spark性能调优06-数据倾斜处理
1、数据倾斜
1.1 数据倾斜的现象
现象一:大部分的task都能快速执行完,剩下几个task执行非常慢
现象二:大部分的task都能快速执行完,但总是执行到某个task时就会报OOM,JVM out of Memory,task faild,task lost,resubmitting task等错误
1.2 出现的原因
大部分task分配的数据很少(某个可以对应的values只有几个),但某几个task分配的数据非常多(某个key对应的values非常多)
2、数据倾斜解决方案
2.1 聚合源数据
方案一:直接在生成hive表的hive etl中,对数据进行聚合处理
例如:在hive etl操作时,将key对应的values,全部使用一种特殊的格式进行拼接到字符串中(“key=sessionid, value: action_seq=1|user_id=1|search_keyword=火锅|category_id=001;action_seq=2|user_id=1|search_keyword=涮肉|category_id=001”),对可以进行groupby,那么在spark中直接获取到的是<key,values>,就有可能不需要shuffle操作,就可能避免数据倾斜。
方案二:使用更小维度进行聚合处理
例如:每个key对应的10万数据,但是这10万数据中如果按不同的城市、天数等维度进行聚合,可能每个key就对应1万数据,就可以避免数据倾斜
2.2 过滤导致倾斜的key
如果业务和需求可以接受的话,在使用spark sql查询hive表中的数据时,通过where语句将导致数据倾斜的key直接过滤掉
例如:有2个key对应的数据有10万,而其他的key都只有几百的数据,那么如果业务和需求允许的话,可以直接将那两个key过滤掉,自然就不会发生数据倾斜
2.3 提高shuffle操作reduce的并行度
reduce并行度增加后,可以让reduce task分配到的数据减少,有可能缓解或基本解决数据倾斜的问题
可以在shuffle算子中传入第二个参数设置reduce端的并行度
2.4 使用随机key实现双重聚合
先将一样的key通过随机数进行拼接为新的不同的key进行局部聚合,然后将添加的随机数去掉后重新进行局部聚合(对groupByKey、reduceByKey有比较好的效果)
/**
* 使用随机key实现双重聚合
* 处理sessionRowPairRdd..groupByKey()数据倾斜
*/
final Random random=new Random();
//将相同的key进行随机打散后聚合
sessionRowPairRdd.mapToPair(new PairFunction<Tuple2<String,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Row> call(Tuple2<String, Row> tuple2) throws Exception {
return new Tuple2<String, Row>(random.nextInt()+"_"+tuple2._1, tuple2._2);
}
}).groupByKey() //将打散后的key还原后再次进行聚合
.mapToPair(new PairFunction<Tuple2<String,Iterable<Row>>, String, Iterable<Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Iterable<Row>> call(Tuple2<String, Iterable<Row>> tuple2)
throws Exception {
String key = tuple2._1;
return new Tuple2<String, Iterable<Row>>(key.split("_")[], tuple2._2);
}
}).groupByKey();
/**
* 使用随机key实现双重聚合 结束
*/
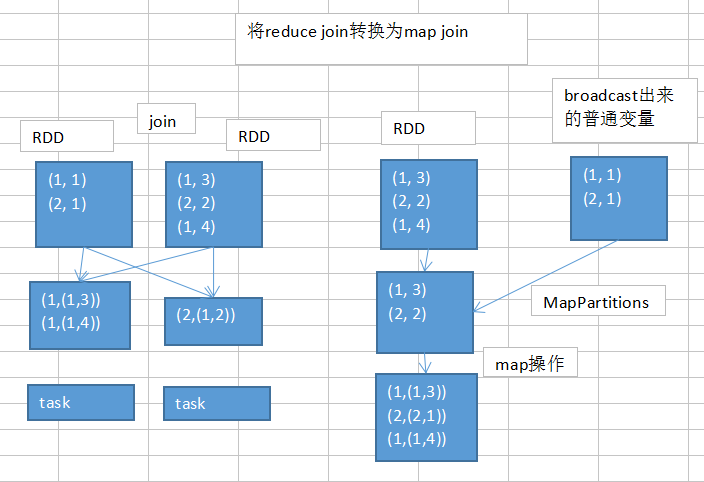
2.5 将reduce join转换为map join
如果两个Rdd需要进行join操作,并且一个Rdd比较小,可以通过broadcast把小的Rdd广播出去
/**
* 使用map join 替换reduce join
* 处理 userIdPartAggrInfoPairRdd.join(userIdInfoPairRdd)导致的数据倾斜
*/
//将小的Rdd userIdInfoPairRdd 作为广播变量
final Broadcast<Map<Long, Row>> broadcastUserIdInfoPairMap=javaSparkContext.broadcast(userIdInfoPairRdd.collectAsMap()); //使用map方式代替reduce join
userIdJoinRdd=userIdPartAggrInfoPairRdd.mapToPair(new PairFunction<Tuple2<Long,String>, Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(Tuple2<Long, String> tuple2)
throws Exception {
return new Tuple2<Long, Tuple2<String,Row>>(tuple2._1, new Tuple2<String, Row>(tuple2._2, broadcastUserIdInfoPairMap.value().get(tuple2._1)));
}
});
/**
* 使用map join 替换reduce join 结束
*/
2.6 sample采样倾斜key进行两次join
如果两个Rdd需要进行join操作,并且两个Rdd都比较大,不太适合使用2.5进行处理,但只有几个key会导致数据倾斜,可以先通过sample采样找出导致数据倾斜的key,然后根据找出导致数据倾斜的key将Rdd分为两个Rdd,用分成的两个Rdd分别于另一个Rdd经join后使用union进行合并为最后的Rdd

/**
* 使用sample采样倾斜key进行两次join
* 处理userIdPartAggrInfoPairRdd.join(userIdInfoPairRdd)导致的数据倾斜
*/
//userIdPartAggrInfoPairRdd sample采样查找数据倾斜的sessionId
final Long skewUserId=
//进行sample采样
userIdPartAggrInfoPairRdd.sample(false, 0.1, )
//将采样的数据映射为<userId,1>
.mapToPair(new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple2) throws Exception {
return new Tuple2<Long, Long>(tuple2._1, 1l);
} //按userId进行统计<userId,count>
}).reduceByKey(new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1+v2;
} //将统计结果映射为<count,userId>
}).mapToPair(new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple2) throws Exception {
return new Tuple2<Long, Long>(tuple2._2, tuple2._1);
} //按个数降序排列,并获取最大的userId
}).sortByKey(false).take().get()._2; //将导致数据倾斜的userId过滤出来后与userIdInfoPairRdd进行join
JavaPairRDD<Long, Tuple2<String, Row>> skewUserIdJoinRdd = userIdPartAggrInfoPairRdd.filter(new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple2) throws Exception {
return tuple2._1.longValue()==skewUserId;
}
}).join(userIdInfoPairRdd); //将正常的userId过滤出来后与userIdInfoPairRdd进行join
JavaPairRDD<Long, Tuple2<String, Row>> commonUserIdJoinRdd = userIdPartAggrInfoPairRdd.filter(new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple2) throws Exception {
return tuple2._1.longValue()!=skewUserId;
}
}).join(userIdInfoPairRdd); //将导致数据倾斜的userId join后的rdd和正常的userId join后的rdd合并为最终的rdd
userIdJoinRdd=skewUserIdJoinRdd.union(commonUserIdJoinRdd);
/**
* 使用sample采样倾斜key进行两次join结束
*/
2.7 使用随机数以及扩容表进行join
spark性能调优06-数据倾斜处理的更多相关文章
- Spark性能调优之解决数据倾斜
Spark性能调优之解决数据倾斜 数据倾斜七种解决方案 shuffle的过程最容易引起数据倾斜 1.使用Hive ETL预处理数据 • 方案适用场景:如果导致数据倾斜的是Hive表.如果该Hiv ...
- spark性能调优 数据倾斜 内存不足 oom解决办法
[重要] Spark性能调优——扩展篇 : http://blog.csdn.net/zdy0_2004/article/details/51705043
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html 一.大数据性能调优的本质 编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论 ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark性能调优之代码方面的优化
Spark性能调优之代码方面的优化 1.避免创建重复的RDD 对性能没有问题,但会造成代码混乱 2.尽可能复用同一个RDD,减少产生RDD的个数 3.对多次使用的RDD进行持久化(ca ...
- Spark性能调优之合理设置并行度
Spark性能调优之合理设置并行度 1.Spark的并行度指的是什么? spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并行度! 当分配 ...
- Spark性能调优之资源分配
Spark性能调优之资源分配 性能优化王道就是给更多资源!机器更多了,CPU更多了,内存更多了,性能和速度上的提升,是显而易见的.基本上,在一定范围之内,增加资源与性能的提升,是成正比的:写完了 ...
- Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优 • Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存. ...
随机推荐
- Sql 统计一个表有多少列
SELECT COUNT(syscolumns.name) FROM syscolumns , sysobjects WHERE syscolumns.id = sysobjects.id AND s ...
- python在类中使用__slot__属性
在类中定义__slot__属性来限制实例的属性字段,在创建大量对象的场合可以减少内存占用. 创建大量对象是内存占用对比: 类中不使用__slot__ class MySlot:def __init__ ...
- Codeforces 1215E 状压DP
题意:给你一个序列,你可以交换序列中的相邻的两个元素,问最少需要交换多少次可以让这个序列变成若干个极大的颜色相同的子段. 思路:由于题目中的颜色种类很少,考虑状压DP.设dp[mask]为把mask为 ...
- 获取服务进程server.exe的pid(0号崩溃)
#include "stdafx.h" #include <windows.h> #include <iostream> #include <COMD ...
- SpringBoot 利用freemaker生成静态页面
1. <!-- freemarker模板 --> <dependency> <groupId>org.springframework.boot</groupI ...
- Java 根据银行卡号获取银行名称以及图标
转 https://blog.csdn.net/N_007/article/details/78835526 参考 CNBankCard 中国各大银行卡号查询 一.支付宝接口获取名称 根据 卡号 获取 ...
- React笔记01——React开发环境准备
1 React简介 2013年由Facebook推出,代码开源,函数式编程.目前使用人数最多的前端框架.健全的文档与完善的社区. 官网:reactjs.org 阅读文档:官网中的Docs React ...
- CodeChef Max-digit Tree(动态规划)
传送门. 题解: 最主要的问题是如何判断一个数是否合法,这就需要发现性质了. 这个状态划分还是不太容易想到, 每次加的数\(∈[0,k)\),也就是个位一直在变变变,更高的位每次都是加一,这启发我们状 ...
- Drawer实现侧边栏布局
在 Scaffold 组件里面传入 drawer 参数可以定义左侧边栏,传入 endDrawer 可以定义右侧边栏.侧边栏默认是隐藏的,我们可以通过手指滑动显示侧边栏,也可以通过点击按钮显示侧边栏. ...
- Win10真正好用之处
第一步. 关闭无用服务 刚装好Win10的时候,整部电脑响应很慢,有时什么都不做,硬盘灯也能狂闪半天.很明显,这是微软爸爸默认开启的服务未被及时关闭所致. 网上有很多文章指导新手如何关闭系统服务,但 ...