MySQL性能调优必知:Performance Schema引擎的配置与使用
当你在MySQL高并发情况下的进行性能调优时,需要知道调整后的影响。例如查询是否变快了?锁是否会减慢运行速度?内存使用情况如何?磁盘IO等待时间变了吗?
.
Performance Schema就有一个存储回答上述问题所需数据的数据库。本篇文章将帮你了解Performance Schema的工作原理、局限性,以及如何更好地使用它和sys Schema来搞清楚MySQL内部的运行细节。
1. Performance Schema介绍
介绍Performance Schema的工作机制前,先解释两个概念:
- 程序插桩(instrument): 指在MySQL代码中插入探测代码,以获取我们想了解的信息(也就是生产数据的代码,即所需数据的提供者、生产者)。就像一般的的链路监控框架,如Google的Dapper就是通过在代码中插入探测代码的方式获取信息。(一般Java链路监控框架是通过代理的方式修改字节码文件, 在代码中间插入获取信息的代码。)
- 消费者表(consumer): 指的是存储关于程序插桩代码信息的表。如果我们为查询模块添加插桩,相应的消费者表将记录如执行总数、未使用索引次数、耗时等信息。如图MySQL存在名为performance_schema的内置数据库,里面有各种数据表存储了有关MySQL内部运行的操作上的底层指标。

Performance Schema的一般功能如下图所示

当应用程序用户连接到MySQL并执行被测量的插桩指令时,performance_schema将每个检查的调用封装到两个宏中,然后将结果记录在相应的消费者表中。这里的要点是,启用插桩会调用额外的代码,这意味着插桩会消耗CPU资源
1.1 插桩元件
在这里插桩元件可以理解为收集信息的组件(也就是 数据生产者 ),是插入的“桩”与“桩的底座”的组合元件,每一个组件都代表着一些代码(收集信息的代码)。 在performance_schema库的setup_instruments表中包含MySQL所有的插桩组件。
MySQL官方手册setup_instruments表介绍
-- setup_instruments表信息
mysql> SELECT * FROM performance_schema.setup_instruments where DOCUMENTATION is not null limit 5,5\G;
*************************** 1. row ***************************
NAME: wait/synch/mutex/refcache/refcache_channel_mutex
ENABLED: NO
TIMED: NO
PROPERTIES:
VOLATILITY: 0
DOCUMENTATION: A mutex to guard access to the channels list
*************************** 2. row ***************************
NAME: wait/synch/rwlock/pfs/LOCK_pfs_tls_channels
ENABLED: NO
TIMED: NO
PROPERTIES: singleton
VOLATILITY: 0
DOCUMENTATION: This lock protects list of instrumented TLS channels.
*************************** 3. row ***************************
NAME: statement/sql/error
ENABLED: YES
TIMED: YES
PROPERTIES:
VOLATILITY: 0
DOCUMENTATION: Invalid SQL queries (syntax error).
*************************** 4. row ***************************
NAME: statement/abstract/Query
ENABLED: YES
TIMED: YES
PROPERTIES: mutable
VOLATILITY: 0
DOCUMENTATION: SQL query just received from the network. At this point, the real statement type is unknown, the type will be refined after SQL parsing.
*************************** 5. row ***************************
NAME: statement/abstract/new_packet
ENABLED: YES
TIMED: YES
PROPERTIES: mutable
VOLATILITY: 0
DOCUMENTATION: New packet just received from the network. At this point, the real command type is unknown, the type will be refined after reading the packet header.
NAME列: 组件名称构成: [插桩类型 /通用系统/子系统/孙系统/…], 例如 statement/sql/select 表示 statement类型sql系统下的select,select是sql子系统的一部分,属于statement类型。
DOCUMENTATION列: 由上面查询结果可见setup_instruments表有一个DOCUMENTATION列,包含详细信息。但许多插桩而言,该列可能为空,因此需要根据插桩的名称、你的直觉以及对MySQL源代码的认识来理解特定插桩检查的内容。
1.2 消费者表的分类
正如前面提到的,消费者表是插桩发送信息的目的地。结果存储在performance_schema数据库的多个表中;在MySQL 8.0.25社区版的performance_schema中由110个消费者表。基于它们的用途,大概可分为以下几个类别。
当前和历史数据 __history和history_long表的大小是可配置的
表名 存放数据类型 *_current 当前服务器上进行中的事件 *_history 每个线程最近完成的10个事件 *_history_long 从全局来看,每个线程最近完成的10000个事件 events_waits 底层服务器等待,例如获取互斥对象 events_statements SQL查询语句 events_stages 配置文件信息,例如创建临时表或发送数据 events_transactions 事务 
汇总表和摘要
汇总表 存储的是有关数据的统计信息,
例如,memory_summary_by_thread_by_event_name表保存了用户连接或任何后台线程的每个MySQL线程的内存聚合结果。摘要 是一种通过删除查询中的变量来聚合查询的方法。
例如以下查询:SELECT user,birthdate FROM users WHERE user_id=19;
SELECT user,birthdate FROM users WHERE user_id=13;
SELECT user,birthdate FROM users WHERE user_id=27;
该查询的摘要是:
SELECT user,birthdate FROM users WHERE user_id=?;
这允许Performance Schema跟踪摘要的延迟等指标,而无须单独保留 查询的每个变体。
实例表(Instance)
实例是指对象实例,用于MySQL安装程序。例如,file_instances表包含文件名和访问这些文件的线程数。设置表(Setup)
设置表用于performance_schema的运行时设置。
其他表
还有一些表的名称没有遵循严格的模式。例如,metadata_locks表保存关于元数据锁的数据。在本章后面讨论performance_schema可以解决的问题时,将介绍其中几个表。
1.3 资源消耗
消费者表使用的内存量可以设置。performance_schema中的一些表支持自动伸缩,这意味着它们在启动时分配最小数量的内存,并根据需要调整其大小。然而,一旦分配了内存,即使禁用了特定的插桩并截断了表,也不会再释放该内存。
如前所述,每个插桩指令的调用都会再添加两个宏调用,以将数据存储在performance_schema中。这意味着插桩越多,CPU的使用率就越高。对CPU使用率的实际影响取决于特定的插桩。例如,与statement相关的插桩在查询过程中只能被调用一次,而wait类插桩的被调用频率要高得多。例如,要扫描一个有一百万行的InnoDB表,引擎需要设置和释放一百万行锁。如果对锁使用wait类插桩,CPU使用率可能会显著增加。但是,同一查询本来就需要一次调用来确定是否是statement/sql/select。因此,如果启用statement类插桩,你不会注意到CPU负载的任何增加。内存或元数据锁类型的插桩也是如此。
1.4 局限性
它只在特定的插桩和用户启用后才收集数据。
例如,如果在禁用所有插桩的情况下启动服务器,然后决定检测内存使用情况,则无法知道全局缓冲区(如InnoDB缓冲池)分配的确切数量,因为在启用内存插桩之前已分配了该缓冲区。 (就像csdn个人主页的点赞数,如果你发了一篇文章之后才开启对你的数据统计,那么之前那篇文章的数据将统计不到。)
很难释放内存
可以在启动时限制消费者表的大小,也可以让其自动调整大小。在后一种情况下,它们不会在启动时分配内存,而是仅在收集启用的数据时分配内存。但是,即使以后禁用了特定的插桩或消费者表,也不会释放内存,除非重新启动服务器。
1.5 sys Schema
自5.7版以来,标准MySQL发行版包括一个和performance_schema数据配套使用的sys schema,它全部基于performance_schema上的视图和存储组成。它的设计目的是让performance_schema体验更加流畅 ,它本身并不存储任何数据。sys schema的使用非常方便,但需要记住 ,它只访问存储在performance_schema表中的数据。如果在sys schema中找不到你想看的数据,可尝试在performance_schema的基表中查找。
1.6 理解线程
MySQL服务端是多线程软件。它的每个组件都使用线程。例如,由主线程或存储引擎创建的,也可以是为用户连接创建的前台线程。每个线程至少有两个唯一标识符:一个是操作系统线程ID,另一个是MySQL内部线程ID。操作系统线程ID可以通过相关工具查看,如在Linux系统中可使用ps-eLf命令查看。而MySQL内部线程ID在大多数performance_schema表中以THREAD_ID命名。此外,每个前台线程都有一个指定的PROCESSLIST_ID
注意:THREAD_ID不等于PROCESSLIST_ID!
performance_schema中的threads表包含了服务器中存在的所有线程:
mysql> SELECT NAME, THREAD_ID, PROCESSLIST_ID, THREAD_OS_ID FROM performance_schema. threads;
+---------------------------------------------+-----------+----------------+--------------+
| NAME | THREAD_ID | PROCESSLIST_ID | THREAD_OS_ID |
+---------------------------------------------+-----------+----------------+--------------+
| thread/sql/main | 1 | NULL | 1 |
| thread/innodb/io_ibuf_thread | 3 | NULL | 369 |
| thread/innodb/io_log_thread | 4 | NULL | 370 |
| thread/innodb/io_read_thread | 5 | NULL | 371 |
| thread/innodb/io_read_thread | 6 | NULL | 372 |
| thread/innodb/io_read_thread | 7 | NULL | 373 |
| thread/innodb/io_read_thread | 8 | NULL | 374 |
| thread/innodb/io_write_thread | 9 | NULL | 375 |
| thread/innodb/io_write_thread | 10 | NULL | 376 |
| thread/innodb/io_write_thread | 11 | NULL | 377 |
| thread/innodb/io_write_thread | 12 | NULL | 378 |
| thread/innodb/page_flush_coordinator_thread | 13 | NULL | 379 |
| thread/innodb/log_checkpointer_thread | 14 | NULL | 380 |
| thread/innodb/log_flush_notifier_thread | 15 | NULL | 381 |
| thread/innodb/log_flusher_thread | 16 | NULL | 382 |
| thread/innodb/log_write_notifier_thread | 17 | NULL | 383 |
| thread/innodb/log_writer_thread | 18 | NULL | 384 |
| thread/innodb/log_files_governor_thread | 19 | NULL | 385 |
| thread/innodb/srv_lock_timeout_thread | 24 | NULL | 390 |
| thread/innodb/srv_error_monitor_thread | 25 | NULL | 391 |
| thread/innodb/srv_monitor_thread | 26 | NULL | 392 |
| thread/innodb/buf_resize_thread | 27 | NULL | 393 |
| thread/innodb/srv_master_thread | 28 | NULL | 394 |
| thread/innodb/dict_stats_thread | 29 | NULL | 395 |
| thread/innodb/fts_optimize_thread | 30 | NULL | 396 |
| thread/mysqlx/worker | 31 | NULL | 397 |
| thread/mysqlx/worker | 32 | NULL | 398 |
| thread/mysqlx/acceptor_network | 33 | NULL | 399 |
| thread/innodb/buf_dump_thread | 37 | NULL | 403 |
| thread/innodb/clone_gtid_thread | 38 | NULL | 404 |
| thread/innodb/srv_purge_thread | 39 | NULL | 405 |
| thread/innodb/srv_worker_thread | 40 | NULL | 406 |
| thread/innodb/srv_worker_thread | 41 | NULL | 407 |
| thread/innodb/srv_worker_thread | 42 | NULL | 408 |
| thread/sql/event_scheduler | 43 | 5 | 409 |
| thread/sql/signal_handler | 44 | NULL | 410 |
| thread/mysqlx/acceptor_network | 45 | NULL | 411 |
| thread/sql/compress_gtid_table | 47 | 7 | 413 |
| thread/sql/one_connection | 51 | 11 | 414 |
| thread/sql/one_connection | 52 | 12 | 425 |
+---------------------------------------------+-----------+----------------+--------------+
40 rows in set (0.11 sec)
注意: Performance Schema到处使用THREAD_ID,而PROCESSLIST_ID只在threads表中可用。如果需要获取PROCESSLIST_ID,例如,要杀死持有锁的连接,则需要查询threads表来获取。
2 Performance Schema - 配置
2.1 启用与禁用-Performance Schema
要启用或禁用Performance Schema,可以将变量performance_schema设置为ON或OFF。这是一个只读变量,要么在配置文件中更改,要么在MySQL服务器启动时通过命令行参数更改。
2.2 启用与禁用-插桩
通过setup_instruments表查看插桩的状态:
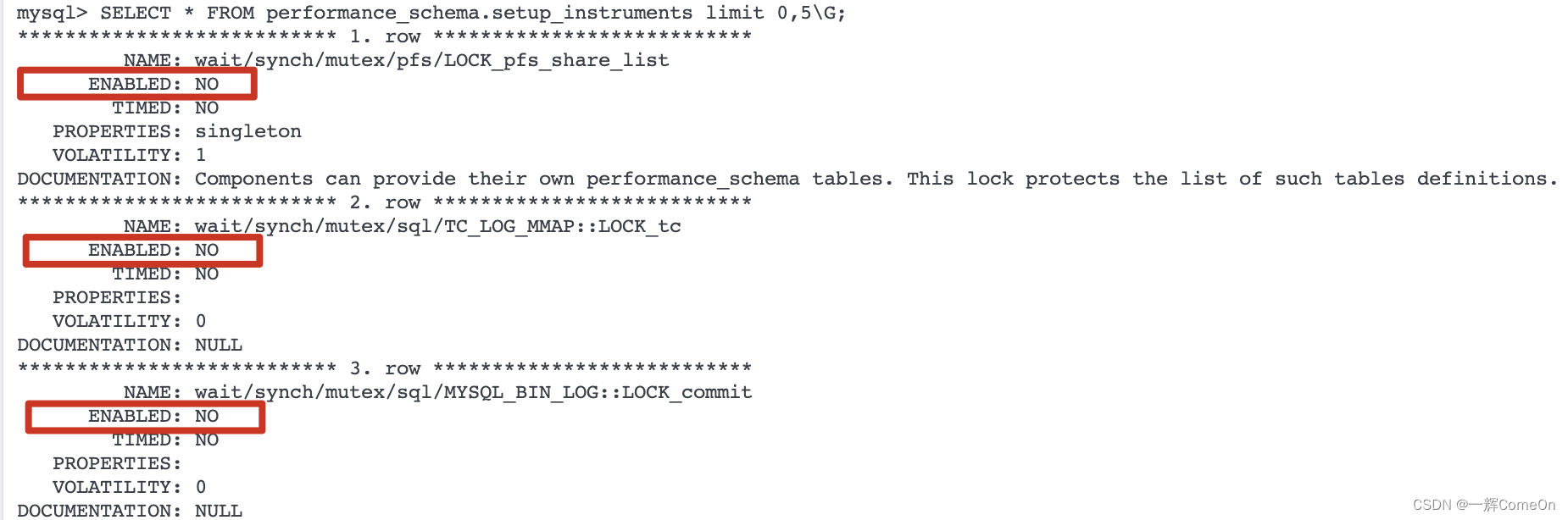
启用或禁用performance_schema插桩的三个方法:
直接修改setup_instruments表
使用这种方法设置的参数,在数据库重启后就会失效。
UPDATE performance_schema.setup_instruments
SET ENABLED = 'YES' WHERE NAME = 'stage/sql/starting'
也可以使用通配符来启用所有的SQL语句的插桩:
UPDATE performance_schema.setup_instruments
SET ENABLED = 'YES' WHERE NAME = 'stage/sql/%'
调用sys schema中的ps_setup_enable_instrument存储过程
使用这种方法设置的参数,在数据库重启后同样会失效。
也支持通配符匹配
MySQL通配符:
% 表示任何字符出现任意次数
_ 总是匹配一个字符# 打开
CALL sys.ps_setup_enable_instrument('stage/sql/%');
# 关闭
CALL sys.ps_setup_disable_instrument('stage/sql/%');
使用performance-schema-instrument启动参数
如前所述,两种方法都允许在线更改performance_schema配置,但是数据库重启之后配置就会失效。如果要在重启之后保留特定插桩的配置,需要使用performance-schema-instrument配置参数。
该方法同样支持通配符
performance-schema-instrument='statement/sql/select=ON'
如果指定了多个选项,则无论顺序如何,较长的插桩字符串优先于较短的插桩字符串。
2.3 启用与禁用-消费者表
与插桩一样,消费者表也可以通过以下三种方式启用或禁用:
- 使用Performance Schema中的setup_consumers表。
- 调用sys schema中的ps_setup_enable_consumer或ps_setup_disable_consuper存储过程。
- 使用performance-schema-consumer启动参数。
2.4 优化特定对象的监控
Performance Schema可以针对特定对象类型、schema和对象名称启用或禁用监控。这在setup_objects表中完成。对象类型(OBJECT_TYPE列)可以是下面的五个值之一:EVENT、FUNCTION、PROCEDURE、TABLE和TRIGGER。 此外,还可以指定OBJECT_SCHEMA和OBJECT_NAME,并且支持通配符。
例:关闭test数据库中触发器的performance_schema信息采集
INSERT INTO performance_schema.setup_objects
(OBJECT_TYPE, OBJECT_SCHEMA, OBJECT_NAME, ENABLED)
VALUES ('TRIGGER',"test','%', 'NO')
例:保留名为my_trigger的触发器的信息采集
INSERT INTO performance_schema.setup_objects
(OBJECT_TYPE, OBJECT_SCHEMA, OBJECT_NAME, ENABLED)
VALUES ('TRIGGER', "test', 'my_trigger', 'YES")
这些对象没有配置文件的选项。如果需要在重新启动后持久化更改,那么需要将这些INSERT语句写入SQL文件中,并在启动时使用init_file选项加载该SQL文件。
2.5 优化线程的监控
setup_threads表包含可以监控的后台线程
例: 要禁用事件调度程序(thread/sql/event_scheduler)的历史日志记录
mysql> UPDATE performance_schema.setup_threads SET HISTORY='NO'
-> WHERE NAME= 'thread/sql/event_scheduler';
用户线程的设置不在setup_threads表中,而是在setup_actors表中

例:启用了yihui@localhost和yihui@example.com的监测,禁用yihui@localhost的历史记录,并禁用从localhost连接的所有用户的监测和历史记录。
mysql> INSERT INTO performance_schema.setup_actors
-> (HOST, USER, ENABLED, HISTORY)
-> VALUES ('localhost', 'yihui', 'YES', 'NO'),
-> ('example.com', 'yihui', 'YES', 'YES"),
- >('localhost'. "%', 'NO', 'NO');
与对象监控一样,线程和actor都没有配置文件的选项。如果需要在重新启动后保留表中的更改,需要将这些INSERT语句写入SQL文件,并使用init_file选项在启动时加载该SQL文件。
2.6 调整Performance Schema的内存大小
默认情况下,某些performance_schema表会自动调整大小,其他的则有固定数量的行。可以通过更改启动变量来调整这些选项。变量的名称遵循p erformance_schema_object_[size|instances|classes|length|handles]的模式,其中对象要么是消费者表,要么是设置表,要么是特定事件的插桩实例
例:
- 配置变量performance_schema_events_stages_history_size定义了performance_schema_events_stages_history表将存储的每个线程的阶段数。
- 配置变量performance_schema_max_memory_classes定义了可以使用的最大内存插桩数量。
2.7 默认值
从5.7版开始,Performance Schema在默认情况下是启用的。大多数插桩默认是禁用的,只启用了全局、线程、语句和事务插桩。从8.0版本开始,默认情况下还启用了元数据锁和内存插桩。
mysql、information_schema和performance_schema数据库没有启用插桩,但所有其他对象、线程和actor都启用了插桩。
MySQL不同部分的默认值会随着版本的不同而改变,最好阅读一下官方的用户参考手册。
MySQL官方手册配置参数参考
3 Performance Schema - 使用
3.1 检查SQL语句
要启用语句检测,需要启用statement类型的插桩

常规SQL语句
Performance Schema将语句指标存储三个具有相同表结构的消费者表中:
- events_statements_current
- events_statements_history
- events_statements_history_long
--表结构示例
mysql> SELECT t.* FROM performance_schema.events_statements_history t limit 1\G;
*************************** 1. row ***************************
THREAD_ID: 53
EVENT_ID: 1
END_EVENT_ID: 1
EVENT_NAME: statement/sql/error
SOURCE: init_net_server_extension.cc:95
TIMER_START: 520801657566125000
TIMER_END: 520801673641250000
TIMER_WAIT: 16075125000
LOCK_TIME: 0
SQL_TEXT: select * from event_statement_history
DIGEST: NULL
DIGEST_TEXT: NULL
CURRENT_SCHEMA: NULL
OBJECT_TYPE: NULL
OBJECT_SCHEMA: NULL
OBJECT_NAME: NULL
OBJECT_INSTANCE_BEGIN: NULL
MYSQL_ERRNO: 1046
RETURNED_SQLSTATE: 3D000
MESSAGE_TEXT: No database selected
ERRORS: 1
WARNINGS: 0
ROWS_AFFECTED: 0
ROWS_SENT: 0
ROWS_EXAMINED: 0
CREATED_TMP_DISK_TABLES: 0
CREATED_TMP_TABLES: 0
SELECT_FULL_JOIN: 0
SELECT_FULL_RANGE_JOIN: 0
SELECT_RANGE: 0
SELECT_RANGE_CHECK: 0
SELECT_SCAN: 0
SORT_MERGE_PASSES: 0
SORT_RANGE: 0
SORT_ROWS: 0
SORT_SCAN: 0
NO_INDEX_USED: 0
NO_GOOD_INDEX_USED: 0
NESTING_EVENT_ID: NULL
NESTING_EVENT_TYPE: NULL
NESTING_EVENT_LEVEL: 0
STATEMENT_ID: 1064
CPU_TIME: 0
EXECUTION_ENGINE: PRIMARY
1 row in set (0.15 sec)
表中存储着相关SQL指标, MySQL官方手册events_statements_history表介绍,下面列出用于标识需要优化查询的指标的列。


具体使用方法:
例子:要找到所有没有使用合适索引的查询
SELECT THREAD_ID, SQL_TEXT, ROWS_SENT, ROWS_EXAMINED, CREATED_TMP_TABLES, NO_INDEX_USED, NO_GOOD_INDEX_USED
FROM performance_schema.events_statements_history_long
WHERE NO_INDEX_USED > 0 OR NO_GOOD_INDEX_USED > 0;
例子:要查询所有创建了临时表的查询
SELECT THREAD_ID, SQL_TEXT, ROWS_SENT, ROWS_EXAMINED, CREATED_TMP_TABLES,
CREATED_TMP_DISK_TABLES
FROM performance_schema.events_statements_history_long
WHERE CREATED_TMP_TABLES > 0 OR CREATED_TMP_DISK_TABLES > 0;
例子:要查询所有创建了临时表的查询 : errors > 0
例子:所有执行时间超过5秒的查询 : WHERE TIMER_WAIT >5000000000
例子:查找所有有问题的语句
WHERE ROWS_EXAMINED > ROWS_SENT
OR ROWS_EXAMINED > ROWS_AFFECTED
OR ERRORS > 0
OR CREATED_TMP_DISK_TABLES>0
OR CREATED_TMP_TABLES > 0 OR SELECT_FULL_JOIN > O
OR SELECT_FULL_RANGE_JOIN > 0
OR SELECT_RANGE > 0
OR SELECT_RANGE_CHECK > 0
OR SELECT_SCAN > 0
OR SORT_MERGE_PASSES > 0
OR SORT_RANGE > 0
OR SORT_ROWS > 0
OR SORT_SCAN > 0
OR NO_INDEX_USED > 0
OR NO_GOOD_INDEX_USED > 0
使用sys schema
sys库存储提供了可用于查找有问题语句的视图,如
statements_with_errors_or_warnings带有错误和警告的所有语句
statements_with_full_table_scans需要全表扫描的所有语句
--实例
mysql> SELECT * FROM sys.statements_with_full_table_scans limit 1\G;
*************************** 1. row ***************************
query: SELECT NAME , `THREAD_ID` , `P ... erformance_schema` . `threads`
db: NULL
exec_count: 1
total_latency: 98.90 ms
no_index_used_count: 1
no_good_index_used_count: 0
no_index_used_pct: 100
rows_sent: 40
rows_examined: 40
rows_sent_avg: 40
rows_examined_avg: 40
first_seen: 2022-12-19 14:18:25.767134
last_seen: 2022-12-19 14:18:25.767134
digest: f5c06d085a26ef1641bf27f0536ed71a467ca15a2215da1fbe0d3150cf17a909
1 row in set (0.07 sec)
其他可以用来查找需要优化的语句的视图:

预处理语句
prepared_statements_instances表包含服务器中存在的所有预处理语句。
它和events_statements_[current|history|history_long]表有相同的统计数据,此外还有关于预处理语句所属的线程以及该语句被执行了多少次的信息。
和events_statements_[current|history|history_long]表不同的是,统计数据是累加的,这个表包含所有语句执行的总量。
启用预处理语句检测的插桩

一旦启用预处理语句功能,一个预处理好的语句就可以多次执行:
mysql> prepare stmt FROM 'select count(*) from test_schema.students where age>?';
Query OK, 0 rows affected (0.39 sec)
Statement prepared
mysql> SET @age = 18;
Query OK, 0 rows affected (0.03 sec)
mysql> EXECUTE stmt USING @age;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.08 sec)
查看诊断结果
mysql> select * from performance_schema.prepared_statements_instances\G;
*************************** 1. row ***************************
OBJECT_INSTANCE_BEGIN: 108782192
STATEMENT_ID: 2
STATEMENT_NAME: stmt
SQL_TEXT: select count(*) from test_schema.students where age>?
OWNER_THREAD_ID: 61
OWNER_EVENT_ID: 2
OWNER_OBJECT_TYPE: NULL
OWNER_OBJECT_SCHEMA: NULL
OWNER_OBJECT_NAME: NULL
EXECUTION_ENGINE: PRIMARY
TIMER_PREPARE: 361987667000
...
一旦预处理语句被删除,就不能再访问这些统计信息了
mysql> DROP PREPARE stmt;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from performance_schema.prepared_statements_instances\G;
Empty set (0.04 sec)
ERROR:
No query specified
存储过程
使用performance_schema可以检索有关存储过程如何执行的信息:例如,IF…ELSE流控制语句的哪个分支被选择了,或者是否调用了错误处理程序。
--实例
CREATE DEFINER='root'@'localhost' PROCEDURE sp_test(val int)
BEGIN
# 1062是主键重复的错误码
DECLARE CONTINUE HANDLER FOR 1062
BEGIN
INSERT IGNORE INTO test_schema.students VALUES(null,'error string',19);
GET STACKED DIAGNOSTICS CONDITION 1 @stacked_state = RETURNED_SQLSTATE;
GET STACKED DIAGNOSTICS CONDITION 1 @stacked_msg = MESSAGE_TEXT;
END;
INSERT INTO test_schema.students VALUES(val,'success',18);
END;
mysql> call sp_test(1);
Query OK, 1 row affected (0.02 sec)
mysql> SELECT THREAD_ID,EVENT_NAME,SQL_TEXT
-> FROM performance_schema.events_statements_history
-> WHERE EVENT_NAME like 'statement/sp%';
+-----------+-------------------------+-----------------------------------------------------------+
| THREAD_ID | EVENT_NAME | SQL_TEXT |
+-----------+-------------------------+-----------------------------------------------------------+
| 58 | statement/sp/hpush_jump | NULL |
| 58 | statement/sp/stmt | INSERT INTO test_schema.students VALUES(val,'success',18) |
| 58 | statement/sp/hpop | NULL |
+-----------+-------------------------+-----------------------------------------------------------+
3 rows in set (0.04 sec)
重复插入
mysql> call sp_test(1);
Query OK, 1 row affected (0.06 sec)
mysql> SELECT THREAD_ID,EVENT_NAME,SQL_TEXT
-> FROM performance_schema.events_statements_history
-> WHERE EVENT_NAME like 'statement/sp%';
+-----------+-------------------------+-------------------------------------------------------------------------+
| THREAD_ID | EVENT_NAME | SQL_TEXT |
+-----------+-------------------------+-------------------------------------------------------------------------+
| 58 | statement/sp/hpush_jump | NULL |
| 58 | statement/sp/stmt | INSERT INTO test_schema.students VALUES(val,'success',18) |
| 58 | statement/sp/stmt | INSERT IGNORE INTO test_schema.students VALUES(null,'error string',19) |
| 58 | statement/sp/stmt | GET STACKED DIAGNOSTICS CONDITION 1 @stacked_state = RETURNED_SQLSTATE |
| 58 | statement/sp/stmt | GET STACKED DIAGNOSTICS CONDITION 1 @stacked_msg = MESSAGE_TEXT |
| 58 | statement/sp/hreturn | NULL |
| 58 | statement/sp/hpop | NULL |
+-----------+-------------------------+-------------------------------------------------------------------------+
7 rows in set (0.03 sec)
该表设计为主键自增,数据库有两次存储记录。

在第二次调用中,events_statements_history表的内容是不同的:包含了来自错误处理程序和替换错误的SQL语句的调用。理解存储过程执行流中的这些差异有助于理解为什么同一个存储过程连续调用时速度差异大的问题。
语句剖析
events_stages_[current|history|history_long]表包含剖析信息,例如MySQL在创建临时表、更新或等待锁时花费了多少时间。要启用剖析,需要启用上述消费者表以及匹配’stage/%'模式的插桩。启用后可以找到类似“查询执行的哪个阶段(步骤)花费了非常长的时间”等问题的答案。
例:搜索耗时超过1秒的阶段(步骤)
SELECT eshl. event_name, sql_text, eshl.timer_wait/10000000000 W_S
FROM performance_schema.events_stages_history_long eshl
JOIN performance_schema.events_statements_history_long esthl
ON (eshl.nesting_event_id = esthl.event_id)
WHERE eshl. timer_wait > 1*10000000000
代表不同性能问题的阶段(步骤)

3.2 检查读写性能
Performance Schema中的statement类型的插桩对于理解工作负载是受读还是受写限制非常有用。可以从统计各类型语句的执行量入手:
SELECT EVENT_NAME, COUNT(EVENT_NAME)
FROM events_statements_history_long
GROUP BY EVENT_NAME
按LOCK_TIME列进行聚合:
mysql> SELECT EVENT_NAME,
-> COUNT(EVENT_NAME),
-> SUM(LOCK_TIME/1000000) AS latency_ms
-> FROM `performance_schema`.events_statements_history
-> GROUP BY EVENT_NAME ORDER BY latency_ms DESC;
+------------------------------+-------------------+------------+
| EVENT_NAME | COUNT(EVENT_NAME) | latency_ms |
+------------------------------+-------------------+------------+
| statement/sql/select | 13 | 1385.0000 |
| statement/sql/show_status | 9 | 398.0000 |
| statement/sp/stmt | 3 | 313.0000 |
| statement/sql/show_tables | 1 | 87.0000 |
| statement/sql/show_keys | 2 | 84.0000 |
| statement/sql/show_fields | 1 | 35.0000 |
| statement/sql/set_option | 2 | 0.0000 |
| statement/com/Init DB | 5 | 0.0000 |
| statement/sql/error | 1 | 0.0000 |
| statement/sp/hreturn | 1 | 0.0000 |
| statement/sp/hpop | 1 | 0.0000 |
| statement/sql/call_procedure | 1 | 0.0000 |
+------------------------------+-------------------+------------+
12 rows in set (0.03 sec)
如果还想知道读取和写入的字节数和行数,可以使用全局状态变量Handler_*:
WITH rows_read AS
(SELECT SUM(VARIABLE_VALUE) AS rows_read
FROM global_status
WHERE VARIABLE_NAME IN ('Handler_read_first',
'Handler_read_key',
'Handler read next',
'Handler_read_last', 'Handler_read_prev',
'Handler read rnd',
'Handler_read_rnd_next')
),
rows_written AS (SELECT SUM(VARIABLE_VALUE) AS rows_written
FROM global_status
WHERE VARIABLE_NAME IN ('Handler write'))
SELECT * FROM rows_read, rows_written
3.3 检查元数据锁
元数据锁用于保护数据库对象定义不被修改。执行任何SQL语句都需要获取共享元数据锁.
performance_schema中的metadata_locks表包含关于当前由不同线程设置的锁的信。
要启用元数据锁监测,需要启用wait/lock/meta-data/sql/mdl插桩。
3.4 检查内存使用情况
要在performance_schema中启用内存监测,请启用memory类的插桩。
直接使用performance schema
Performance Schema将内存使用统计信息存储在摘要表中,摘要表的名称以memory_summary_前缀开头。

内存使用聚合统计,其参数如图:

例:要找到占用大部分内存的InnoDB结构
mysql> SELECT EVENT_NAME, CURRENT_NUMBER_OF_BYTES_USED/1024/1024 AS CURRENT_MB, HIGH_NUMBER_OF_BYTES_USED/1024/1024 AS HIGH_MB
-> FROM performance_schema.memory_summary_global_by_event_name
-> WHERE EVENT_NAME LIKE 'memory/innodb/%'
-> ORDER BY CURRENT_NUMBER_OF_BYTES_USED DESC LIMIT 10;
+---------------------------------+--------------+--------------+
| EVENT_NAME | CURRENT_MB | HIGH_MB |
+---------------------------------+--------------+--------------+
| memory/innodb/buf_buf_pool | 130.87890625 | 130.87890625 |
| memory/innodb/ut0link_buf | 24.00006104 | 24.00006104 |
| memory/innodb/log_buffer_memory | 16.00096130 | 16.00096130 |
| memory/innodb/sync0arr | 7.03147125 | 7.03147125 |
| memory/innodb/lock0lock | 4.85086060 | 4.85086060 |
| memory/innodb/ut0pool | 4.00017548 | 4.00017548 |
| memory/innodb/memory | 2.64964294 | 2.93302917 |
| memory/innodb/os0file | 2.60480499 | 2.60480499 |
| memory/innodb/os0event | 0.86042786 | 0.86042786 |
| memory/innodb/std | 0.47849274 | 0.48062134 |
+---------------------------------+--------------+--------------+
10 rows in set (0.02 sec)
使用sys schema
使用Sys schema中的视图可以更好地获取内存统计信息,可以按host、user、thread或global进行聚合。memory_global_total视图包含一个单独的值,显示被监测内存的总量:
mysql> select * from sys.memory_global_total;
+-----------------+
| total_allocated |
+-----------------+
| 456.91 MiB |
+-----------------+
1 row in set (0.06 sec)
视图memory_by_thread_by_current_bytes中的行是按照当前分配的内存降序排序的,所以很容易就能找到哪个线程占用了大部分内存:
mysql> select thread_id tid,user,
-> current_allocated,total_allocated
-> from sys.memory_by_thread_by_current_bytes limit 9;
+-----+--------------------------+-------------------+-----------------+
| tid | user | current_allocated | total_allocated |
+-----+--------------------------+-------------------+-----------------+
| 58 | root@localhost | 8.43 MiB | 254.05 MiB |
| 59 | root@172.17.0.1 | 1.72 MiB | 12.58 MiB |
| 55 | root@172.17.0.1 | 1.35 MiB | 145.91 MiB |
| 57 | root@172.17.0.1 | 1.25 MiB | 19.86 MiB |
| 1 | sql/main | 1.17 MiB | 5.19 MiB |
| 56 | root@172.17.0.1 | 1.17 MiB | 10.18 MiB |
| 60 | root@172.17.0.1 | 1.12 MiB | 2.10 MiB |
| 38 | innodb/clone_gtid_thread | 571.78 KiB | 15.74 MiB |
| 43 | sql/event_scheduler | 16.27 KiB | 16.27 KiB |
+-----+--------------------------+-------------------+-----------------+
9 rows in set (0.27 sec)
3.5 检查变量
Performance Schema将变量监测提升到了一个新的水平,将变量根据变量表分为以下几类:
●服务器变量
- 全局级
- 会话级,针对当前所有打开的会话
- 源,所有当前变量值的来源
●状态变量
- 全局级
- 会话级,针对当前所有打开的会话
- 聚合维度
- 主机
- 用户名
- 账号
- 线程
●用户变量
在5.7版本之前,服务器和状态变量是在information_schema中配置的。这种配置是有限制的:只允许跟踪全局和当前会话值。其他会话中关于变量和状态的信息,以及关于用户变量的信息,都是不可访问的。
但是,出于向后兼容的考虑,MySQL 5.7还是使用information_schema来跟踪变量。要启用performance_schema对变量跟踪的支持,需要将配置变量show_compatibility_56设置为0。这一要求以及information_schema中的变量表在8.0版中都不再存在。
global_variables表: 存储全局变量值
session_variables表: 存储当前会话的会话变量
variables_by_thread表: 存储线程变量
global_status表: 全局状态
session_status表: 当前会话状态值
user_variable_by_thread表: 用户自定义变量,这个表是找出用户的会话中定义了哪些变量的唯一方法。
variables_info表: 不包含变量值,包含服务器变量起源等信息,比如变量的默认值。
例:查找所有和当前会话变量值不同的线程和会话变量:
SELECT vt2.THREAD_ID AS TID,
vt2.VARIABLE_NAME,
vt1.VARIABLE_VALUE AS MY_VALUE,
vt2.VARIABLE_VALUE AS OTHER_VALUE
FROM performance_schema.variables_by_thread vt1
JOIN performance_schema.threads t USING(THREAD_ID)
JOIN performance_schema.variables_by_thread vt2 USING(VARIABLE_NAME)
WHERE vt1.VARIABLE_VALUE != vt2.VARIABLE_VALUE
AND t.PROCESSLIST_ID=@@pseudo_thread_id
-- pseudo_thread_id会话级系统变量表示当前绘画thread_id

状态变量可以按用户账户、主机、用户和线程聚合。最常用的是线程聚合,因为它允许快速识别哪个连接在服务器上造成了大部分资源压力。
例如,要查找自服务器启动以来动态更改的所有变量
mysql> SELECT * FROM performance_schema.variables_info
-> WHERE VARIABLE_SOURCE = 'DYNAMIC'\G;
*************************** 1. row ***************************
VARIABLE_NAME: foreign_key_checks
VARIABLE_SOURCE: DYNAMIC
VARIABLE_PATH:
MIN_VALUE: 0
MAX_VALUE: 0
SET_TIME: 2023-01-06 07:38:39.103612
SET_USER: NULL
SET_HOST: NULL
*************************** 2. row ***************************
VARIABLE_NAME: profiling
VARIABLE_SOURCE: DYNAMIC
VARIABLE_PATH:
MIN_VALUE: 0
MAX_VALUE: 0
SET_TIME: 2023-01-06 07:39:02.220396
SET_USER: root
SET_HOST: NULL
2 rows in set (0.04 sec)
VARIABLE_SOURCE的值:
- COMMAND_LINE: 在命令行中设置的变量。
- COMPILED: 编译的默认值。
- PERSISTED: 服务器指定的mysqld-auto.cnf选项文件中设置
变量也有许多选项,设置在不同的选项文件中。在这里不会全部讨论:它们要么是自描述性的,要么很容易在用户参考手册中查看。每个版本的细节数量也在增加。
3.6 检查最常见的错误
除了特定错误信息,performance_schema还提供摘要表,可以按用户、主机、账户、线程和错误号聚合错误信息。所有的聚合表都有类似于events_errors_summary_global_by_error表的结构:
mysql> SHOW CREATE TABLE events_errors_summary_global_by_error\G;
*************************** 1. row ***************************
Table: events_errors_summary_global_by_error
Create Table: CREATE TABLE `events_errors_summary_global_by_error` (
`ERROR_NUMBER` int DEFAULT NULL,
`ERROR_NAME` varchar(64) DEFAULT NULL,
`SQL_STATE` varchar(5) DEFAULT NULL,
-- 错误发生的次数
`SUM_ERROR_RAISED` bigint unsigned NOT NULL,
-- 错误被处理的次数
`SUM_ERROR_HANDLED` bigint unsigned NOT NULL,
-- 错误第一次发生时间戳
`FIRST_SEEN` timestamp NULL DEFAULT NULL,
-- 最后一次发生的时间戳
`LAST_SEEN` timestamp NULL DEFAULT NULL,
UNIQUE KEY `ERROR_NUMBER` (`ERROR_NUMBER`)
) ENGINE=PERFORMANCE_SCHEMA DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
有些聚合表有额外的列。表events_errors_summary_by_thread_by_error有一个名为THREAD_ID的列,标识了引发错误的线程,表events_errors_summary_by_host_by_error有一个名为HOST的列,依此类推。
例: 要查找所有运行语句发生错误超过10次的账户
mysql> SELECT * FROM
-> performance_schema.events_errors_summary_by_account_by_error
-> WHERE SUM_ERROR_RAISED > 10 AND USER IS NOT NULL
-> ORDER BY SUM_ERROR_RAISED DESC\G;
*************************** 1. row ***************************
USER: root
HOST: localhost
ERROR_NUMBER: 1287
ERROR_NAME: ER_WARN_DEPRECATED_SYNTAX
SQL_STATE: HY000
SUM_ERROR_RAISED: 111
SUM_ERROR_HANDLED: 0
FIRST_SEEN: 2023-01-06 07:56:11
LAST_SEEN: 2023-01-06 07:56:11
*************************** 2. row ***************************
USER: root
HOST: 172.17.0.1
ERROR_NUMBER: 1287
ERROR_NAME: ER_WARN_DEPRECATED_SYNTAX
SQL_STATE: HY000
SUM_ERROR_RAISED: 16
SUM_ERROR_HANDLED: 0
FIRST_SEEN: 2023-01-06 07:39:02
LAST_SEEN: 2023-01-06 08:07:18
...
错误摘要表可用于找出哪些账号、主机、用户或线程发送错误最多的查询并执行操作。还可以帮助解决诸如ER_DEPRECATED_UTF8_ALIAS之类的错误,这可能表明一些常用的查询是为以前的MySQL版本编写的,需要更新。
3.7 检查Performance Schema自身
可以使用相同的插桩和消费者表来检查Performance Schema本身。请注意,默认情况下,如果Performance_schema被设为默认数据库,则不会跟踪对它的查询。如果需要检查对performance_schema的查询,则需要首先更新setup_actors表。
要找到performance_schema中消耗内存最多的10个表
mysql> SELECT SUBSTRING_INDEX(EVENT_NAME, '/', -1) AS EVENT,
-> CURRENT_NUMBER_OF_BYTES_USED/1024/1024 AS CURRENT_MB,
-> HIGH_NUMBER_OF_BYTES_USED/1024/1024 AS HIGH_MB
-> FROM performance_schema.memory_summary_global_by_event_name
-> WHERE EVENT_NAME LIKE 'memory/performance_schema/%'
-> ORDER BY CURRENT_NUMBER_OF_BYTES_USED DESC LIMIT 10\G;
*************************** 1. row ***************************
EVENT: events_statements_summary_by_digest
CURRENT_MB: 40.28320313
HIGH_MB: 40.28320313
*************************** 2. row ***************************
EVENT: events_statements_history_long
CURRENT_MB: 14.19067383
HIGH_MB: 14.19067383
*************************** 3. row ***************************
EVENT: events_errors_summary_by_thread_by_error
CURRENT_MB: 12.42578125
HIGH_MB: 12.42578125
*************************** 4. row ***************************
EVENT: events_statements_summary_by_thread_by_event_name
CURRENT_MB: 10.69335938
HIGH_MB: 10.69335938
...
使用sys schema可以获取同样的信息:
mysql> SELECT SUBSTRING_INDEX(event_name, '/', -1), current_alloc
-> FROM sys.memory_global_by_current_bytes
-> WHERE event_name LIKE 'memory/performance_schema/%' LIMIT 10;
+---------------------------------------------------+---------------+
| SUBSTRING_INDEX(event_name, '/', -1) | current_alloc |
+---------------------------------------------------+---------------+
| events_statements_summary_by_digest | 40.28 MiB |
| events_statements_history_long | 14.19 MiB |
| events_errors_summary_by_thread_by_error | 12.43 MiB |
| events_statements_summary_by_thread_by_event_name | 10.69 MiB |
| events_statements_summary_by_digest.digest_text | 9.77 MiB |
| events_statements_history_long.digest_text | 9.77 MiB |
| events_statements_history_long.sql_text | 9.77 MiB |
| memory_summary_by_thread_by_event_name | 7.91 MiB |
| events_errors_summary_by_host_by_error | 6.21 MiB |
| events_errors_summary_by_user_by_error | 6.21 MiB |
+---------------------------------------------------+---------------+
10 rows in set (0.03 sec)
使用SHOW ENGINE PERFORMANCE_SCHEMA STATUS语句获取performance_schema的相关信息:
mysql> SHOW ENGINE PERFORMANCE_SCHEMA STATUS;
+--------------------+-------------------------------------------------------------+-----------+
| Type | Name | Status |
+--------------------+-------------------------------------------------------------+-----------+
| performance_schema | events_waits_current.size | 176 |
| performance_schema | events_waits_current.count | 1536 |
| performance_schema | events_waits_history.size | 176 |
| performance_schema | events_waits_history.count | 2560 |
| performance_schema | events_waits_history.memory | 450560 |
| performance_schema | events_waits_history_long.size | 176 |
| performance_schema | events_waits_history_long.count | 10000 |
| performance_schema | events_waits_history_long.memory | 1760000 |
| performance_schema | (pfs_mutex_class).size | 256 |
| performance_schema | (pfs_mutex_class).count | 350 |
| performance_schema | (pfs_mutex_class).memory | 89600 |
| performance_schema | (pfs_rwlock_class).size | 256 |
| performance_schema | (pfs_rwlock_class).count | 60 |
| performance_schema | (pfs_rwlock_class).memory | 15360 |
| performance_schema | (pfs_cond_class).size | 256 |
| performance_schema | (pfs_cond_class).count | 150 |
| performance_schema | (pfs_cond_class).memory | 38400 |
| performance_schema | (pfs_thread_class).size | 256 |
| performance_schema | (pfs_thread_class).count | 100 |
| performance_schema | (pfs_thread_class).memory | 25600 |
| performance_schema | (pfs_file_class).size | 320 |
| performance_schema | (pfs_file_class).count | 80 |
...
在输出中可以发现一些细节,比如消费者表中存储了多少特定事件,或者特定量的最大值。最后一列包含Performance Schema当前占用的字节数。
小结
Performance Schema是一个经常受到批评的特性。早期版本的MySQL对其的实现不够理想,导致资源消耗较高。通常的建议是干脆关掉它。
通常它也被认为是难以理解的。其实它只是启用了一些插桩代码,这些代码用于记录数据并将其提交给消费者表。消费者表是一些内存表,需要使用标准SQL语句查询数据,获取信息。了解了Performance Schema如何管理自己的内存后,你就能认识到MySQL并没有泄漏内存,它只是将消费者数据保存在内存中,这些内存只有在MySQL重启时才会释放。
在这里建议应该启用Performance Schema,按需动态地启用插桩和消费者表,通过它们提供的数据可以解决可能存在的任何问题——查询性能、锁定、磁盘I/O、错误等。充分利用sys schema是解决常见问题的捷径。这样做将为你提供一种可以直接从MySQL中测量性能的方法。
MySQL性能调优必知:Performance Schema引擎的配置与使用的更多相关文章
- MySQL性能调优与架构设计——第10章 MySQL数据库Schema设计的性能优化
第10章 MySQL Server性能优化 前言: 本章主要通过针对MySQL Server(mysqld)相关实现机制的分析,得到一些相应的优化建议.主要涉及MySQL的安装以及相关参数设置的优化, ...
- MySQL性能调优与架构设计——第9章 MySQL数据库Schema设计的性能优化
第9章 MySQL数据库Schema设计的性能优化 前言: 很多人都认为性能是在通过编写代码(程序代码或者是数据库代码)的过程中优化出来的,其实这是一个非常大的误区.真正影响性能最大的部分是在设计中就 ...
- MySQL性能调优与架构设计——第8章 MySQL数据库Query的优化
第8章 MySQL数据库Query的优化 前言: 在之前“影响 MySQL 应用系统性能的相关因素”一章中我们就已经分析过了Query语句对数据库性能的影响非常大,所以本章将专门针对 MySQL 的 ...
- MySQL性能调优与架构设计——第4章 MySQL安全管理
第4章 MySQL安全管理 前言 对于任何一个企业来说,其数据库系统中所保存数据的安全性无疑是非常重要的,尤其是公司的有些商业数据,可能数据就是公司的根本,失去了数据的安全性,可能就是失去了公司的一切 ...
- MySQL 性能调优
MySQL 性能调优 索引 索引是什么 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里,不用一页一页查阅找出需要的资料. 索引目的 ...
- MySQL性能优化总结___本文乃《MySQL性能调优与架构设计》读书笔记!
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- MySql(十一):MySQL性能调优——常用存储引擎优化
一.前言 MySQL 提供的非常丰富的存储引擎种类供大家选择,有多种选择固然是好事,但是需要我们理解掌握的知识也会增加很多.本章将介绍最为常用的两种存储引擎进行针对性的优化建议. 二.MyISAM存储 ...
- MySQL性能调优与架构设计——第 18 章 高可用设计之 MySQL 监控
第 18 章 高可用设计之 MySQL 监控 前言: 一个经过高可用可扩展设计的 MySQL 数据库集群,如果没有一个足够精细足够强大的监控系统,同样可能会让之前在高可用设计方面所做的努力功亏一篑.一 ...
- MySQL性能调优与架构设计——第 14 章 可扩展性设计之数据切分
第 14 章 可扩展性设计之数据切分 前言 通过 MySQL Replication 功能所实现的扩展总是会受到数据库大小的限制,一旦数据库过于庞大,尤其是当写入过于频繁,很难由一台主机支撑的时候,我 ...
- MySQL性能调优与架构设计——第11章 常用存储引擎优化
第11章 常用存储引擎优化 前言: MySQL 提供的非常丰富的存储引擎种类供大家选择,有多种选择固然是好事,但是需要我们理解掌握的知识也会增加很多.每一种存储引擎都有各自的特长,也都存在一定的短处. ...
随机推荐
- 轻松玩转 JMeter 测试计划组件
轻松玩转 JMeter 测试计划组件 宝子们,今天咱就来唠唠 JMeter 里那个超重要的测试计划组件,它可是整个性能测试的 "指挥官",把各种测试元素安排得明明白白. 一.测试计 ...
- [源码阅读]-Redis核心事件流程
Redis核心流程 本文分析基于Redis-1.0源码,核心流程代码主要分布在redis.c,ae.c两个文件中. Notion版本 1.Redis核心流程中的重要数据结构 struct redisS ...
- 2020年最新消息中间件MQ与RabbitMQ面试题-copy
为什么使用MQ?MQ的优点 简答 异步处理 - 相比于传统的串行.并行方式,提高了系统吞吐量. 应用解耦 - 系统间通过消息通信,不用关心其他系统的处理. 流量削锋 - 可以通过消息队列长度控制请求量 ...
- 2025高级java面试精华及复习方向总结
1. Java基础 顶顶顶顶的点点滴滴 1.1 java集合关系结构图 1.2 如何保证ArrayList的线程安全 方法一: 使用 Collections 工具类中的 synchronizedLis ...
- Assignment pg walkthrough Easy 通配符提权变种
nmap 扫描 ┌──(root㉿kali)-[~] └─# nmap -p- -A 192.168.157.224 Starting Nmap 7.94SVN ( https://nmap.org ...
- VulNyx - System
扫描发现 2121是ftp端口 8000 http的一个端口 6379redis端口 爆破redis的密码 爆破出来时bonjour 猜测ftp的密码和redis的密码是一样的 尝试用密码去爆出ftp ...
- C# 10个常用特性
感谢一傻小冲的分享 https://www.cnblogs.com/liyichong/p/5434309.html 觉得很实用就搬抄一份收藏,上了年纪记忆力不好了. 1) async / await ...
- Sdcb Chats 技术博客:数据库 ID 选型的曲折之路 - 从 Guid 到自增 ID,再到 Guid
Sdcb Chats 技术博客:数据库 ID 选型的曲折之路 - 从 Guid 到自增 ID,再到 Guid 在软件开发中,数据库主键的选择,Guid 还是自增整数 ID,一直是一个备受开发者关注和讨 ...
- uni-app之vuex(一)
如何获取到vuex中data的值 uni-app中内置了 vuex 所以可以直接去使用哈. 在项目的跟目录下 创建文件夹store 在store目录下创建index.js index.js目录如下 i ...
- AI编程:Coze + Cursor实现一个思维导图的浏览器插件
这是小卷对AI编程工具学习的第3篇文章,今天以实际开发一个思维导图的需求为例,了解AI编程开发的整个过程 1.效果展示 2.AI编程开发流程 虽然AI编程知识简单对话就行,不过咱要逐步深入到项目开发中 ...