Markov Decision Process in Detail
From the last post about MDP, we know the environment consists of 5 basic elements:
S:State Space of environment;
A:Actions Space that the environment allows;
{Ps,s'}:Transition Matrix, the probabilities of how environment state transit from one to another when actions are taken. The number of matrices equals to the number of actions.
R: Reward, when the system transitions from state s to s' due to action a, how much reward can an agent receive from the environment. Sometimes, reward have different definition.
γ: How reward discounts by time.
How Different between MDP and MRP:
Keyword: Action
The five elements of MDP can be illustrated by the chart below, in which the green circles are states, orange circles are actions, and there are two rewards. In MRP and Markov Process, we directly know the transition matrix. However, in the transition path from one state to another is interupted by actions. And it's worth noting that when the environment is at a certain state, there is no probabilities for actions. The reason is quite understandable: we live in the some world(environment), but different people have different behaviors.

Agent and Policy
Agent is the person or robot who interacts with the environment in Reinforcement Learning. Like human being, everyone may have different behavior under the same condition. The probability distribution of behaviors under different states is Policy. There are so many probabilities in an environment, but for a specific agent (person), he or she may take only one or several possible actions under a certain state. Given states, the policy is defined by:
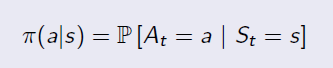
An example of policy is shown below:

From MRP to MDP: MRP+Policy
Transition Matrix: Without policies we do not exactly know the the probability from state s transitioning to s', because different agents may have different probabilitie to take actions. As long as we get π, we can calculate the state transition matrix. 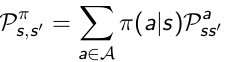
In the chart above, for example, if an agent has probabilitie 0.4 and 0.6 for action a0 and a1, the transition probability from s0 to s1 is: 0.4*0.5+0.6*1=0.8
Reward:
In MDP the reward function is related to actions, which average the uncertainties of the result from an action.
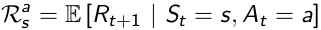
Once we've got the Policy π, we know the action distribution of a specific agent, so we can average the uncertaintie of actions, then measure how much immediate reward can receive from state s under policy π.

So now we go back from MDP to MRP, and the Markov Reward Process is defined by the tuple

Two Value Functions:
State Value Function:
State Value Function is the same as the value function in MRP. It is used to evaluate the goodness of being in a state s(by immedate and future reward), and the only difference is to average the uncertainty of actions under policy π. It is in the form of:
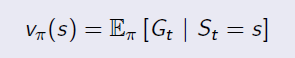
Action Value Function:
To average uncertainties of actions, it's neccesary to know the expected reward from possible actions. So we have Action Value Functionin MDP, which reveals whether an action is good or bad when an agent takes an particular action in state s.

If we calculate expectation of Action Value Functions under the same state s, we will end up with the State Value Function v:
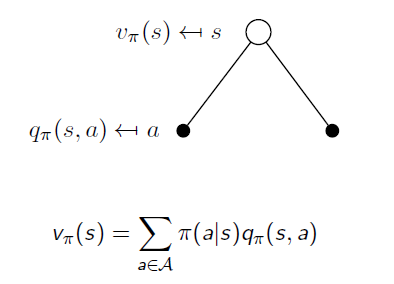
Similarly, when an action is taken, the system may end up with different states. When we remove the uncertainty of state transition, we go back from State Value Function to Action Value Function:
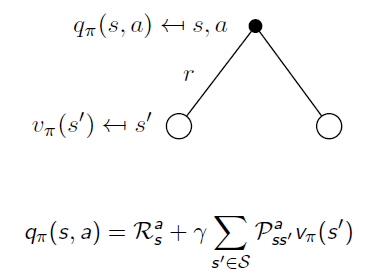
If we put them together:
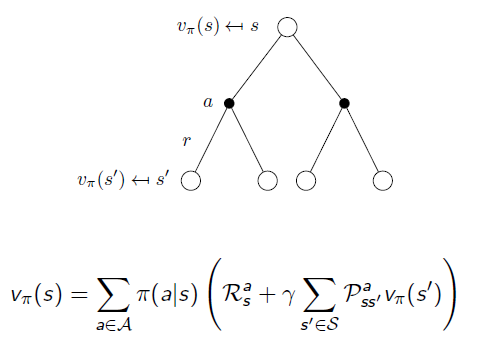
Another way:

Markov Decision Process in Detail的更多相关文章
- Step-by-step from Markov Process to Markov Decision Process
In this post, I will illustrate Markov Property, Markov Reward Process and finally Markov Decision P ...
- Ⅱ Finite Markov Decision Processes
Dictum: Is the true wisdom fortitude ambition. -- Napoleon 马尔可夫决策过程(Markov Decision Processes, MDPs ...
- Markov Decision Processes
为了实现某篇论文中的算法,得先学习下马尔可夫决策过程~ 1. https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/conte ...
- Reinforcement Learning Index Page
Reinforcement Learning Posts Step-by-step from Markov Property to Markov Decision Process Markov Dec ...
- 论文笔记之:Learning to Track: Online Multi-Object Tracking by Decision Making
Learning to Track: Online Multi-Object Tracking by Decision Making ICCV 2015 本文主要是研究多目标跟踪,而 online ...
- 强化学习二:Markov Processes
一.前言 在第一章强化学习简介中,我们提到强化学习过程可以看做一系列的state.reward.action的组合.本章我们将要介绍马尔科夫决策过程(Markov Decision Processes ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 机器学习算法基础(Python和R语言实现)
https://www.analyticsvidhya.com/blog/2015/08/common-machine-learning-algorithms/?spm=5176.100239.blo ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
随机推荐
- dfs(找环)
https://codeforces.com/problemset/problem/1249/B2 B2. Books Exchange (hard version) time limit per t ...
- 错排问题 && 洛谷 P1595 信封问题
传送门 一道裸的错排问题 错排问题 百度百科上这样说 就是对于一个排列,每一个数都不在正确的位置上的方案数.n 个元素的错排数记为 D(n). 公式 D(n)=(n−1)∗(D(n−2)+D(n−1) ...
- 6、 逻辑回归(Logistic Regression)
6.1 分类问题 在分类问题中,你要预测的变量
- 2019 Multi-University Training Contest 2 - 1009 - 回文自动机
http://acm.hdu.edu.cn/showproblem.php?pid=6599 有好几种实现方式,首先都是用回文自动机统计好回文串的个数. 记得把每个节点的cnt加到他的fail上,因为 ...
- 树莓派VNC Viewer 远程桌面配置教程
作为一个刚入门的小白,你还在为如何配置树莓派的远程桌面控制苦恼? 是否希望能够每次在树莓派上无须接上显示器.键盘.鼠标以及走到放置你的树莓派的地方就可以运行指令! 在这篇树莓派文章中,你将学到如何在树 ...
- 06-File-文件
文件 长久保存信息的一种数据信息集合 常用操作 打开关闭(文件一旦打开,需要关闭操作) 读写内容 查找 open函数 open函数负责打开文件,带有很多参数 第一个参数: 必须有,文件的路径和名称 m ...
- python学习笔记(6)关键字与循环控制
一.变量和类型 1.基本变量类型 (1)整数 (2)浮点数 (3)字符串 (4)布尔值 (5)空值 (6)函数 (7)模块 (8)类型 (9)自定义类型 print(type()) print(typ ...
- Javascript 原型链之原型对象、实例和构造函数三者之间的关系
前言:用了这么久js,对于它的原型链一直有种模糊的不确切感,很不爽,隧解析之. 本文主要解决的问题有以下三个: (1)constructor 和 prototype 以及实例之间啥关系? (2)pro ...
- DNS服务的安装
DNS服务器原理及配置 域名讲解 www.baidu.com 完整的域名,通常.来进行分割三个部分:www是主机名,baidu是域名,com是类型 主机名 + 域名 + 类型 构成完整的域名 DNS服 ...
- [python 学习] IO操作之读写文件
一.读取全部文件: # -*- coding: utf-8 -*- f = open('qq_url.txt','r'); print f.read(); f.close(); 二.读取规定长度文件 ...