LR为什么用极大似然估计,损失函数为什么是log损失函数(交叉熵)
首先,逻辑回归是一个概率模型,不管x取什么值,最后模型的输出也是固定在(0,1)之间,这样就可以代表x取某个值时y是1的概率
这里边的参数就是θ,我们估计参数的时候常用的就是极大似然估计,为什么呢?可以这么考虑
比如有n个x,xi对应yi=1的概率是pi,yi=0的概率是1-pi,当参数θ取什么值最合适呢,可以考虑
n个x中对应k个1,和(n-k)个0(这里k个取1的样本是确定的,这里就假设前k个是1,后边的是0.平时训练模型拿到的样本也是确定的,如果不确定还要排列组合)
则(p1*p2*...*pk)*(1-pk+1)*(1-pk+2)*...*(1-pn)最大时,θ是最合适的。联合概率最大嘛,就是总体猜的最准,就是尽可能使机器学习中所有样本预测到对应分类得概率整体最大化。
其实上边的算式就是极大似然估计的算式:
对应到LR中:

总之就是因为LR是概率模型,对概率模型估计参数用极大似然,原理上边说了
然后为什么用logloss作为cost function呢
主要的原因就是因为似然函数的本质和损失函数本质的关系
对数似然函数: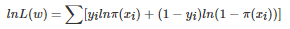
可以看到对数似然函数和交叉熵函数在二分类的情况下形式是几乎一样的,可以说最小化交叉熵的本质就是对数似然函数的最大化。
对数似然函数的本质就是衡量在某个参数下,整体的估计和真实情况一样的概率,越大代表越相近
而损失函数的本质就是衡量预测值和真实值之间的差距,越大代表越不相近。
他们两个是相反的一个关系,至于损失函数的惩罚程度,可以用参数修正,我们这里不考虑。
所以在对数似然前边加一个负号代表相反,这样就把对数似然转化成了一个损失函数,然后把y取0和1的情况分开(写成分段函数),就是:

意义就是:当y=1时,h=1时没有损失,h越趋近0损失越大
当y=0时,h=0没有损失,h越趋近1损失越大。
LR为什么用极大似然估计,损失函数为什么是log损失函数(交叉熵)的更多相关文章
- 【ML数学知识】极大似然估计
它是建立在极大似然原理的基础上的一个统计方法,极大似然原理的直观想法是,一个随机试验如有若干个可能的结果A,B,C,... ,若在一次试验中,结果A出现了,那么可以认为实验条件对A的出现有利,也即出现 ...
- B-概率论-极大似然估计
[TOC] 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等着你:https://www.cnblogs.com/nickchen121/ ...
- LR的损失函数&为何使用-log损失函数而非平方损失函数
https://blog.csdn.net/zrh_CSDN/article/details/80934278 Logistic回归的极大似然估计求解参数的推导: https://blog.csdn. ...
- 极大似然估计MLE 极大后验概率估计MAP
https://www.cnblogs.com/sylvanas2012/p/5058065.html 写的贼好 http://www.cnblogs.com/washa/p/3222109.html ...
- [白话解析] 深入浅出 极大似然估计 & 极大后验概率估计
[白话解析] 深入浅出极大似然估计 & 极大后验概率估计 0x00 摘要 本文在少用数学公式的情况下,尽量仅依靠感性直觉的思考来讲解 极大似然估计 & 极大后验概率估计,并且从名著中找 ...
- ML 徒手系列 最大似然估计
1.最大似然估计数学定义: 假设总体分布为f(x,θ),X1,X2...Xn为总体采样得到的样本.其中X1,X2...Xn独立同分布,可求得样本的联合概率密度函数为: 其中θ是需要求得的未知量,xi是 ...
- 参数估计:最大似然估计MLE
http://blog.csdn.net/pipisorry/article/details/51461997 最大似然估计MLE 顾名思义,当然是要找到一个参数,使得L最大,为什么要使得它最大呢,因 ...
- 【MLE】最大似然估计Maximum Likelihood Estimation
模型已定,参数未知 已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值.最大似然估计是建立在这样的思想上:已知某个参数能使这个 ...
- 极大既然估计和高斯分布推导最小二乘、LASSO、Ridge回归
最小二乘法可以从Cost/Loss function角度去想,这是统计(机器)学习里面一个重要概念,一般建立模型就是让loss function最小,而最小二乘法可以认为是 loss function ...
随机推荐
- 27、前端知识点--webpack面试题(二)
webpack面试题总结 本文主要是对webpack面试会常被问到的问题做一些总结,且文章会不断持续更新 1.webpack打包原理 把所有依赖打包成一个 bundle.js 文件,通过代码分割成单元 ...
- 【推荐系统】知乎live入门2.细节补充
参考链接 [推荐系统]知乎live入门 目录 1. 综述 2. 召回 3. 用户画像与标签 4. 特征工程 5. 点击率预估 6. 评估 7. 数据标注 8. 推荐 ================= ...
- 身为一个小白,看到一篇值得看的文章。讲述小白学习python的6个方法。
01. Python怎么学? Python虽然号称非常简单,功能强大!但是再简单,它也是一门编程语言,任何一个编程语言都会包含: 内功,心法和招式,内功心法就是指的算法,数据结构: 招式就是任何一 ...
- linux测试 Sersync 是否正常
[root@SERSYNC web]# for i in {1..10000};do echo 123456 > /data/web/$i &>/dev/null;do ne [r ...
- 实验查看PHP本地的Session信息
通过Nginx调度器负载后端两台Web服务器,实现以下目标: - 部署Nginx为前台调度服务器 - 调度算法设置为轮询 - 后端为两台LNMP服务器 - 部署测试页面,查看PHP本地的Session ...
- [Luogu2015]二叉苹果树(树形dp)
[Luogu2015] 二叉苹果树 题目描述 有一棵苹果树,如果树枝有分叉,一定是分2叉(就是说没有只有1个儿子的结点) 这棵树共有N个结点(叶子点或者树枝分叉点),编号为1-N,树根编号一定是1. ...
- 理解Promise (2)
一进来 我们开始执行 executor函数 传递两个参数 再调用 then 方法 ,then 方法里面有 OnResolve方法,OnReject 方法 在then 方法中,我们一开始的状态是pen ...
- 01.python对象
标准类型 数字 Integer 整型 Boolean 布尔型 Long integer 长整型 (python2) Floating point real number 浮点型 Complex num ...
- jmeter性能工具 之 传参 (三)
jmeter 主要有三种方式:键值对传参,json格式传参,外部传参 1.键值对传参 可以参考上篇登陆,使用的传参方式是键值对传参 2.json 格式传参 用json 格式传参不要忘了加http 头 ...
- [洛谷P1709] 隐藏的口令
问题描述 有时候程序员有很奇怪的方法来隐藏他们的口令.Binny会选择一个字符串S(由N个小写字母组成,5<=N<=5,000,000),然后他把S顺时针绕成一个圈,每次取一个做开头字母并 ...