到ES
input {
jdbc {
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/db_example"
jdbc_user => root
jdbc_password => ymruan123
#启用追踪,如果为true,则需要指定tracking_column
use_column_value => true
#指定追踪的字段,
tracking_column => "last_updated"
#追踪字段的类型,目前只有数字(numeric)和时间类型(timestamp),默认是数字类型
tracking_column_type => "numeric"
#记录最后一次运行的结果
record_last_run => true
#上面运行结果的保存位置
last_run_metadata_path => "jdbc-position.txt"
statement => "SELECT * FROM user where last_updated >:sql_last_value;"
schedule => " * * * * * *"
}
}
output {
elasticsearch {
document_id => "%{id}"
document_type => "_doc"
index => "users"
hosts => ["http://localhost:9200"]
}
stdout{
codec => rubydebug
}
}
使用 logstash 执行
logstash -f mysqltoes.conf
使用别名查询索引
POST /_aliases
{
"actions": [
{
"add": {
"index": "users",
"alias": "view_users",
"filter" : { "term" : { "is_deleted" : false } }
}
}
]
}
创建一个索引别名,过滤掉 只显示 is_deleted 为未删除的数据。
通过别名查询数据
POST view_users/_search
{
"query": {
"term": {
"name.keyword": {
"value": "Jack"
}
}
}
}
使用LOGSTASH 将数据导入到ES的更多相关文章
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- Logstash:把MySQL数据导入到Elasticsearch中
Logstash:把MySQL数据导入到Elasticsearch中 前提条件 需要安装好Elasticsearch及Kibana. MySQL安装 根据不同的操作系统我们分别对MySQL进行安装.我 ...
- ES数据导入导出
ES数据导入导出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 ...
- 使用Logstash把MySQL数据导入到Elasticsearch中
总结:这种适合把已有的MySQL数据导入到Elasticsearch中 有一个csv文件,把里面的数据通过Navicat Premium 软件导入到数据表中,共有998条数据 文件下载地址:https ...
- 使用logstash拉取MySQL数据存储到es中的再次操作
使用情况说明: 已经使用logstash拉取MySQL数据存储到es中,es中也创建了相应的索引,也存储了数据.假若把这个索引给删除了,再次进行同步操作的话要咋做,从最开始的数据进行同步,而不是新增的 ...
- 通过logstash-input-mongodb插件将mongodb数据导入ElasticSearch
目的很简单,就是将mongodb数据导入es建立相应索引.数据是从特定的网站扒下来,然后进行二次处理,也就是数据去重.清洗,接着再保存到mongodb里,那么如何将数据搞到ElasticSearch中 ...
- MongoDB-Elasticsearch 实时数据导入
时间 2017-09-18 栏目 MongoDB 原文 http://blog.csdn.net/liangxw1/article/details/78019356 5 ways to sync ...
- 用logstash 作数据的聚合统计
用logstash 作数据的聚合统计 以spark-streaming 处理消费数据,统计日志经spark sql存储在mysql中 日志写入方式为append val wordsDataFrame ...
- 日志收集之--将Kafka数据导入elasticsearch
最近需要搭建一套日志监控平台,结合系统本身的特性总结一句话也就是:需要将Kafka中的数据导入到elasticsearch中.那么如何将Kafka中的数据导入到elasticsearch中去呢,总结起 ...
- 使用ES-Hadoop 6.5.4编写MR将数据索引到ES
目录 1. 开发环境 2. 下载地址 3. 使用示例 4. 参考文献 1. 开发环境 Elasticsearch 6.5.4 ES-Hadoop 6.5.4 Hadoop 2.0.0 2. 下载地址 ...
随机推荐
- Angular 18+ 高级教程 – EventManagerPlugin & Hammer.js Gesture
前言 今天来揭秘一下 Angular 的 Event Listening,看看它底层有什么好玩的地方. (keydown.enter) 语法 在 Component 组件 の Template Bin ...
- RxJS 系列 – Scheduler
前言 大部分情况下, RxJS 都是用来处理异步执行的. 比如 Ajax, EventListener 等等. 但其实, 它也是可以同步执行的, 甚至 by default 它就是同步执行的 (下面会 ...
- MyBatisPlus——简介
概述 MyBatisPlus(简称MP)是基于MyBatisPlus框架基础上开发的增强型工具,旨在简化开发.提高效率 国内开发的技术 特性 无侵入:只做增强不做改变,不会对现有工程产生影响 强大的C ...
- SaaS架构:流程架构分析
大家好,我是汤师爷~ 今天聊聊SaaS架构中的流程架构分析. 业务流程的概念 业务流程是企业为实现目标而制定的一套系统化的工作方法.它由一系列有序的业务活动组成,按照既定规则将资源(输入)转化为有价值 ...
- SimpleAISearch:C# + DuckDuckGo 实现简单的AI搜索
最近AI搜索很火爆,有Perplexity.秘塔AI.MindSearch.Perplexica.memfree.khoj等等. 在使用大语言模型的过程中,或许你也遇到了这种局限,就是无法获取网上最新 ...
- HuggingChat macOS 版现已发布
Hugging Face 的开源聊天应用程序 Hugging Chat,现已推出适用于 macOS 的版本. 主要特点 Hugging Chat macOS 版本具有以下亮点: 强大的模型支持: 用户 ...
- ChatGPT论文降重Prompt
你是一个已经阅读过大量论文的论文写作专家.我正在设计一个基于xxx系统.接下来,我将给你一个论文段落,你可以使用调整句子用词.句子结构等方法,重新描述这段话,对文章的内容进行润色,使之更加接近论文的写 ...
- 【赵渝强老师】使用Docker Compose进行服务编排
一.什么是Docker Compose? Docker Compose是一个用来定义和运行复杂应用的Docker工具.一个使用Docker容器的应用,通常由多个容器组成.使用Docker Compos ...
- 【赵渝强老师】Docker Swarm实现服务的滚动更新
一.什么是Docker Swarm? Docker Swarm是Docker官方提供的一款集群管理工具,其主要作用是把若干台Docker主机抽象为一个整体,并且通过一个入口统一管理这些Docker主机 ...
- php7新内容总结(随时更新)
一.参数和返回值类型申明 可以申明的有:float,int,bool,string,interfaces,array,callable 一般模式: function sum(int ...$ints) ...