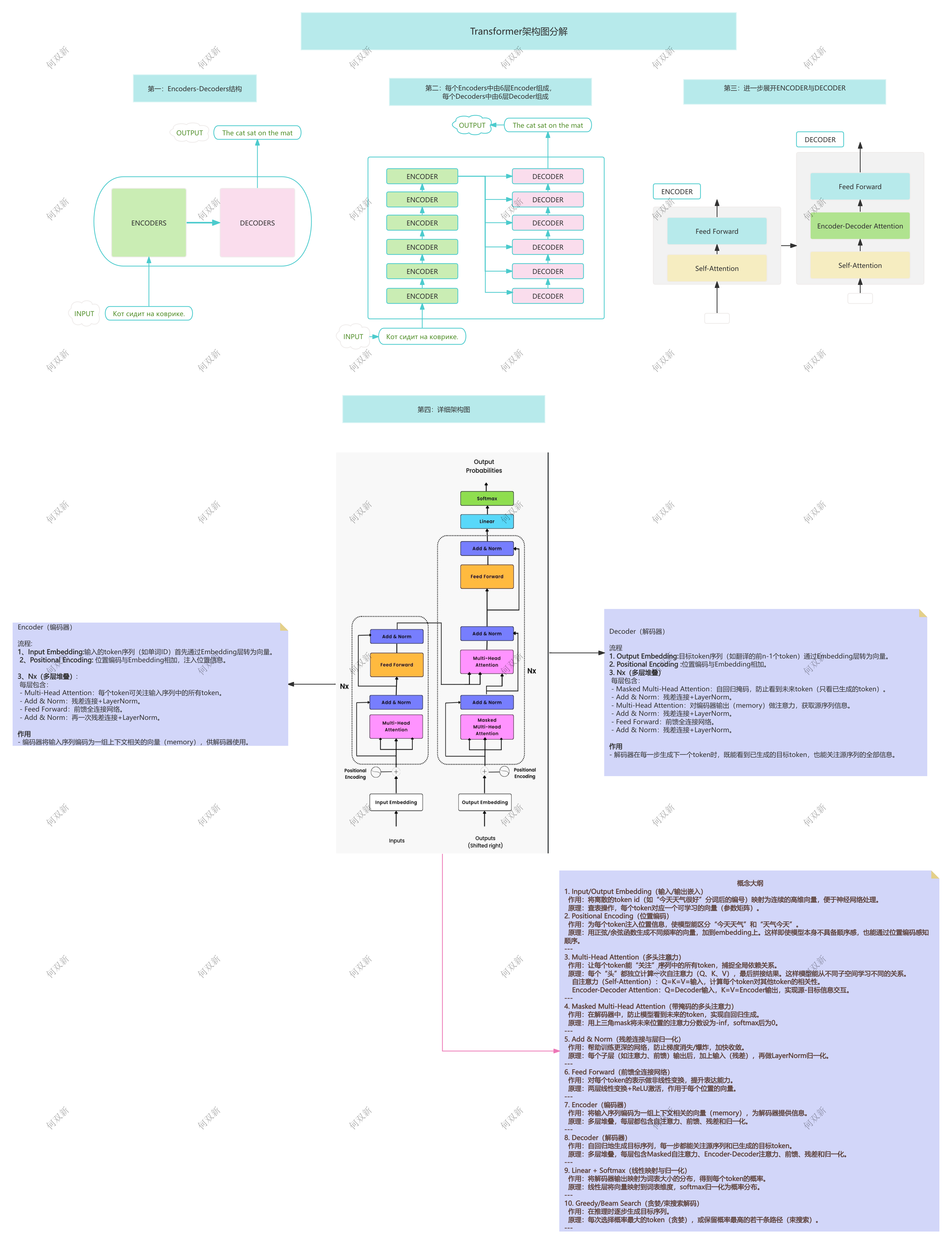
第9.3讲、Tiny Transformer: 极简版Transformer
简介
极简版的 Transformer 编码器-解码器(Seq2Seq)结构,适合用于学习、实验和小型序列到序列(如翻译、摘要)任务。
该实现包含了位置编码、多层编码器、多层解码器、训练与推理流程,代码简洁易懂,便于理解 Transformer 的基本原理。
主要结构
- PositionalEncoding:正弦/余弦位置编码,为输入embedding添加位置信息。
- TransformerEncoderLayerWithTrace:单层编码器,含自注意力和前馈网络。
- TinyTransformer:多层堆叠的编码器。
- TransformerDecoderLayer:单层解码器,含自注意力、交叉注意力和前馈网络。
- TransformerDecoder:多层堆叠的解码器。
- TinyTransformerSeq2Seq:编码器-解码器整体结构。
- Seq2SeqDataset:简单的序列到序列数据集。
- train:训练循环。
- greedy_decode:贪婪解码推理。
- generate_subsequent_mask:生成自回归mask。
依赖环境
- Python 3.7+
- torch >= 1.10
安装 PyTorch(以 CPU 版本为例):
pip install torch
用法示例
1. 构建模型
from demo import TinyTransformerSeq2Seq
src_vocab_size = 1000
trg_vocab_size = 1000
model = TinyTransformerSeq2Seq(src_vocab_size, trg_vocab_size)
2. 构造数据集和 DataLoader
from demo import Seq2SeqDataset
from torch.utils.data import DataLoader
src_data = torch.randint(0, src_vocab_size, (100, 10)) # 100个样本,每个10个token
trg_data = torch.randint(0, trg_vocab_size, (100, 12)) # 100个样本,每个12个token
dataset = Seq2SeqDataset(src_data, trg_data)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
3. 训练模型
import torch.optim as optim
import torch.nn as nn
from demo import train
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss(ignore_index=0)
epoch_loss = train(model, dataloader, optimizer, criterion, tgt_pad_idx=0)
print(f"Train loss: {epoch_loss}")
4. 推理(贪婪解码)
from demo import greedy_decode
src = torch.randint(0, src_vocab_size, (1, 10)).to(device)
sos_idx = 1 # 假设1为<sos>
eos_idx = 2 # 假设2为<eos>
max_len = 12
output = greedy_decode(model, src, sos_idx, eos_idx, max_len)
print("Output token ids:", output)
注意事项
- 该实现为教学/实验用途,未包含完整的mask、权重初始化、分布式训练等工业级细节。
- 需要自行准备合适的训练数据和词表。
- 若需工业级NLP任务,建议使用 HuggingFace Transformers。
tiny Transformer案例代码1:
import torch
import torch.nn as nn
import torch.optim as optim
import math
from torch.utils.data import DataLoader, Dataset
# =========================
# 位置编码模块
# =========================
class PositionalEncoding(nn.Module):
"""
为输入的embedding添加位置信息,帮助模型捕捉序列顺序。
"""
def __init__(self, d_model, max_len=512):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
# x: (batch, seq_len, d_model)
return x + self.pe[:, :x.size(1)]
# =========================
# 编码器层
# =========================
class TransformerEncoderLayerWithTrace(nn.Module):
"""
单层Transformer编码器,带自注意力和前馈网络。
"""
def __init__(self, d_model, nhead, dim_feedforward):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, batch_first=True)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, src, src_mask=None):
# src: (batch, seq_len, d_model)
src2, attn_weights = self.self_attn(src, src, src, attn_mask=src_mask)
src = self.norm1(src + self.dropout(src2))
src2 = self.linear2(self.dropout(torch.relu(self.linear1(src))))
src = self.norm2(src + self.dropout(src2))
return src, attn_weights
# =========================
# 编码器
# =========================
class TinyTransformer(nn.Module):
"""
多层堆叠的Transformer编码器。
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, nhead, dim_feedforward, max_len, num_layers):
super().__init__()
self.embedding = nn.Embedding(src_vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([
TransformerEncoderLayerWithTrace(d_model, nhead, dim_feedforward)
for _ in range(num_layers)
])
def forward(self, src, trace=False):
# src: (batch, seq_len)
src = self.embedding(src)
src = self.pos_encoder(src)
attn_weights_all = []
for layer in self.layers:
src, attn_weights = layer(src)
if trace:
attn_weights_all.append(attn_weights)
return src, attn_weights_all
# =========================
# 解码器层
# =========================
class TransformerDecoderLayer(nn.Module):
"""
单层Transformer解码器,含自注意力、交叉注意力和前馈网络。
"""
def __init__(self, d_model, nhead, dim_feedforward):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, batch_first=True)
self.cross_attn = nn.MultiheadAttention(d_model, nhead, batch_first=True)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None):
# tgt: (batch, tgt_seq_len, d_model)
# memory: (batch, src_seq_len, d_model)
tgt2, _ = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask)
tgt = self.norm1(tgt + self.dropout(tgt2))
tgt2, _ = self.cross_attn(tgt, memory, memory, attn_mask=memory_mask)
tgt = self.norm2(tgt + self.dropout(tgt2))
tgt2 = self.linear2(self.dropout(torch.relu(self.linear1(tgt))))
tgt = self.norm3(tgt + self.dropout(tgt2))
return tgt
# =========================
# 解码器
# =========================
class TransformerDecoder(nn.Module):
"""
多层堆叠的Transformer解码器。
"""
def __init__(self, vocab_size, d_model, nhead, dim_feedforward, num_layers, max_len=512):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([
TransformerDecoderLayer(d_model, nhead, dim_feedforward)
for _ in range(num_layers)
])
self.out_proj = nn.Linear(d_model, vocab_size)
def forward(self, tgt_ids, memory, tgt_mask=None):
# tgt_ids: (batch, tgt_seq_len)
x = self.embedding(tgt_ids)
x = self.pos_encoder(x)
for layer in self.layers:
x = layer(x, memory, tgt_mask)
return self.out_proj(x)
# =========================
# Seq2Seq整体模型
# =========================
class TinyTransformerSeq2Seq(nn.Module):
"""
编码器-解码器结构的Transformer模型。
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=64, heads=4, d_ff=128, num_layers=2, max_len=64):
super().__init__()
self.encoder = TinyTransformer(src_vocab_size, tgt_vocab_size, d_model, heads, d_ff, max_len, num_layers)
self.decoder = TransformerDecoder(
vocab_size=tgt_vocab_size,
d_model=d_model,
nhead=heads,
dim_feedforward=d_ff,
num_layers=num_layers,
max_len=max_len
)
def forward(self, src_ids, tgt_input_ids, tgt_mask=None):
# src_ids: (batch, src_seq_len)
# tgt_input_ids: (batch, tgt_seq_len)
memory, _ = self.encoder(src_ids, trace=False)
logits = self.decoder(tgt_input_ids, memory, tgt_mask)
return logits
# =========================
# 工具函数: 生成自回归mask
# =========================
def generate_subsequent_mask(size):
"""
生成自回归mask,防止解码器看到未来的信息。
"""
return torch.triu(torch.full((size, size), float('-inf')), diagonal=1)
# =========================
# Toy数据集
# =========================
class Seq2SeqDataset(Dataset):
"""
简单的序列到序列数据集。
"""
def __init__(self, src_data, tgt_data):
self.src = src_data
self.tgt = tgt_data
def __len__(self):
return len(self.src)
def __getitem__(self, idx):
return self.src[idx], self.tgt[idx]
# =========================
# 训练循环
# =========================
def train(model, dataloader, optimizer, criterion, tgt_pad_idx):
"""
训练模型一个epoch。
"""
model.train()
total_loss = 0
for src, tgt in dataloader:
src, tgt = src.to(device), tgt.to(device)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
tgt_mask = generate_subsequent_mask(tgt_input.size(1)).to(device)
logits = model(src, tgt_input, tgt_mask)
loss = criterion(logits.view(-1, logits.size(-1)), tgt_output.reshape(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
# =========================
# 推理(贪婪解码)
# =========================
def greedy_decode(model, src, sos_idx, eos_idx, max_len):
"""
贪婪解码:每步选择概率最大的token,直到eos或最大长度。
"""
model.eval()
src = src.to(device)
memory, _ = model.encoder(src, trace=False)
tgt = torch.ones((src.size(0), 1), dtype=torch.long).fill_(sos_idx).to(device)
for _ in range(max_len - 1):
tgt_mask = generate_subsequent_mask(tgt.size(1)).to(device)
out = model.decoder(tgt, memory, tgt_mask)
next_token = out[:, -1, :].argmax(dim=-1).unsqueeze(1)
tgt = torch.cat([tgt, next_token], dim=1)
if (next_token == eos_idx).all():
break
return tgt
# =========================
# 设备选择
# =========================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
第9.3讲、Tiny Transformer: 极简版Transformer的更多相关文章
- Underscore源码阅读极简版入门
看了网上的一些资料,发现大家都写得太复杂,让新手难以入门.于是写了这个极简版的Underscore源码阅读. 源码: https://github.com/hanzichi/underscore-an ...
- js消除小游戏(极简版)
js小游戏极简版 (1) 基础布局 <div class = "box"> <p></p> <div class="div&qu ...
- SimpleThreadPool极简版
package com.dwz.concurrency.chapter13; import java.util.ArrayList; import java.util.LinkedList; impo ...
- 极简版ASP.NET Core学习路径及教程
绝承认这是一个七天速成教程,即使有这个效果,我也不愿意接受这个名字.嗯. 这个路径分为两块: 实践入门 理论延伸 有了ASP.NET以及C#的知识以及项目经验,我们几乎可以不再需要了解任何新的知识就开 ...
- Vue Virtual Dom 和 Diff原理(面试必备) 极简版
我又来了,这是Vue面试三板斧的最后一招,当然也是极其简单了,先说Virtual Dom,来一句概念: 用js来模拟DOM中的节点.传说中的虚拟DOM. 再来一张图: 是不是一下子秒懂 没懂再来一张 ...
- Vue数据双向绑定(面试必备) 极简版
我又来吹牛逼了,这次我们简单说一下vue的数据双向绑定,我们这次不背题,而是要你理解这个流程,保证读完就懂,逢人能讲,面试必过,如果没做到,请再来看一遍,走起: 介绍双向数据之前,我们先解释几个名词: ...
- 极简版 react+webpack 脚手架
目录结构 asset/ css/ img/ src/ entry.js ------------------------ 入口文件 .babelrc index.html package.json w ...
- 【极简版】SpringBoot+SpringData JPA 管理系统
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 在上一篇中已经讲解了如何从零搭建一个SpringBo ...
- cookie——登录注册极简版
本实例旨在最直观地说明如何利用cookie完成登录注册功能,忽略正则验证. index.html <!doctype html> <html lang="en"& ...
- 极简版 卸载 home 扩充 根分区--centos7 xfs 文件格式
1. 查看文件系统 df -Th 2. 关闭正常连接 /home的用户 fuser /home 3. 卸载 /home的挂载点 umount /home 4.删除home的lv 注意 lv的名称的写法 ...
随机推荐
- 【问题解决】Jenkins使用File的exists()方法判断文件存在,一直提示不存在的问题
小剧场 最近为了给项目组提供一个能给Java程序替换前端.后端的增量的流水线,继续写上了声明式流水线. 替换增量是根据JSON配置文件去增量目录里去取再替换到对应位置的,替换前需要判断增量文件是否存在 ...
- mysql : 第5章 数据库的安全性
-- 创建用户CREATE USER utest@localhost IDENTIFIED BY 'temp';-- 查看所有用户SELECT * FROM mysql.user;-- 查看表级权限S ...
- 部署sing-box代理服务器绕过付费校园网上网
解决的问题 学校一般会有2个网络,一个是教学区的免费校园网,一个是寝室楼的付费校园网.如何不交钱也能在寝室楼上网是一个问题. 以及,如果校园网在12点之后断网,如果解决断网问题 sing-box Gi ...
- 【硬件】认识和选购4K画质的显卡
2.6 认识和选购4K画质的显卡 显卡一般是一块独立的电路板,插在主板上接收由主机发出的控制显示系统工作的指令和显示内容的数字信号,然后通过输出模拟(或数字)信号控制显示器显示各种字符和图形,它和显示 ...
- Oracle 11G R2 安装图解
个人学习需要,在Windows Server 2008 R2 上安装 Oracle 11G R2 Tips:需要下载2个文件,file1和file2 解压后需要合并到同一个文件夹下才能正常安装(这里就 ...
- leetcode每日一题:图中的最长环
题目 2360. 图中的最长环 给你一个 n 个节点的 有向图 ,节点编号为 0 到 n - 1 ,其中每个节点 至多 有一条出边. 图用一个大小为 n 下标从 0 开始的数组 edges 表示,节点 ...
- [SDR] 蓝牙专项教程 —— 从 0 到 1 教小白基于 SDR 编写蓝牙协议栈
目录 前言 一.开题之作 二.动态发送 BLE 广播包 三.基于 PlutoSDR 实现 BLE 广播包的收发一体能力 四.基于 PlutoSDR 的 BLE 广播包的收发实现接入涂鸦智能 APP 教 ...
- volatile修饰全局变量,可以保证线程并发安全吗?
今天被人问到volatile能不能保证并发安全? 呵,这能难倒我? 直接上代码: public class ThreadTest { // 使用volatile修饰变量 private static ...
- vue2&vue3&小程序简介
Vue2.Vue3.小程序页面生命周期详解 本篇将对比 Vue2.Vue3 以及小程序页面/组件的生命周期,简单梳理各自特点.差异.新增优化点. Vue2 生命周期 beforeCreate → cr ...
- Eclipse 安装Server-Apache Tomcat 选择(Tomcat 9.0选项)
1.打开组件安装 Eclipse→Help→Install New Software 2.输入当前eclipse对应版本(例如:2022-06),选择提示的官方路径 3.选择最底下的Web, XML, ...