70 个群都来问我的 AI 日报,是这么做的。
最近我给 FastGPT 用户交流群里接入了 AI 日报,每天早上 10 点会自动向群里推送 AI 日报,让群里的小伙伴们第一时间了解到昨天 AI 领域都发生了哪些大事。
效果大概是这个样子的:

如果你对 FastGPT 感兴趣,可以直接扫码入群:

除此之外,我还同步一份到公司的飞书群里,这样公司的小伙伴们也能及时了解到 AI 领域的最新动态。
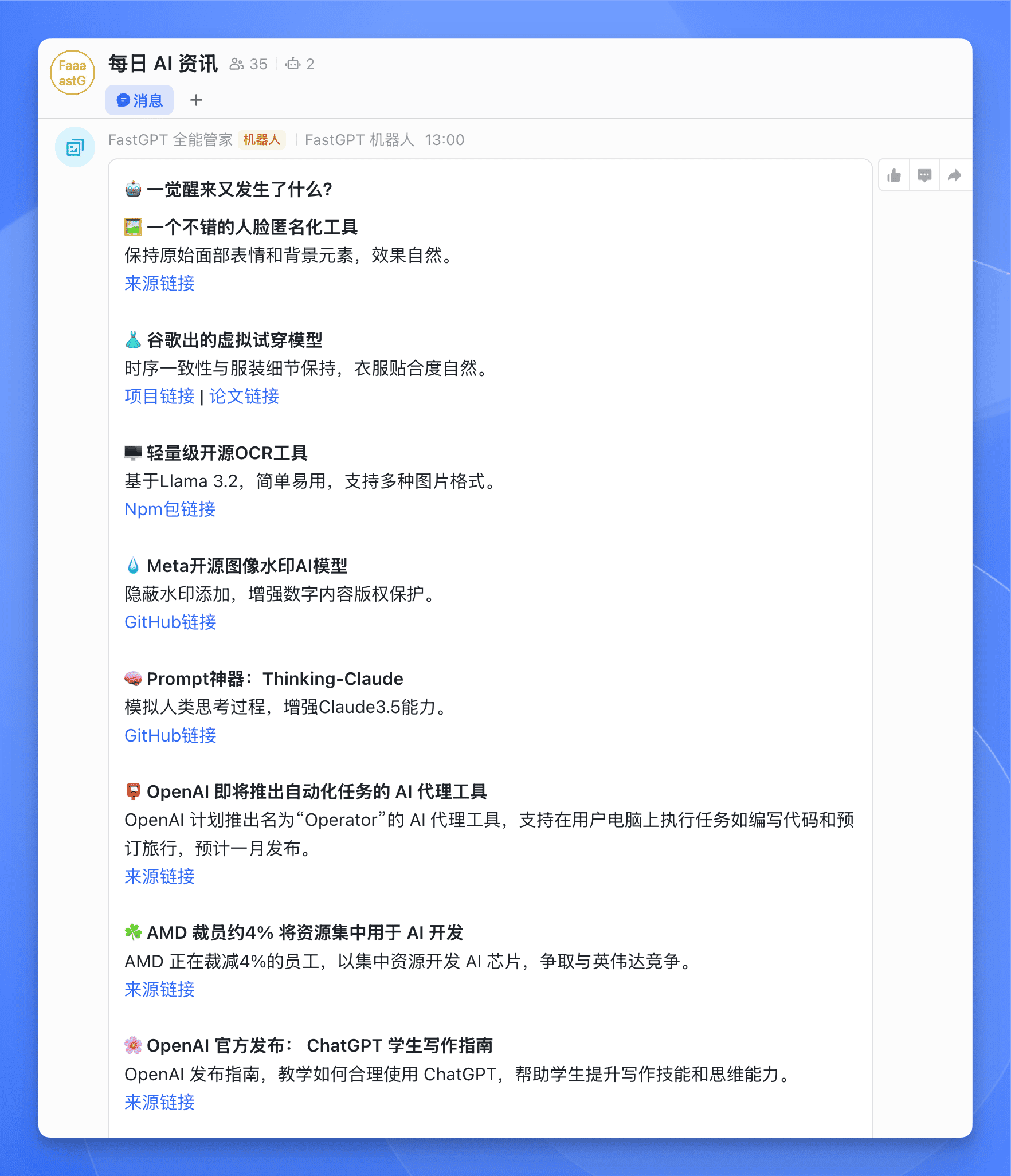
每一条资讯除了提供标题和概要之外,还附上了相关链接,方便大家进一步了解。
你以为这就完了?
我还给公司飞书群里每天发送一份 AI 领域的最新论文摘要,帮助研发同学汲取最新的科研成果。

为什么我要做这么一个日报呢?
因为现在 AI 领域的发展速度实在是太快了,每天都有新的论文、新的技术、新的产品发布,如果不持续关注,真的很容易被时代抛弃。
但是网上的信息量实在是太多太杂了,往往读上几十分钟都感觉没啥收获,但是又怕自己错过什么信息。
所以我就想,如果能开发个机器人,自动爬取并总结一些最新的信息,将简化后的信息每天定时发给我,如果感兴趣可以再进一步搜索,这样我就能每天都能高效获取到有价值的信息了。
有了需求之后,再进一步分析,可以发现这个需求主要的难点有两个:
- 写一个爬虫,爬取对应网站的信息
- 将获取到的信息,通过工作流编排总结归纳
恰好这两个需求分别可以被两个工具快速解决。
创建爬虫
首先,我需要创建一个爬虫,爬取对应网站的信息。
这就需要用到一个牛叉的开源项目 Crawl4ai。
这个项目性能超快,还能输出适合大语言模型的格式,比如 JSON、清理过的 HTML 和 markdown。它还支持同时爬取多个网址,能提取所有媒体标签 (图片、音频、视频),以及所有内外部链接。目前 star 数已经超过 1.5k。

问题来了,这个项目是基于 Python 开发的,而我既不懂 Python,也不会写爬虫。
这个倒是难不倒我,我可以用 Cursor 嘛,让它帮我写就好了。
但是我一想到写完之后还要打包部署,以及配置域名解析、申请 SSL 证书等各种繁琐的事情,瞬间就头大。
嘿嘿,这个问题也可以解决,直接用 Sealos Devbox 就好了,Devbox 直接摒弃了各种繁琐的配置,开箱即用,让你写完爬虫就能直接上线,啥都不需要配置。
我用 Devbox 和 Cursor 半个小时就写完了爬虫并且上线了,你就说快不快吧?
直接来看步骤。
创建开发环境
首先进入 Sealos 桌面,然后打开 Debox 应用,创建一个新项目。Devbox 支持多种主流语言与框架,这里我们需要开发爬虫服务,所以直接选择 Python 作为运行环境。

点击创建,几秒钟即可启动开发环境。
接下来在操作选项中点击 Cursor,将会自动打开本地的 Cursor 编程 IDE。

接着会提示安装 Devbox 插件,安装后即可自动连接开发环境。

Cursor 打开开发环境之后,执行 ./entrypoint.sh 就能看到项目成功跑起来了。

是不是非常简单?直接省略了配置域名解析、申请 SSL 证书,配置网关等与开发无关的繁琐操作,爽!
开发爬虫
接下来,我们就可以开始写爬虫了。
整个开发过程 Cursor 都可以全权代理,你只需要告诉他你要做什么,Cursor 就能帮你完成。

可以看到 Cursor 已经帮我们写好了 crawler 这个基础函数,只要填上需要爬取的地址,就能自动爬取。
它甚至还帮我们想好了下一步应该做什么,即添加一个新的路由来处理请求。

于是我顺着他的话继续往下问。


它也是非常快速地帮我们修改出了路由,这样我们就可以通过请求某个接口实现对应网站的爬取了。
接下来我想优化一下性能,便直接让它在代码上改,也是很快地帮我们优化好了。

最终爬取的效果如下:

有标题,有内容,有时间,有链接,这不就齐活了嘛。
整个开发过程我一行代码都没有写,都是 Cursor 帮我写的,包括爬虫库的使用、路由接口的编排、性能的优化等等,你说爽不爽?
上线爬虫
这个爬虫服务不需要一直运行,只需要每天定时运行一会儿,等我发完了日报就可以关闭了。最重要的是这样省钱啊,每天运行一小会儿,一个月下来也没多少钱,比自己买服务器划算多了。
而 Sealos 正好是按量付费的,运行多长时间就花多长时间的钱,用多少资源就花多少资源的钱,非常划算。
我们需要往 entrypoint.sh 这个文件中写入项目的启动命令 (因为 Devbox 项目发布之后的启动命令就是执行 entrypoint.sh 脚本)。

脚本修改完并保存之后,点击【发布版本】:

填写完信息后点击【发版】。

注意:发版会暂时停止 Devbox,发版后会自动启动,请先保存好项目避免丢失数据。
稍等片刻,即可在版本列表中找到发版信息,点击上线后会跳转到部署页面,点击部署应用即可部署到生产环境。
CPU 和内存可以根据自己的项目情况进行调整。


生产环境分配的 HTTPS 域名与开发环境独立,部署后即可通过生产环境域名访问这个爬虫的接口。

接入 FastGPT 工作流
现在有了爬虫接口,获取了资讯信息,就可以借助 AI 来总结提炼其中的核心信息了。
使用 AI 最简单的方式就是 FastGPT 工作流。
以我们要抓取的一个网站为例,直接使用 HTTP 节点接入即可。
在 HTTP 节点中,我们使用 GET 方法请求爬虫接口,并且设置超时时长为三分钟 (防止信息过多)。

因为爬虫接口的原始响应就是一个文章数组,所以我们可以不用自定义输出字段,直接将原始响应发送给 AI 对话节点即可。
这里用到的是李继刚老师研究的结构化提示词,以 lisp 语言的形式极简高效地实现了对 AI 的提示,我实测下来效果相当不错。

然后进行二次排版,将前面获取到的多个来源的文章总结进行进一步的整合和排版,便于输出。

最后调用 FastGPT 的飞书机器人插件,将整合好后的信息输出到公司的飞书群。

接下来配置一下工作流的定时执行,那么每天十点,早报机器人就会自动运行,总结过去 24h 发生的科技大事,然后以简洁准确的报告形式发送到工具群。

整体的工作流大致如下:

省钱
既然 Sealos 是按量付费,那我干嘛要一直运行着爬虫服务?
我只需要每天早上十点运行一次,然后爬取信息,总结信息,发送信息,然后就可以关闭服务了。
这样每天运行爬虫服务的时间也就几分钟,太省钱了哈哈
那么该如何定时开机关机爬虫服务呢?
哈哈,我直接写到 FastGPT 的工作流里,在工作流的最前面和最后面分别接入一个 HTTP 节点,这样就可以在每天运行工作流之前和之后分别运行爬虫服务,然后关闭爬虫服务,我真是太有才了!
具体的步骤如下。
首先从 Sealos 桌面下载 kubeconfig 文件。

然后执行以下命令,将输出的内容作为请求接口时的 Authorization Header 值:
cat kubeconfig.yaml | jq -sRr @uri
在 FastGPT 工作流的最前面接入一个 HTTP 节点,URL 填入 Sealos【应用管理】的 API 接口地址:
https://applaunchpad.hzh.sealos.run/api/v1alpha/updateReplica
请求方法选择 POST。
在 Header 中添加 Authorization 字段,值为上一步获取到的内容。

然后在 Body 中输入以下内容 (在 x-www-form-urlencoded 中填入参数):

其中 appName 是你的爬虫服务名称,可以在【应用管理】中查看:

而 replica 就是你的服务需要启动的实例数量,一般设置为 1 即可。
下面点击【调试】来测试一下:

搞定!

下面再接入一个 HTTP 节点,URL 填入以下地址:
https://applaunchpad.hzh.sealos.run/api/getAppPodsByAppName
这个接口可以获取到当前爬虫服务运行的 Pod 信息,然后我们就可以根据 Pod 信息来判断爬虫到底有没有启动成功。
请求方法选择 GET。

在 Header 中添加 Authorization 字段,值和前面一样。
然后在 Params 中输入以下内容:

其中 name 是你的爬虫服务名称。
输出字段添加一个变量 data[0].status.containerStatuses[0].state.running,类型为 String。

再添加一个没用的【变量更新】节点,然后再接到【判断器】节点。
- 如果变量
data[0].status.containerStatuses[0].state.running存在,则表示爬虫服务还没运行成功,则接回到前面的【获取爬虫服务状态】节点,继续获取服务状态。 - 如果变量
data[0].status.containerStatuses[0].state.running不存在,则表示爬虫服务已经运行成功,则接入后面的 HTTP 节点开始调用爬虫服务。

最后发送完日报后,再接入一个 HTTP 节点来关闭爬虫服务。参数和前面的【自动开启爬虫服务】节点一样,只需要把 replica 设置为 0 即可。
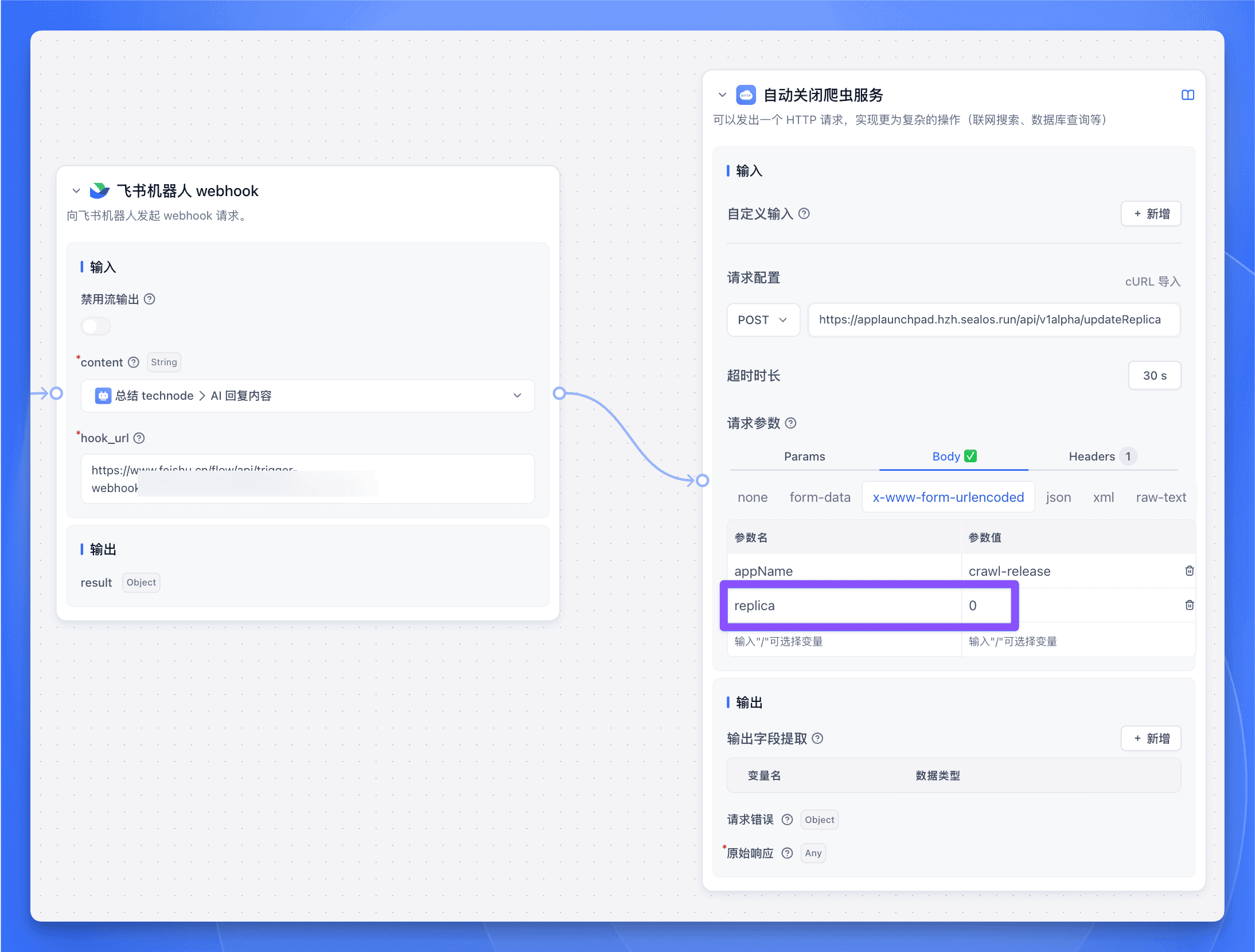
这样就搞定了,每天早上十点,爬虫服务会自动运行,发送完日报后会自动关闭,爽!
总结
好啦!到这里我们就完成了一个自动化的爬虫服务,它会在每天早上十点准时上班 (启动),完成工作 (发送日报) 后就自动下班 (关闭),比我们还自觉呢!
如果你也想搭建一个这样的 “自动打工人”,可以参考以下资源:
快去试试吧,让 AI 帮你完成这些重复性的工作,解放双手享受生活!
70 个群都来问我的 AI 日报,是这么做的。的更多相关文章
- QQ群排名优化到霸屏的策略怎么做?
谈起QQ群排名霸屏,首先要弄清楚概念,有些刚接触QQ群的朋友可能不太了解,所谓的QQ群排名霸屏,就是指当你的客户群体搜索QQ群某个关键词时,出现在QQ群搜索结果前面的群,全部或者大部分都是我们自己的群 ...
- 把ChatGPT配置到微信群里,可以对AI提问了!
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言:用的很爽! 自从小傅哥用上 ChatGPT 连搜索引擎用的都不多了,很多问题的检索我 ...
- 京东无人超市的成长之路 如何利用AI技术在零售业做产品创新?
随着消费及用户体验的需求升级.人货场的运营效率需求提升.人工智能技术的突破以及零售基础设施的变革等因素共同推动了第四次零售革命的到来,不仅在国内,国外一线巨头互联网亚马逊等企业都在研发无人驾驶.无人超 ...
- elasticsearch7.5.0+kibana-7.5.0+cerebro-0.8.5集群生产环境安装配置及通过elasticsearch-migration工具做新老集群数据迁移
一.服务器准备 目前有两台128G内存服务器,故准备每台启动两个es实例,再加一台虚机,共五个节点,保证down一台服务器两个节点数据不受影响. 二.系统初始化 参见我上一篇kafka系统初始化:ht ...
- AI领域:如何做优秀研究并写高水平论文?
来源:深度强化学习实验室 每个人从本科到硕士,再到博士.博士后,甚至工作以后,都会遇到做研究.写论文这个差事.论文通常是对现有工作的一个总结和展示,特别对于博士和做研究的人来说,论文则显得更加重要. ...
- 高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群
高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群 libnet软件包<-依赖-heartbeat(包含ldirectord插件(需要perl-MailTools的rpm包)) l ...
- [转]马上2018年了,该不该下定决心转型AI呢
转自:http://blog.csdn.net/eNohtZvQiJxo00aTz3y8/article/details/78941013 2017年,AI再一次迈向风口,但我们如何判断未来走向?应不 ...
- AI工程师基础知识100题
100道AI基础面试题 1.协方差和相关性有什么区别? 解析: 相关性是协方差的标准化格式.协方差本身很难做比较.例如:如果我们计算工资($)和年龄(岁)的协方差,因为这两个变量有不同的度量,所以我们 ...
- [转帖]中国AI芯“觉醒”的五年
中国AI芯“觉醒”的五年 https://www.cnbeta.com/articles/tech/857863.htm 原来 海思的营收已经超过了按摩店(AMD) 没想到.. 十多款芯片问世,多起并 ...
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
随机推荐
- Maven 设置 JDK 版本
Maven 设置 JDK 版本是通过 Apache Maven Compiler Plugin 插件实现的.它用于编译项目的源代码. 方法一 有时候你可能需要将某个项目编译到与当前使用的 JDK 版本 ...
- failed to copy: httpReadSeeker: failed open: unexpected status code xxx 403
ack上pull镜像的时候,报的错 非运行脚本的问题,由负责ack相关设定的人员调整即可
- Graph 学习
Graph basic terms 里面介绍了常见的一些基本概念,如 directed/undirected, weighted, cyclic/acyclic, Adjacency Matrix, ...
- 在stable diffussion中完美修复AI图片
无论您的提示和模型有多好,一次性获得完美图像的情况很少见. 修复小缺陷的不可或缺的方法是图像修复(inpainting).在这篇文章中,我将通过一些基本示例来介绍如何使用图像修复来修复缺陷. 需要的软 ...
- DECL: 针对噪声时间序列的去噪感知对比学习《Denoising-Aware Contrastive Learning for Noisy Time Series》(时间序列、对比学习、去噪)
今天是2024年9月12日,组会摸鱼,很久没看论文了,在摸鱼看代码,最近IJCAI 2024出来了,找了几篇论文看,首先这是第一篇. 论文:Denoising-Aware Contrastive Le ...
- SpringMVC——SSM整合-异常处理器
异常处理器 出现异常的常见位置与常见诱因: 框架内部抛出的异常:因使用不合规导致 数据层抛出异常:因外部服务器故障导致(例如:服务器访问超时) 业务层抛出的异常:因业务逻辑书写错误导致(例如:遍历业务 ...
- dfs 【XR-2】奇迹——洛谷5440
问题描述: 现有一个八位数,从左往右分别代表年月日,例如20240919,代表2024年9月19日,现将该八位数蒙住几位数,问填入数字之后有几种情况是的日为质数,月+日为质数,年+月+日为质数 输入: ...
- ModbusRTU通信协议报文剖析
前言 大家好!我是付工.前面给大家介绍了Modbus协议的应用层面.终于有人把Modbus说明白了那么,今天跟大家聊聊关于Modbus协议报文的那些事. 一.真实案例 前段时间有个粉丝朋友,让我帮他解 ...
- SpringBoot注解大全(详细)
1. @ActiveProfiles 用来声明活动的profile–@ActiveProfiles("prod"(这个prod定义在配置类中)) @RunWith(SpringRu ...
- AtCoder Regular Contest 182(A B C)
原来第二题比第一题简单吗 A.Chmax Rush! \(\texttt{Diff 1110}\) 给定三个序列 \(S,P,V\),其中 \(S\) 的长度为 \(N\),\(P,V\) 的长度为 ...