Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片,在博客园不能用 CSDN 的图片。
当前想到的方案就是:先把 CSDN 上的图片都下载下来,再手动更新吧。
所以简单写了一个爬虫用来下载 CSDN 平台上的图片,用于在其他平台上更新图片时用
更多内容,请看代码注释
效果演示
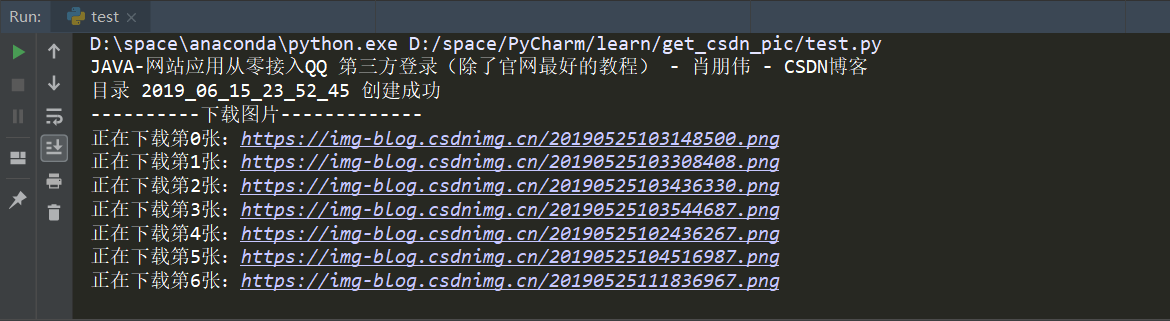

Python 源代码
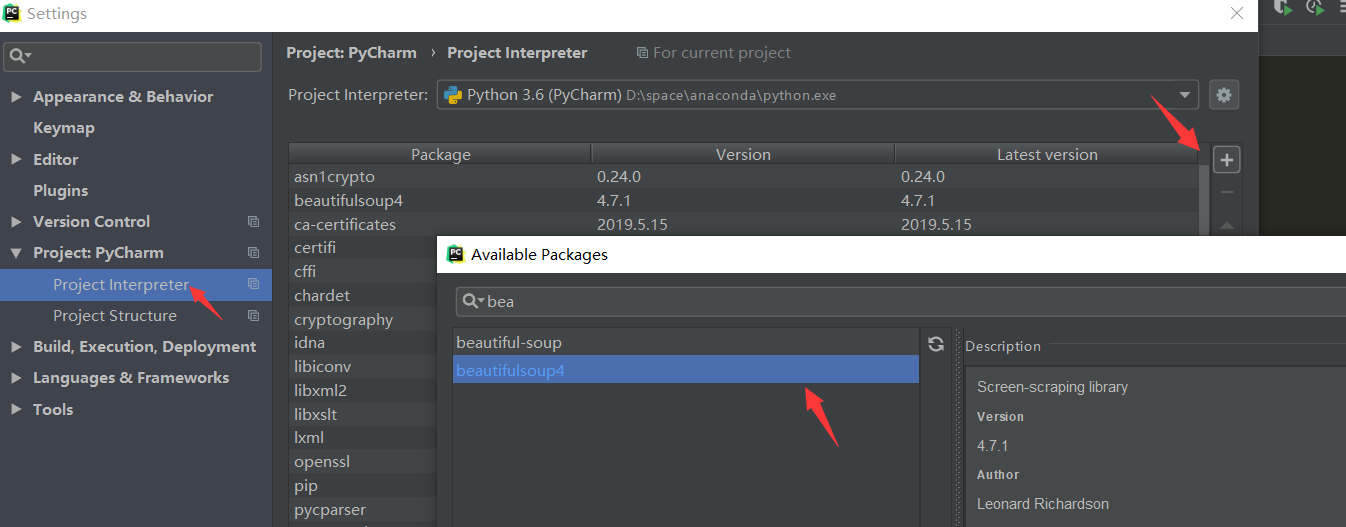
提示: 需要先下载 BeautifulSoup 哦,可以用 pip,也可以直接在 PyCharm 中安装
简单的方法:
# coding:utf-8
'''
使用爬虫下载图片:
1.使用 CSDN 博客
2.获取图片连接,并下载图片
3.可去除水印
作者:java997.com
'''
import re
from urllib import request
from bs4 import BeautifulSoup
import datetime
# 构造无水印纯链接数组
def get_url_array(all_img_href):
img_urls = []
for h in all_img_href:
# 去掉水印
if re.findall("(.*?)\?", h[1]):
h = re.findall("(.*?)\?", h[1])
# 因为这里匹配就只有 src 了, 所以直接用 0
img_urls.append(h[0])
else:
# 因为这里还没有处理有 alt 的情况, 所以直接用 1
img_urls.append(h[1])
return img_urls
# 构建新目录的方法
def mkdir(path):
# 引入模块
import os
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print('目录 ' + path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print('目录 ' + path + ' 已存在')
return False
if __name__ == '__main__':
# url = input("请粘贴博客链接")
url = "https://blog.csdn.net/qq_40147863/article/details/90484190"
# 获取页面 html
rsp = request.urlopen(url)
all_html = rsp.read()
# 一锅清汤
soup = BeautifulSoup(all_html, 'lxml')
# bs 自动解码
content = soup.prettify()
# 获取标题
tags = soup.find_all(name='title')
for i in tags:
# .string 是去掉标签, 只打印内容
print(i.string)
# 获取正文部分
article = soup.find_all(name='article')
# print(article[0])
# 获取图片的链接
all_img_href = re.findall('<img(.*?)src="(.*?)"', str(article))
# 调用函数, 获取去掉水印后的链接数组
img_urls = get_url_array(all_img_href);
# 用当前之间为目录名, 创建新目录
now_time = datetime.datetime.now()
now_time_str = datetime.datetime.strftime(now_time, '%Y_%m_%d_%H_%M_%S')
mkdir(now_time_str)
print("----------下载图片-------------")
i = 0
for m in img_urls:
# 由于没有精确匹配,并不是所有连接都是我们要的课程的连接,排出第一张图片
print('正在下载第' + str(i) + '张:' + m)
# 爬取每个网页图片的连接
img_url = request.urlopen(m).read()
# img 目录【必须手动创建好】
fp = open(now_time_str+'\\' + str(i) + '.jpg', 'wb')
# 写入本地文件
fp.write(img_url)
# 目前没有想到更好的方式,暂时只能写一次,关闭一次,如果有更好的欢迎讨论
fp.close()
i += 1
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片的更多相关文章
- 利用爬虫爬取指定用户的CSDN博客文章转为md格式,目的是完成博客迁移博文到Hexo等静态博客
文章目录 功能 爬取的方式: 设置生成的md文件命名规则: 设置md文件的头部信息 是否显示csdn中的锚点"文章目录"字样,以及下面具体的锚点 默认false(因为csdn中是集 ...
- python网络爬虫进入(一)——简单的博客爬行动物
最近.对于图形微信公众号.互联网收集和阅读一些疯狂的-depth新闻和有趣,发人深思文本注释,并选择最佳的发表论文数篇了.但看着它的感觉是一个麻烦的一人死亡.寻找一个简单的解决方案的方法,看看你是否可 ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- python实战--csdn博客专栏下载器
打算利用业余时间好好研究Python的web框架--web.py,深入剖析其实现原理,体会web.py精巧之美.但在研究源码的基础上至少得会用web.py.思前想后,没有好的Idea,于是打算开发一个 ...
- 从CSDN博客下载的图片如何无损去水印
如果你想下载别人CSDN博客文章中很好看的图片,但却有水印 想要下载去水印的图片,可以先鼠标右击该图片,选择复制图片地址 https://img-blog.csdnimg.cn/20200916140 ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url.标题以及摘要. 实例环境:pytho ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python 爬取CSDN博客频道
初次接触python,写的很简单,开发工具PyCharm,python 3.4很方便 python 部分模块安装时需要其他的附属模块之类的,可以先 pip install wheel 然后可以直接下载 ...
随机推荐
- Android逆向——破解水果大战
最近公司需要测试安卓app安全,但安卓基本上0基础,决定开始学习下安卓逆向根据吾爱破解上教程 <教我兄弟学Android逆向系列课程+附件导航帖> https://www.52pojie. ...
- 进程,多进程,进程与程序的区别,程序运行的三种状态,multiprocessing模块中的Process功能,和join函数,和其他属性,僵尸与孤儿进程
1.进程 什么是进程: 一个正在被运行的程序就称之为进程,是程序具体执行的过程,是一种抽象概念,进程来自操作系统 2.多进程 多个正在运行的程序 在python中实现多线程的方法 from mult ...
- KVM虚拟化网络管理(4)
一.Linux Bridge网桥管理 网络虚拟化是虚拟化技术中最复杂的部分,也是非常重要的资源.第一节中我们创建了一个名为br0的linux-bridge网桥,如果在此网桥上新建一台vm,如下图: V ...
- Mac下搭建Apache+PHP+MySql运行环境
https://www.cnblogs.com/xiaovw/p/8854896.html 前言 我们在Mac上搭建Apache+PHP+MySql环境是非常方便的,因为Mac预装的有Apache和P ...
- redhat 7 防火墙配置
没有iptables 用systemctl stop firewalld
- IIS 404设置
想给自己做的的网站自定义一个404页面,开始 双击红框提示的错误页图标 双击上图红框提示的所示404行 修改上图红框提示的内容如下:我是直接在根目录放了一个自己做的404.html,实际情况要填写你自 ...
- 解决The total number of locks exceeds the lock table size错误
参考:https://blog.csdn.net/weixin_40683253/article/details/80762583 mysql在进行大批量的数据操作时,会报“The total num ...
- java_实现一个类只能声明一个对象
public class StaticDemo { public int a=10; private static StaticDemo s= new StaticDemo(); private St ...
- Python 入门 之 异常处理
Python 入门 之 异常处理 1.异常处理 (1)程序中的错误分为两种 <1> 语法错误 (这种错误,根本过不了Python解释器的语法检测,必须在程序执行前就改正) # 语法错误示范 ...
- python正则表达式的介绍
re模块的使用 re.match从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None. import re # re.match(正则表达式,要匹配的字符串) ...