Markov Decision Process in Detail
From the last post about MDP, we know the environment consists of 5 basic elements:
S:State Space of environment;
A:Actions Space that the environment allows;
{Ps,s'}:Transition Matrix, the probabilities of how environment state transit from one to another when actions are taken. The number of matrices equals to the number of actions.
R: Reward, when the system transitions from state s to s' due to action a, how much reward can an agent receive from the environment. Sometimes, reward have different definition.
γ: How reward discounts by time.
How Different between MDP and MRP:
Keyword: Action
The five elements of MDP can be illustrated by the chart below, in which the green circles are states, orange circles are actions, and there are two rewards. In MRP and Markov Process, we directly know the transition matrix. However, in the transition path from one state to another is interupted by actions. And it's worth noting that when the environment is at a certain state, there is no probabilities for actions. The reason is quite understandable: we live in the some world(environment), but different people have different behaviors.

Agent and Policy
Agent is the person or robot who interacts with the environment in Reinforcement Learning. Like human being, everyone may have different behavior under the same condition. The probability distribution of behaviors under different states is Policy. There are so many probabilities in an environment, but for a specific agent (person), he or she may take only one or several possible actions under a certain state. Given states, the policy is defined by:
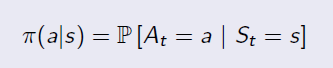
An example of policy is shown below:

From MRP to MDP: MRP+Policy
Transition Matrix: Without policies we do not exactly know the the probability from state s transitioning to s', because different agents may have different probabilitie to take actions. As long as we get π, we can calculate the state transition matrix. 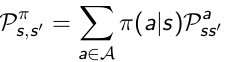
In the chart above, for example, if an agent has probabilitie 0.4 and 0.6 for action a0 and a1, the transition probability from s0 to s1 is: 0.4*0.5+0.6*1=0.8
Reward:
In MDP the reward function is related to actions, which average the uncertainties of the result from an action.
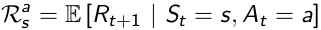
Once we've got the Policy π, we know the action distribution of a specific agent, so we can average the uncertaintie of actions, then measure how much immediate reward can receive from state s under policy π.

So now we go back from MDP to MRP, and the Markov Reward Process is defined by the tuple

Two Value Functions:
State Value Function:
State Value Function is the same as the value function in MRP. It is used to evaluate the goodness of being in a state s(by immedate and future reward), and the only difference is to average the uncertainty of actions under policy π. It is in the form of:
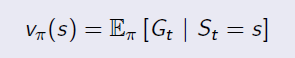
Action Value Function:
To average uncertainties of actions, it's neccesary to know the expected reward from possible actions. So we have Action Value Functionin MDP, which reveals whether an action is good or bad when an agent takes an particular action in state s.

If we calculate expectation of Action Value Functions under the same state s, we will end up with the State Value Function v:
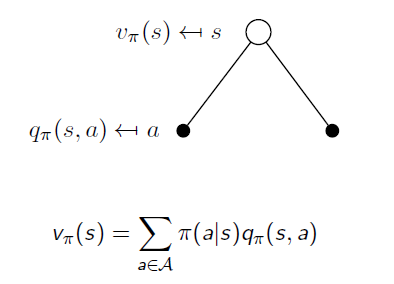
Similarly, when an action is taken, the system may end up with different states. When we remove the uncertainty of state transition, we go back from State Value Function to Action Value Function:
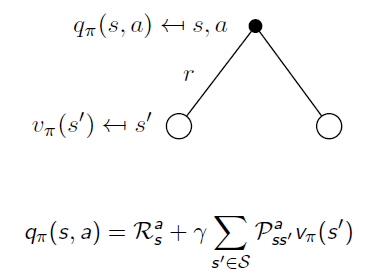
If we put them together:
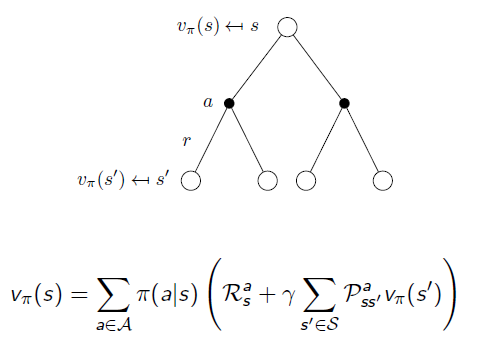
Another way:

Markov Decision Process in Detail的更多相关文章
- Step-by-step from Markov Process to Markov Decision Process
In this post, I will illustrate Markov Property, Markov Reward Process and finally Markov Decision P ...
- Ⅱ Finite Markov Decision Processes
Dictum: Is the true wisdom fortitude ambition. -- Napoleon 马尔可夫决策过程(Markov Decision Processes, MDPs ...
- Markov Decision Processes
为了实现某篇论文中的算法,得先学习下马尔可夫决策过程~ 1. https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/conte ...
- Reinforcement Learning Index Page
Reinforcement Learning Posts Step-by-step from Markov Property to Markov Decision Process Markov Dec ...
- 论文笔记之:Learning to Track: Online Multi-Object Tracking by Decision Making
Learning to Track: Online Multi-Object Tracking by Decision Making ICCV 2015 本文主要是研究多目标跟踪,而 online ...
- 强化学习二:Markov Processes
一.前言 在第一章强化学习简介中,我们提到强化学习过程可以看做一系列的state.reward.action的组合.本章我们将要介绍马尔科夫决策过程(Markov Decision Processes ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 机器学习算法基础(Python和R语言实现)
https://www.analyticsvidhya.com/blog/2015/08/common-machine-learning-algorithms/?spm=5176.100239.blo ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
随机推荐
- ex3 多分类和神经网络
介绍 在本练习中,您将实现一对多逻辑回归和神经识别手写数字的网络.在开始编程之前练习,我们强烈建议观看视频讲座并完成相关主题的复习问题.要开始练习,您需要下载起始代码并将其内容解压缩到要完成练习的目录 ...
- 魔板 (bfs+康托展开)
# 10027. 「一本通 1.4 例 2」魔板 [题目描述] Rubik 先生在发明了风靡全球魔方之后,又发明了它的二维版本--魔板.这是一张有 888 个大小相同的格子的魔板: 1 2 3 4 8 ...
- Cocos2d-x的Android配置以及相关參考文档
版权声明:版权声明:本文为博主原创文章.转载请附上博文链接! https://blog.csdn.net/ccf19881030/article/details/24141181 关于Win7 ...
- Elasticsearch7.X 入门学习第一课笔记----基本概念
原文:Elasticsearch7.X 入门学习第一课笔记----基本概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https: ...
- Latex--入门系列一
Latex 专业的参考 tex对于论文写作或者其他的一些需要排版的写作来说,还是非常有意义的.我在网上看到这个对于Latex的入门介绍还是比较全面的,Arbitrary reference .所以将会 ...
- 利用python处理txt文件
前段时间做公司一个自动翻译项目需要处理大量的文案字段,手工去做简直不大可能(懒),因此借用python脚本自动化处理掉了,在此记录一下. import linecache def outputfile ...
- Altium Designer设计PCB中如何开槽
在不同层画槽孔形状实际得到的PCB效果(注意槽孔边缘) 在不同层画槽孔形状进行(注意槽孔边缘) 很多坛友问在使用Altium Designer设计PCB时,想在板子上开一个槽或者挖一个孔该如何操作,是 ...
- idea hibernate console 执行hql报错
报错信息 hql> select a from GDXMZD a[2019-08-29 13:45:01] org.hibernate.service.spi.ServiceException: ...
- web编程jsp小tips
jsp文件头 <%@ page language="java" contentType="text/html; charset=UTF-8" pageEn ...
- JavaScript 复杂判断的更优雅写法借鉴
前言: 我们编写js代码时经常遇到复杂逻辑判断的情况,通常大家可以用if/else或者switch来实现多个条件判断,但这样会有个问题,随着逻辑复杂度的增加,代码中的if/else/switch会变得 ...