Elastic-Job快速入门
1 Elastic-Job快速入门
1.1 环境搭建
1.1.1.版本要求
JDK要求1.7及以上版本
Maven要求3.0.4及以上版本
zookeeper要求采用3.4.6及以上版本
1.1.2.Zookeeper安装&运行
https://archive.apache.org/dist/zookeeper/ 下载某版本Zookeeper,并解压。
安装可以查看博客:https://www.cnblogs.com/dalianpai/p/12057064.html
1.1.3.创建maven工程
创建maven工程elastic-job-quickstart,并导入以下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency> <!-- https://mvnrepository.com/artifact/com.dangdang/elastic-job-lite-core -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>2.1.5</version>
</dependency> <dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
1.2 代码实现
1.2.1.编写定时任务类
此任务在每次执行时获取一定数目的文件,进行备份处理,由File实体类的backedUp属性来标识该文件是否已备
份
public class FileBackupJob implements SimpleJob {
//每次任务执行要备份文件的数量
private final int FETCH_SIZE = 1;
//文件列表(模拟)
public static List<FileCustom> files = new ArrayList<>();
//任务执行代码逻辑
@Override
public void execute(ShardingContext shardingContext) {
System.out.println("作业分片:"+shardingContext.getShardingItem());
//获取未备份的文件
List<FileCustom> fileCustoms = fetchUnBackupFiles(FETCH_SIZE);
//进行文件备份
backupFiles(fileCustoms);
}
/**
* 获取未备份的文件
* @param count 文件数量
* @return
*/
public List<FileCustom> fetchUnBackupFiles(int count){
//获取的文件列表
List<FileCustom> fileCustoms = new ArrayList<>();
int num=0;
for(FileCustom fileCustom:files){
if(num >=count){
break;
}
if(!fileCustom.getBackedUp()){
fileCustoms.add(fileCustom);
num ++;
}
}
System.out.printf("time:%s,获取文件%d个\n", LocalDateTime.now(),num);
return fileCustoms;
}
/**
* 文件备份
* @param files
*/
public void backupFiles(List<FileCustom> files){
for(FileCustom fileCustom:files){
fileCustom.setBackedUp(true);
System.out.printf("time:%s,备份文件,名称:%s,类型:%s\n", LocalDateTime.now(),fileCustom.getName(),fileCustom.getType());
}
}
}
文件实体类如下:
@Data
public class FileCustom {
/**
* 标识
*/
private String id; /**
* 文件名
*/
private String name; /**
* 文件类型,如text、image、radio、vedio
*/
private String type; /**
* 文件内容
*/
private String content; /**
* 是否已备份
*/
private Boolean backedUp = false; public FileCustom(String id,String name,String type,String content){
this.id = id;
this.name = name;
this.type = type;
this.content = content;
}
}
public class JobMain {
//zookeeper端口
private static final int ZOOKEEPER_PORT = 2181;
//zookeeper链接字符串 localhost:2181
private static final String ZOOKEEPER_CONNECTION_STRING = "192.168.180.113:" + ZOOKEEPER_PORT;
//定时任务命名空间
private static final String JOB_NAMESPACE = "elastic-job-example-java";
//执行启动任务
public static void main(String[] args) {
//制造一些测试数据
generateTestFiles();
//配置注册中心
CoordinatorRegistryCenter registryCenter = setUpRegistryCenter();
//启动任务
startJob(registryCenter);
}
//zk的配置及创建注册中心
private static CoordinatorRegistryCenter setUpRegistryCenter(){
//zk的配置
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(ZOOKEEPER_CONNECTION_STRING, JOB_NAMESPACE);
//减少zk超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
//创建注册中心
CoordinatorRegistryCenter zookeeperRegistryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
zookeeperRegistryCenter.init();
return zookeeperRegistryCenter;
}
//任务的配置和启动
private static void startJob(CoordinatorRegistryCenter registryCenter){
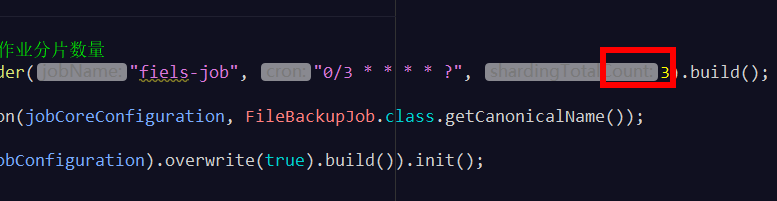
//String jobName 任务名称, String cron 调度表达式, int shardingTotalCount 作业分片数量
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration.newBuilder("fiels-job", "0/3 * * * * ?", 3).build();
//创建SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration, FileBackupJob.class.getCanonicalName());
//创建new JobScheduler
new JobScheduler(registryCenter, LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build()).init();
}
//制造一些测试数据
//生成测试文件
private static void generateTestFiles(){
for(int i=1;i<11;i++){
FileBackupJob.files.add(new FileCustom(String.valueOf(i+10),"文件"+(i+10),"text","content"+ (i+10)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+20),"文件"+(i+20),"image","content"+ (i+20)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+30),"文件"+(i+30),"radio","content"+ (i+30)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+40),"文件"+(i+40),"video","content"+ (i+40)));
}
System.out.println("生产测试数据完成");
}
}
1.2.3.测试
(1)启动main方法查看控制台
定时任务每3秒批量执行一次,符合基础预期。
作业分片:0
time:2019-12-17T23:11:12.043,获取文件1个
23:11:12.043 [main-SendThread(192.168.180.113:2181)] DEBUG org.apache.zookeeper.ClientCnxn - Reading reply sessionid:0x16f140b9b8f000a, packet:: clientPath:/elastic-job-example-java/fiels-job/sharding/0 serverPath:/elastic-job-example-java/fiels-job/sharding/0 finished:false header:: 174,12 replyHeader:: 174,4393,0 request:: '/elastic-job-example-java/fiels-job/sharding/0,T response:: v{'running,'instance},s{28,28,1576590795096,1576590795096,0,1462,0,0,0,2,4393}
time:2019-12-17T23:11:12.043,备份文件,名称:文件21,类型:image
23:11:15.038 [main-SendThread(192.168.180.113:2181)] DEBUG org.apache.zookeeper.ClientCnxn - Reading reply sessionid:0x16f140b9b8f000a, packet:: clientPath:null serverPath:null finished:false header:: 193,1 replyHeader:: 193,4395,0 request:: '/elastic-job-example-java/fiels-job/sharding/0/running,,v{s{31,s{'world,'anyone}}},1 response:: '/elastic-job-example-java/fiels-job/sharding/0/running
作业分片:0
time:2019-12-17T23:11:15.038,获取文件1个
time:2019-12-17T23:11:15.038,备份文件,名称:文件31,类型:radio
23:11:18.021 [main-SendThread(192.168.180.113:2181)] DEBUG org.apache.zookeeper.ClientCnxn - Reading reply sessionid:0x16f140b9b8f000a, packet:: clientPath:/elastic-job-example-java/fiels-job/sharding/0 serverPath:/elastic-job-example-java/fiels-job/sharding/0 finished:false header:: 214,12 replyHeader:: 214,4397,0 request:: '/elastic-job-example-java/fiels-job/sharding/0,T response:: v{'running,'instance},s{28,28,1576590795096,1576590795096,0,1466,0,0,0,2,4397}
作业分片:0
time:2019-12-17T23:11:18.021,获取文件1个
time:2019-12-17T23:11:18.021,备份文件,名称:文件41,类型:video
(2)测试窗口1不关闭,再次运行main方法观察控制台日志(窗口2)
会出现以下两种情况:
窗口1继续执行任务,窗口2不执行任务
窗口2接替窗口1执行任务,窗口1停止执行任务
可通过反复启停窗口2查看到以上现象。
(3)窗口1、窗口2同时运行的情况下,停止正在执行任务的窗口
未停止的窗口开始执行任务。
分片测试:
当前作业没有被分片,所以多个实例共同执行时只有一个实例在执行,如果我们将作业分片执行,作业将被拆分为
多个独立的任务项,然后由分布式的应用实例分别执行某一个或几个分片项。
修改上边的代码,改为作业分3片执行:
同时启动三个JobMain:
每个JobMain窗口分别执行一片作业。
总结:
通过以上简单的测试,就可以看出Elastic-Job帮我们解决了分布式调度的以下三个问题:
1)多实例部署时避免任务重复执行,在任务执行时间到来时,从所有实例中选举出来一个,让它来执行任务,从
而避免多个实例同时执行任务。
2)高可用,若某一个实例宕机,不影响其他实例来执行任务。
3)弹性扩容,当集群中增加某一个实例,它应当也能够被选举并执行任务,如果作业分片将参与执行某个分片作
业。
1.3 Elastic-Job工作原理
1.3.1.Elastic-Job整体架构
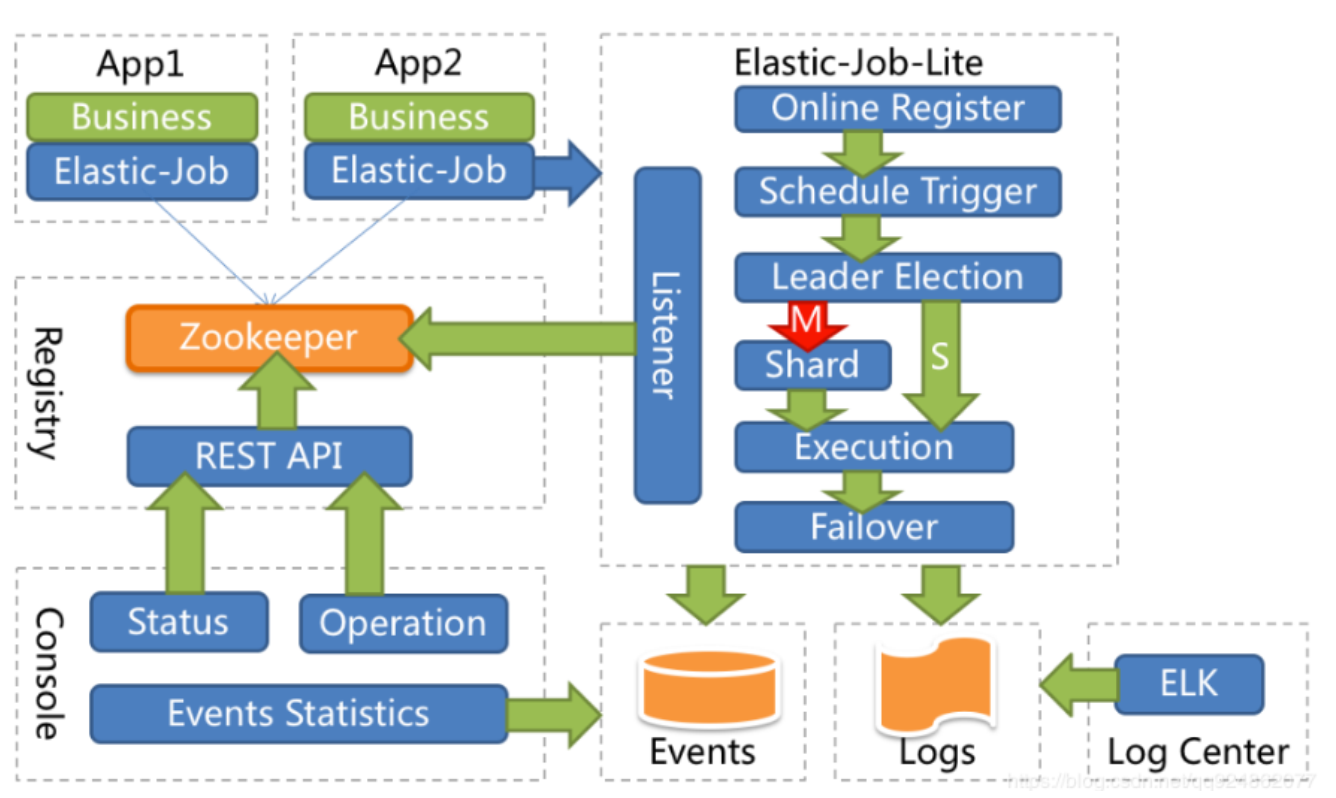
App:应用程序,内部包含任务执行业务逻辑和Elastic-Job-Lite组件,其中执行任务需要实现ElasticJob接口完成
与Elastic-Job-Lite组件的集成,并进行任务的相关配置。应用程序可启动多个实例,也就出现了多个任务执行实
例。
Elastic-Job-Lite:Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服
务,此组件负责任务的调度,并产生日志及任务调度记录。
无中心化,是指没有调度中心这一概念,每个运行在集群中的作业服务器都是对等的,各个作业节点是自治的、平
等的、节点之间通过注册中心进行分布式协调。
Registry:以Zookeeper作为Elastic-Job的注册中心组件,存储了执行任务的相关信息。同时,Elastic-Job利用该
组件进行执行任务实例的选举。
Console:Elastic-Job提供了运维平台,它通过读取Zookeeper数据展现任务执行状态,或更新Zookeeper数据修
改全局配置。通过Elastic-Job-Lite组件产生的数据来查看任务执行历史记录。
应用程序在启动时,在其内嵌的Elastic-Job-Lite组件会向Zookeeper注册该实例的信息,并触发选举(此时可能已
经启动了该应用程序的其他实例),从众多实例中选举出一个Leader,让其执行任务。当到达任务执行时间时,
Elastic-Job-Lite组件会调用由应用程序实现的任务业务逻辑,任务执行后会产生任务执行记录。当应用程序的某一
个实例宕机时,Zookeeper组件会感知到并重新触发leader选举
1.3.2.ZooKeeper
在学习Elastic-Job执行原理时,有必要大致了解一下ZooKeeper是用来做什么的,因为:
Elastic-Job依赖ZooKeeper完成对执行任务信息的存储(如任务名称、任务参与实例、任务执行策略等);
Elastic-Job依赖ZooKeeper实现选举机制,在任务执行实例数量变化时(如在快速上手中的启动新实例或停止实例),会触发选举机制来决定让哪个实例去执行该任务。
ZooKeeper是一个分布式一致性协调服务,它是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中
经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
咱们可以把ZooKeeper想象为一个特殊的数据库,它维护着一个类似文件系统的树形数据结构,ZooKeeper的客
户端(如Elastic-Job任务执行实例)可以对数据进行存取 :
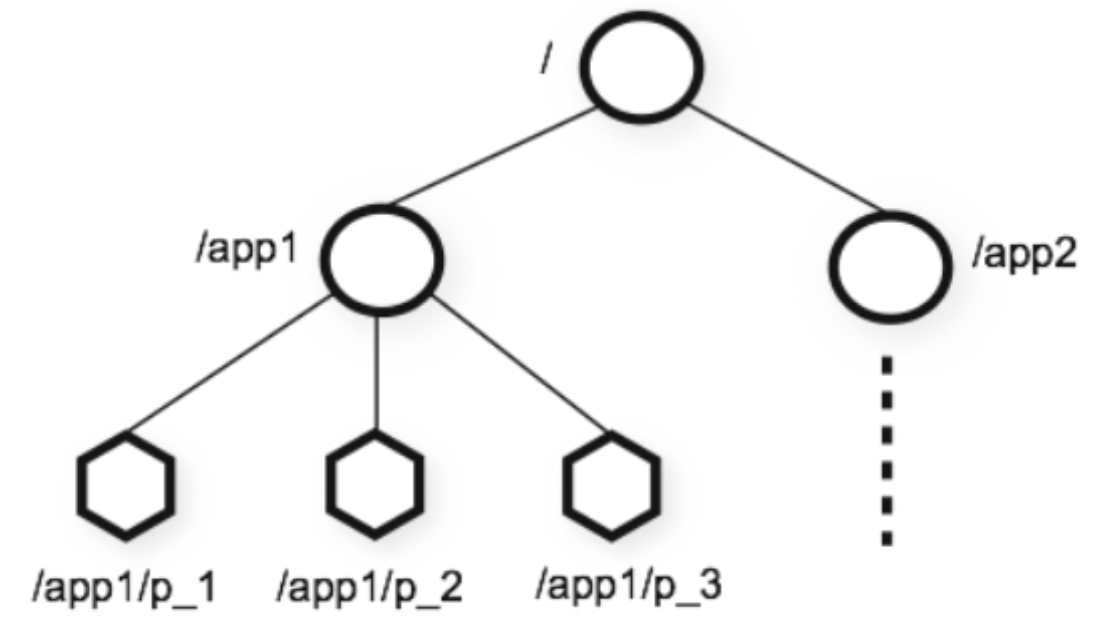
个子目录项如 /app1都被称作为 znode(目录节点),和文件系统一样,我们能够自由的增加、删除znode,在一
个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
ZooKeeper为什么称之为一致性协调服务呢?因为ZooKeeper拥有数据监听通知机制,客户端注册监听它关心的
znode,当znode发生变化(数据改变、被删除、子目录节点增加删除)时,ZooKeeper会通知所有客户端。简单
来说就是,当分布式系统的若干个服务都关心一个数据时,当这个数据发生改变,这些服务都能够得知,那么这些
服务就针对此数据达成了一致。
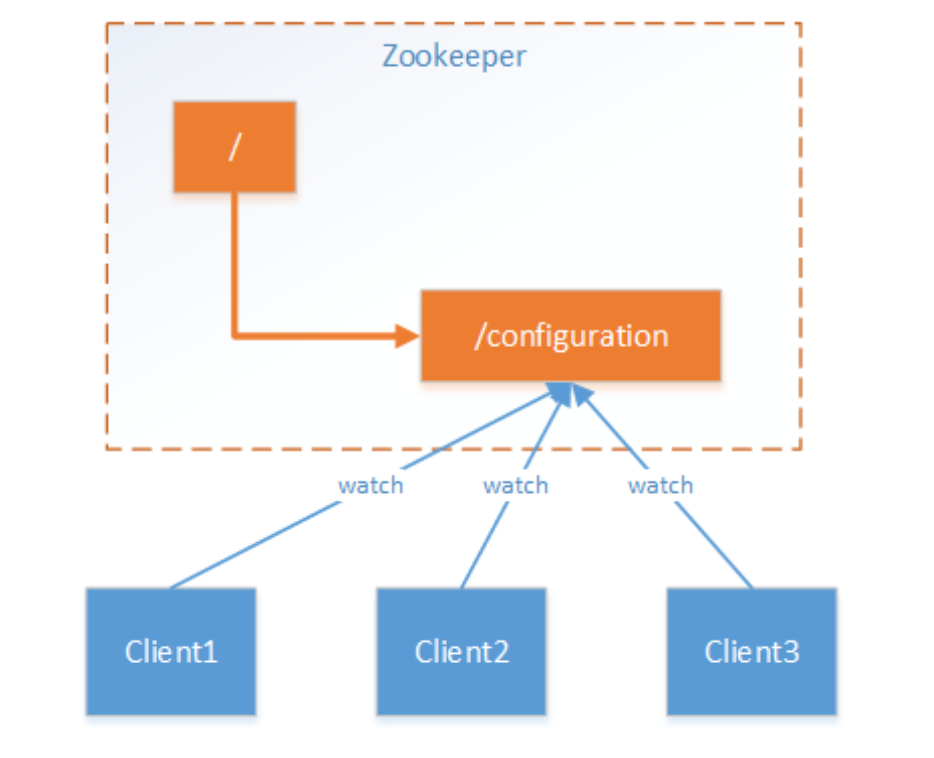
应用场景思考,使用ZooKeeper管理分布式配置项的机制:
假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,
现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序作为
ZooKeeper的客户端对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 ZooKeeper的通
知,从而获取新的配置信息应用到系统中。
1.3.2.1.Elastic-Job任务信息的保存
Elastic-Job使用ZooKeeper完成对任务信息的存取,任务执行实例作为ZooKeeper客户端对其znode操作,任务
信息保存在znode中。
使用ZooInspector查看zookeeper节点
1、zookeeper图像化客户端工具的下载地址:
https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip;
2、下载完后解压压缩包,双击地址为ZooInspector\build\zookeeper-dev-ZooInspector.jar的jar包;
如果双击没有反应?首先电脑要配好java环境,使用java -jar 再加上你的jar文件的路径 启动即可.
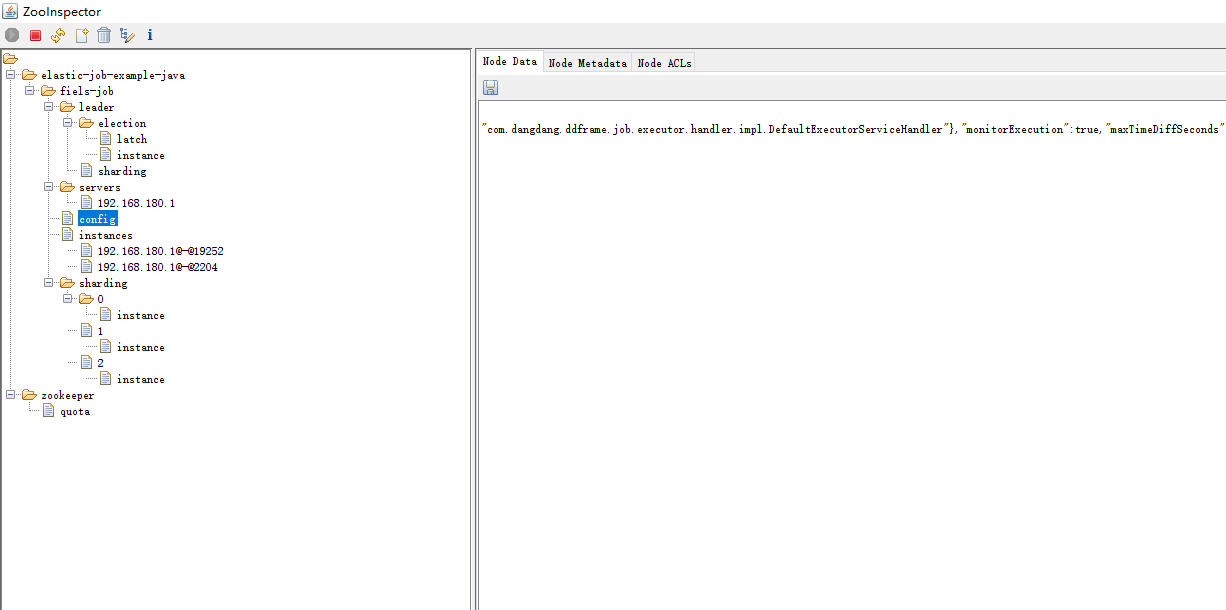
对config的数据进行格式化
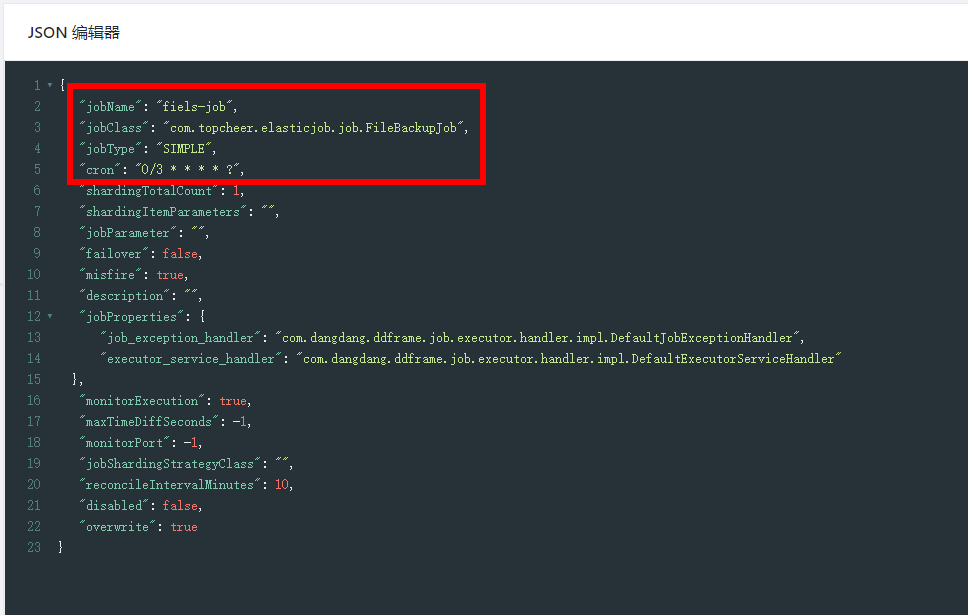
节点记录了任务的配置信息,包含执行类,cron表达式,分片算法类,分片数量,分片参数。默认状态下,如果
你修改了Job的配置比如cron表达式,分片数量等是不会更新到zookeeper上去的,需要把LiteJobConfiguration的
参数overwrite修改成true,或者删除zk的结点再启动作业重新创建。
instances节点:
同一个Job下的elastic-job的部署实例。一台机器上可以启动多个Job实例,也就是Jar包。instances的命名是
[IP+@-@+PID]。
leader节点:
任务实例的主节点信息,通过zookeeper的主节点选举,选出来的主节点信息。下面的子节点分为
election,sharding和failover三个子节点。分别用于主节点选举,分片和失效转移处理。election下面的instance
节点显式了当前主节点的实例ID:jobInstanceId。latch节点也是一个永久节点用于选举时候的实现分布式锁。
sharding节点下面有一个临时节点necessary,是否需要重新分片的标记,如果分片总数变化或任务实例节点上下
线,以及主节点选举,都会触发设置重分片标记,主节点会进行分片计算。
sharding节点:
任务的分片信息,子节点是分片项序号,从零开始,至分片总数减一。从这个节点可以看出哪个
分片在哪个实例上运行
1.3.2.2 任务执行实例选举
znode类型了,ZooKeeper有四种类型的znode,客户端在创建znode时可以指定:
PERSISTENT-持久化目录节点
客户端创建该类型znode,此客户端与ZooKeeper断开连接后该节点依旧存在,如果创建了重复的key,比
如/data,第二次创建会失败。
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与ZooKeeper断开连接后该节点依旧存在,允许重复创建相同key,Zookeeper给该节点名称进行顺序
编号,如zk会在后面加一串数字比如 /data/data0000000001,如果重复创建,会创建一
个/data/data0000000002节点(一直往后加1)
EPHEMERAL-临时目录节点
客户端与ZooKeeper断开连接后,该节点被删除,不允许重复创建相同key。
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与ZooKeeper断开连接后,该节点被删除,允许重复创建相同key,依然采取顺序编号机制。
实例选举实现过程分析:
每个Elastic-Job的任务执行实例作为ZooKeeper的客户端来操作ZooKeeper的znode
1)任意一个实例启动时首先创建一个 /server 的PERSISTENT节点
2)多个实例同时创建 /server/leaderEPHEMERAL子节点
3) /server/leader子节点只能创建一个,后创建的会失败。创建成功的实例被选为leader节点 ,用来执行任务。
4)所有任务实例监听 /server/leader 的变化,一旦节点被删除,就重新进行选举,抢占式地创建 /server/leader节点,谁创建成功谁就是leader。
Elastic-Job快速入门的更多相关文章
- Elastic Search快速入门
https://blog.csdn.net/weixin_42633131/article/details/82902812 通过这个篇文章可以快速入门,快速搭建一个elastic search de ...
- Elastic FileBeat 快速入门
背景 用过ELK(Elasticsearch, Logstash, Kibana)的人应该都面临过同样的问题,Logstash虽然功能强大:支持许多的input/output plugin.强大的fi ...
- Elastic 技术栈之快速入门
Elastic 技术栈之快速入门 概念 ELK 是什么 ELK 是 elastic 公司旗下三款产品 ElasticSearch .Logstash .Kibana 的首字母组合. ElasticSe ...
- Elasticsearch【快速入门】
前言:毕设项目还要求加了这个做大数据搜索,正好自己也比较感兴趣,就一起来学习学习吧! Elasticsearch 简介 Elasticsearch 是一个分布式.RESTful 风格的搜索和数据分析引 ...
- elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
一.快速入门 1. 查看集群的健康状况 http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 ...
- 零基础快速入门SpringBoot2.0教程 (三)
一.SpringBoot Starter讲解 简介:介绍什么是SpringBoot Starter和主要作用 1.官网地址:https://docs.spring.io/spring-boot/doc ...
- EFK教程 - EFK快速入门指南
通过部署elasticsearch(三节点)+filebeat+kibana快速入门EFK,并搭建起可用的demo环境测试效果 作者:"发颠的小狼",欢迎转载与投稿 目录 ▪ 用途 ...
- ELK快速入门(一)基本部署
ELK快速入门一-基本部署 ELK简介 什么是ELK?通俗来讲,ELK是由Elasticsearch.Logstash.Kibana 三个开源软件组成的一个组合体,这三个软件当中,每个软件用于完成不同 ...
- ELK快速入门(二)通过logstash收集日志
ELK快速入门二-通过logstash收集日志 说明 这里的环境接着上面的ELK快速入门-基本部署文章继续下面的操作. 收集多个日志文件 1)logstash配置文件编写 [root@linux-el ...
- ELK快速入门(四)filebeat替代logstash收集日志
ELK快速入门四-filebeat替代logstash收集日志 filebeat简介 Filebeat是轻量级单用途的日志收集工具,用于在没有安装java的服务器上专门收集日志,可以将日志转发到log ...
随机推荐
- Revo Uninstaller Pro - 真正彻底卸载软件不留垃圾的强大神器!(清理安装残留文件/注册表)
大家都知道 Windows 在卸载软件时总是不够彻底,系统C盘总会留下大量难以辨别和清理的垃圾文件和临时文件,时间长了注册表也会变得非常臃肿,不仅浪费硬盘空间,而且也会明显拖慢系统响应和启动速度. R ...
- css样式,媒体查询,垂直居中,js对象
下面是一些截图,有关查询效率,css样式,媒体查询,垂直居中,js基本类型.
- 插座-网络问题-ESP8266
//ATK-ESP8266模块测试主函数,检查WIFI模块是否在线 void atk_8266_test(void) { ))//检查WIFI模块是否在线 { atk_8266_quit_trans( ...
- AppCan适配问题
使用AppCan调试中心时,屏幕适配是个问题,经过多次调试总结出如下经验: 1,使用HD+(1560 x 720):显示错乱 2,使用FHD+ (2340 x 1080):显示错乱 3,HD (128 ...
- numpy-添加操作大全
合并 hstack(tup):按行合并 [前面有个 h,可以理解为 行,这样方便记忆] vstack(tup):按列合并 参数虽然是 tuple,但是 list 也行,可以合并2个或者多个数组. a= ...
- 在Vue项目中加载krpano全景图
在Vue-cli项目中做krpano全景图编辑器的时候,由于js插件的路径是动态的,做的过程中遇到了加载不到资源的难题,在网上搜索了好久也没找到合适的办法,最后想到了可能是JS加载的问题,于是解决了问 ...
- ImportError: Could not import PIL.Image.
pip install pillow
- Voting CodeForces - 749C (set,模拟)
大意: n个人, 两个党派, 轮流投票, 两种操作(1)ban掉一个人 (2)投票, 每轮一个未被ban的人可以进行一次操作(1)或操作(2), 求最终哪个党派得票最多. 显然先ban人会更优, 所以 ...
- sql server 对数运算函数log(x)和log10(x)
--LOG(x)返回x的自然对数,x相对于基数e的对数 --LOG10(x)返回x的基数为10的对数 示例:select LOG(3),LOG(6),LOG10(1),LOG10(100),LOG10 ...
- CentOS7 yum安装配置 +redis主从配置
一.安装必要包 yum install gcc 二.linux下安装 #下载 wget http://download.redis.io/releases/redis-3.0.0.tar.gz tar ...