LR为什么用极大似然估计,损失函数为什么是log损失函数(交叉熵)
首先,逻辑回归是一个概率模型,不管x取什么值,最后模型的输出也是固定在(0,1)之间,这样就可以代表x取某个值时y是1的概率
这里边的参数就是θ,我们估计参数的时候常用的就是极大似然估计,为什么呢?可以这么考虑
比如有n个x,xi对应yi=1的概率是pi,yi=0的概率是1-pi,当参数θ取什么值最合适呢,可以考虑
n个x中对应k个1,和(n-k)个0(这里k个取1的样本是确定的,这里就假设前k个是1,后边的是0.平时训练模型拿到的样本也是确定的,如果不确定还要排列组合)
则(p1*p2*...*pk)*(1-pk+1)*(1-pk+2)*...*(1-pn)最大时,θ是最合适的。联合概率最大嘛,就是总体猜的最准,就是尽可能使机器学习中所有样本预测到对应分类得概率整体最大化。
其实上边的算式就是极大似然估计的算式:
对应到LR中:

总之就是因为LR是概率模型,对概率模型估计参数用极大似然,原理上边说了
然后为什么用logloss作为cost function呢
主要的原因就是因为似然函数的本质和损失函数本质的关系
对数似然函数: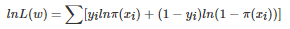
可以看到对数似然函数和交叉熵函数在二分类的情况下形式是几乎一样的,可以说最小化交叉熵的本质就是对数似然函数的最大化。
对数似然函数的本质就是衡量在某个参数下,整体的估计和真实情况一样的概率,越大代表越相近
而损失函数的本质就是衡量预测值和真实值之间的差距,越大代表越不相近。
他们两个是相反的一个关系,至于损失函数的惩罚程度,可以用参数修正,我们这里不考虑。
所以在对数似然前边加一个负号代表相反,这样就把对数似然转化成了一个损失函数,然后把y取0和1的情况分开(写成分段函数),就是:

意义就是:当y=1时,h=1时没有损失,h越趋近0损失越大
当y=0时,h=0没有损失,h越趋近1损失越大。
LR为什么用极大似然估计,损失函数为什么是log损失函数(交叉熵)的更多相关文章
- 【ML数学知识】极大似然估计
它是建立在极大似然原理的基础上的一个统计方法,极大似然原理的直观想法是,一个随机试验如有若干个可能的结果A,B,C,... ,若在一次试验中,结果A出现了,那么可以认为实验条件对A的出现有利,也即出现 ...
- B-概率论-极大似然估计
[TOC] 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等着你:https://www.cnblogs.com/nickchen121/ ...
- LR的损失函数&为何使用-log损失函数而非平方损失函数
https://blog.csdn.net/zrh_CSDN/article/details/80934278 Logistic回归的极大似然估计求解参数的推导: https://blog.csdn. ...
- 极大似然估计MLE 极大后验概率估计MAP
https://www.cnblogs.com/sylvanas2012/p/5058065.html 写的贼好 http://www.cnblogs.com/washa/p/3222109.html ...
- [白话解析] 深入浅出 极大似然估计 & 极大后验概率估计
[白话解析] 深入浅出极大似然估计 & 极大后验概率估计 0x00 摘要 本文在少用数学公式的情况下,尽量仅依靠感性直觉的思考来讲解 极大似然估计 & 极大后验概率估计,并且从名著中找 ...
- ML 徒手系列 最大似然估计
1.最大似然估计数学定义: 假设总体分布为f(x,θ),X1,X2...Xn为总体采样得到的样本.其中X1,X2...Xn独立同分布,可求得样本的联合概率密度函数为: 其中θ是需要求得的未知量,xi是 ...
- 参数估计:最大似然估计MLE
http://blog.csdn.net/pipisorry/article/details/51461997 最大似然估计MLE 顾名思义,当然是要找到一个参数,使得L最大,为什么要使得它最大呢,因 ...
- 【MLE】最大似然估计Maximum Likelihood Estimation
模型已定,参数未知 已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值.最大似然估计是建立在这样的思想上:已知某个参数能使这个 ...
- 极大既然估计和高斯分布推导最小二乘、LASSO、Ridge回归
最小二乘法可以从Cost/Loss function角度去想,这是统计(机器)学习里面一个重要概念,一般建立模型就是让loss function最小,而最小二乘法可以认为是 loss function ...
随机推荐
- Malware分析
//文章来源:http://www.2cto.com/Article/201312/265217.html by Kungen@CyberSword 想要查找恶意样本,首先要知道查找样本所需的基本信息 ...
- 如何在SVN服务器上创建项目
1,首先你的电脑上安装了SVN的服务器 VisualSVN-Server-3.7.1-x64.msi 2,打开SVN服务器后,可以看到分布的目录是 Repositories.Users.Groups. ...
- glob & fnmatch -- 使用Unix style通配符
通配符: ? 匹配单个字符 * 匹配 0+ 个字符 [seq] 匹配属于区间的单个字符 [!seq] 匹配不属于区间的单个字符 注意: "." just a " ...
- MYSQL学习笔记——数据类型
mysql的数据类型可以分为三大类,分别是数值数据类型.字符串数据类型以及日期时间数据类型. 数值数据类型 ...
- [NOI2004]郁闷的出纳员(平衡树)
[NOI2004]郁闷的出纳员 题目链接 题目描述 OIER公司是一家大型专业化软件公司,有着数以万计的员工.作为一名出纳员,我的任务之一便是统计每位员工的工资.这本来是一份不错的工作,但是令人郁闷的 ...
- CSS3 Animations
CSS Animations 是CSS的一个模块,它定义了如何用关键帧来随时间推移对CSS属性的值进行动画处理.关键帧动画的行为可以通过指定它们的持续时间,它们的重复次数以及它们如何重复来控制. an ...
- loj6038「雅礼集训 2017 Day5」远行 树的直径+并查集+LCT
题目传送门 https://loj.ac/problem/6038 题解 根据树的直径的两个性质: 距离树上一个点最远的点一定是任意一条直径的一个端点. 两个联通块的并的直径是各自的联通块的两条直径的 ...
- JS基础入门篇( 三 )—使用JS获取页面中某个元素的4种方法以及之间的差别( 一 )
1.使用JS获取页面中某个元素的4种方法 1.通过id名获取元素 document.getElementById("id名"); 2.通过class名获取元素 document.g ...
- 机器学习:2.NPL自然语言处理
1. 词带的简单解释: 每一个词出现了多少次,缺点是不知道顺序 2.seq2seq自然语言处理的核心 RNN: 一对一:输入一个,输出一个 一对多:输入一个,输出多个 多对一:输入多个,输出一个 多对 ...
- React / Vue 跨端渲染原理与实现探讨
跨端渲染是渲染层并不局限在浏览器 DOM 和移动端的原生 UI 控件,连静态文件乃至虚拟现实等环境,都可以是你的渲染层.这并不只是个美好的愿景,在今天,除了 React 社区到 .docx / .pd ...