进阶3: zookeeper-3.4.9.tar.gz和hbase-1.2.4-bin.tar.gz 环境搭建(hbase 伪分布式)
前提条件:
成功安装了 jdk1.8, hadoop2.7.3
注意条件:
zookeeper,hbase 版本必须要和hadoop 安装版本相互兼容,否则容易出问题;
本次:安装包 zookeeper-3.4.9.tar.gz 和 hbase-1.2.4-bin.tar.gz
zookeeper 安装步骤:
1. 下载安装包 zookeeper-3.4.9.tar.gz,并上传到linux 目录;
2. 解压文件
tar zxvf zookeeper-3.4.9.tar.gz
3. 进入 zookeeper-3.4.9 , 拷贝 conf /zoo_sample.cfg
cp conf/zoo_sample.cfg conf/zoo.cfg
4. 编辑配置文件 conf/zoo.cfg ,如下图:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/hadoop-soft/etc/zookeeper-3.4.9/zookeeper_data
# the port at which the clients will connect
clientPort=2181
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=5
# Purge task interval in hours
autopurge.purgeInterval=1

5. 配置环境变量:
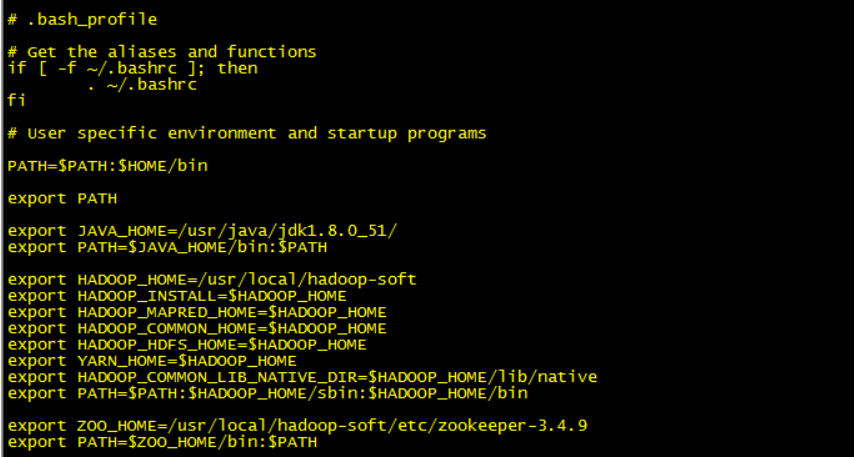
a. 进入根目录,编辑 ./bash_profile 文件,设置环境变量:
export ZOO_HOME=/usr/local/hadoop-soft/etc/zookeeper-3.4.9
export PATH=$ZOO_HOME/bin:$PATH

6. 启动zookeeper
bin/zkServer.sh start
7. 验证启动zookeeper成功
a. 验证进程
jps | grep Quorum
b. 如果产生如下输出,则表明进程启动正常:

HBase 安装步骤(伪分布式版):
1.上传hbase-1.2.4 安装包到linux ;
2.进入根目录,编辑 ./bash_profile 文件,设置HBase 环境变量:
export HBASE_HOME=/usr/local/hadoop-soft/etc/hbase-1.2.4
export PATH=$HBASE_HOME/bin:$PATH
3.解压hbase-1.2.4 安装文件
tar zxvf hbase-1.2.4-bin.tar.gz
4.编辑 conf/hbash-env.sh 文件,可以添加,也可以松开hbash-env.sh 代码注解
export JAVA_HOME=/usr/java/jdk1.8.0_51
export HBASE_MANAGES_ZK=false 如果你是使用hbase自带的zk就是true,如果使用自己的zk就是false,此次我们使用的是zoopkeeper 提供的,所以为false
5. 编辑 conf/hbase-site.xml
<configuration>
<property>
<!-- 是否分布式-->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!-- hbase 持久化保存目录-->
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<!-- 指定要连接zk的节点 -->
<name>hbase.zookeeper.quorum</name>
<value>bigdata</value>
</property>
</configuration>
为了防止因为hbase和hadoop版本不一致而出现的问题,可以看下{hbase_home}/lib/下相关hadoop*.jar的jar包,跟你的hadoop是否是同一个版本,如果不是可以从{hadoop_home}/ share/hadoop/ 下复制
6. 编辑conf/regionservers文件
master
该文件表示在哪些主机上启动RegionServers,每一行表示一个主机名,执行命令的时候需要这些机器上的SSH登陆权限
7. (如果zookeeper 没启动,先启动zookeeper)启动HDFS :
start-dfs.sh

假如遇到遇到如下问题:如下截图dataNode

此截图就没有启动DataNode ,解决办法:将对应的HDFS (hdfs-site.xml) nameNode ,dataNode 节点对应的目录删除,重新分区:
a 如下图:将dfs 所有目录先删除,然后在将nameNode,dataNode 对应的目录手动删除,在手动创建

b. 执行hdfs 分区操作:
hdfs namenode -format

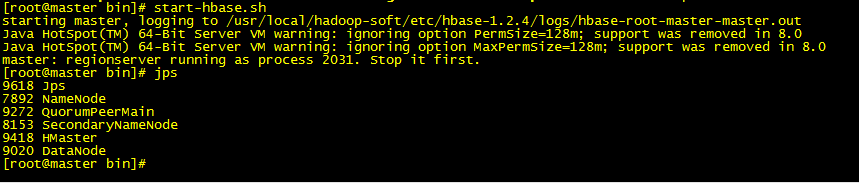
8.启动 hbase
bin/start-hbase.sh
9. jps ,如果看到如下 进程。
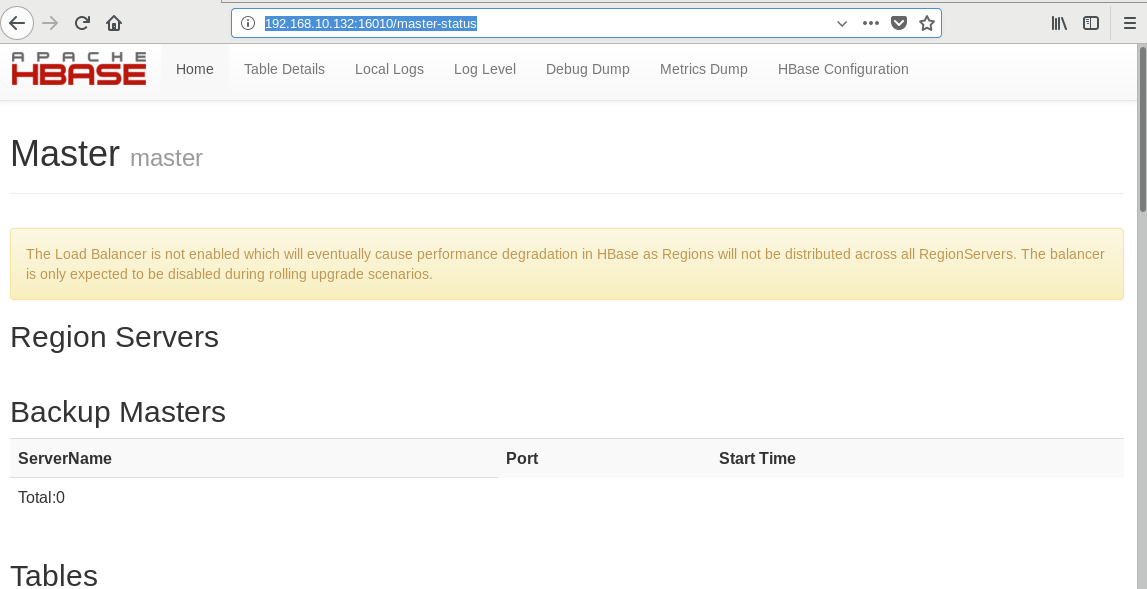
10. 查看是否启动成功, http://master:16010/master-status
进阶3: zookeeper-3.4.9.tar.gz和hbase-1.2.4-bin.tar.gz 环境搭建(hbase 伪分布式)的更多相关文章
- Zookeeper 集群搭建--单机伪分布式集群
一. zk集群,主从节点,心跳机制(选举模式) 二.Zookeeper集群搭建注意点 1.配置数据文件 myid 1/2/3 对应 server.1/2/3 2.通过./zkCli.sh -serve ...
- windows下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper
原文出自:http://sbp810050504.blog.51cto.com/2799422/1408322 按照该方法,伪分布式solr部署成功 ...
- ZooKeeper 介绍及集群环境搭建
本篇由鄙人学习ZooKeeper亲自整理的一些资料 包括:ZooKeeper的介绍,我们要学习ZooKeeper的话,首先就要知道他是干嘛的对吧. 其次教大家如何去安装这个精巧的智慧品! 相信你能研究 ...
- Zookeeper 初体验之——伪分布式安装(转)
原文地址: http://blog.csdn.net/salonzhou/article/details/47401069 简介 Apache Zookeeper 是由 Apache Hadoop 的 ...
- 详细讲解Hadoop源码阅读工程(以hadoop-2.6.0-src.tar.gz和hadoop-2.6.0-cdh5.4.5-src.tar.gz为代表)
首先,说的是,本人到现在为止,已经玩过. 对于,这样的软件,博友,可以去看我博客的相关博文.在此,不一一赘述! Eclipse *版本 Eclipse *下载 Jd ...
- LAMP环境搭建之编译安装指南(php-5.3.27.tar.gz)
测试环境:CentOS release 6.5 (Final) 软件安装:httpd-2.2.27.tar.gz mysql-5.1.72.tar.gz php-5.3.27.tar.gz 1 ...
- LNMP环境搭建之编译安装指南(php-5.3.27.tar.gz)
测试环境:CentOS release 6.5 (Final) 软件安装:nginx mysql-5.5.32-linux2.6-x86_64.tar.gz php-5.3.27.tar.gz ...
- 【进阶】ZooKeeper 相关概念总结
1. 开卷有益 学习是一种习惯,只有把这种习惯保持下来,每天不学习一点就感觉浑身不自在,达到这样的境界,那么你成为大佬也就不远了买,正如我们标题所写的"开卷有益".人生匆匆,要想过 ...
- Hadoop学习笔记—14.ZooKeeper环境搭建
从字面上来看,ZooKeeper表示动物园管理员,这是一个十分奇妙的名字,我们又想起了Hadoop生态系统中,许多项目的Logo都采用了动物,比如Hadoop采用了大象的形象,所以我们可以猜测ZooK ...
随机推荐
- python学习之路 目录
python Python基础-1 python由来 字符编码 注释 pyc文件 python变量 导入模块 获取用户输入 流程控制if while python基础-2 编码转换 pycharm 配 ...
- [DS+Algo] 006 两种简单排序及其代码实现
目录 1. 快速排序 QuickSort 1.1 步骤 1.2 性能分析 1.3 Python 代码示例 2. 归并排序 MergeSort 2.1 步骤 2.2 性能分析 2.3 Python 代码 ...
- CentOS7 内核模块管理
1.查看所有模块:lsmod 2.查看指定模块的详细信息:modinfo 模块名 3.动态加载模块:modprobe 模块名 4.动态卸载模块:modprobe -r 模块名 5.开机自动加载模块:假 ...
- 通过Spark Streaming处理交易数据
Apache Spark 是加州大学伯克利分校的 AMPLabs 开发的开源分布式轻量级通用计算框架. 由于 Spark 基于内存设计,使得它拥有比 Hadoop 更高的性能(极端情况下可以达到 10 ...
- ES5中的继承
继承 在面向对象的语言中, 大多语言都支持两种继承方式: 接口继承 和 实现继承, 接口继承 只继承方法签名, 实现继承 才继承实际的方法, ECMAScript 值支持 实现继承, 今天我们来谈谈实 ...
- P1313计算系数
这是2011年提高组第一题,一个数论题.如果当年我去的话,就爆零了wuwuwu. 题目:(ax+by)^k中询问x^m*y^n这一项的系数是多少?拿到题我就楞了,首先便是想到DP,二维分别存次数代表系 ...
- uboot 主Makefile分析
一. Makefile 配置 1.1. make xxx_config 1.1.1. 笔者实验时是make x210_sd_config a. x210_sd_config是Makefile下的一个目 ...
- JS封装插件:实现文件读写功能
scripting.FileSystemObject是一个可以实现文件读写的COM组件,由于COM组件可以被跨语言调用,因此可以选择像vbs或者JS这种脚本语言调用,下面我就使用该COM组件封装了一个 ...
- python文件打包/导入 .so 文件
打包so文件 见: http://www.cnblogs.com/ke10/p/py2so.html 导入so文件 import sys sys.path.append(r'/home/project ...
- 数塔 Medium
Summer is coming! It's time for Iahub and Iahubina to work out, as they both want to look hot at the ...