Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url、标题以及摘要。
实例环境:python3.7
requests库(内置的python库,无需手动安装)
re库(内置的python库,无需手动安装)
实例网站:
第一步,点击网站地址http://www.eastmountyxz.com/,查看页面有哪些信息,网页标题、图片以及摘要等
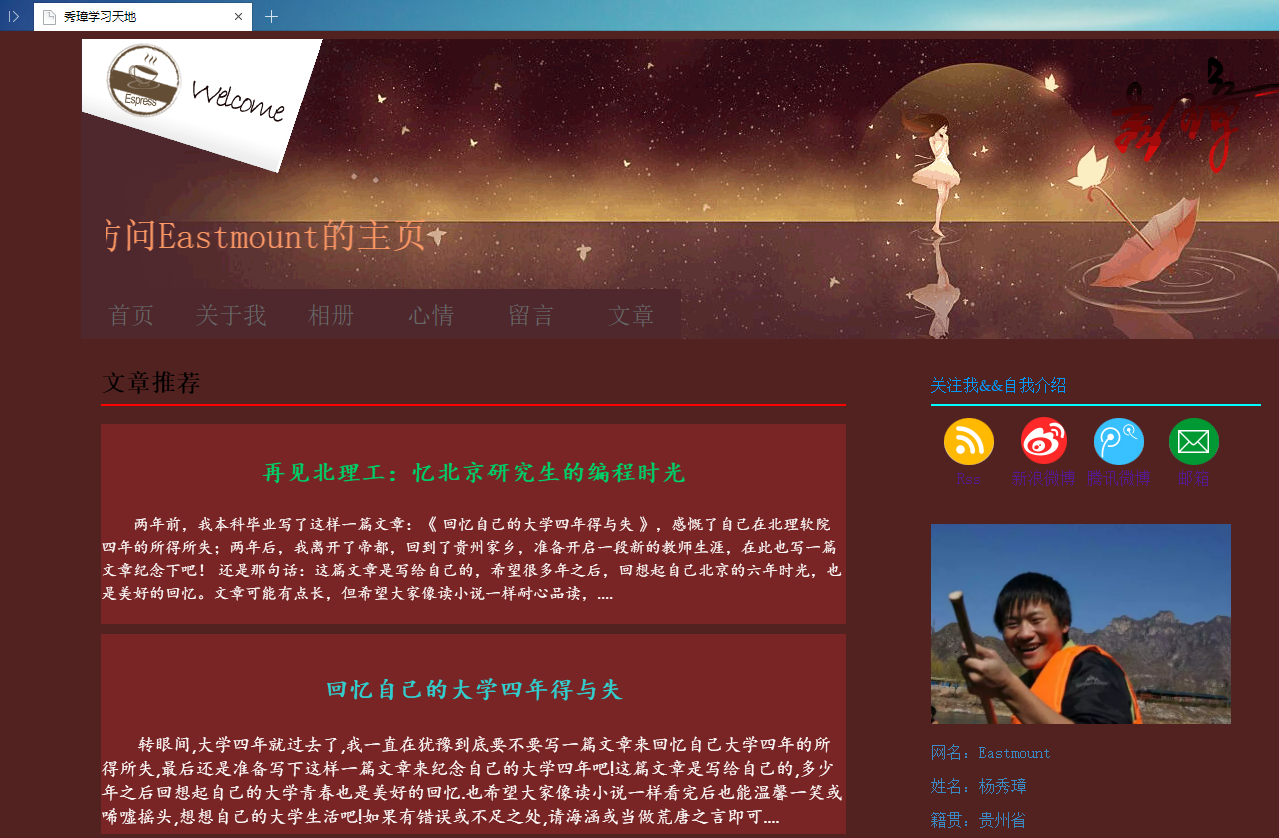
第二步,查看网页源代码,即可看到想要爬取的基本信息


实例代码:
#encoding:utf-8
import re
#import urllib.request
import requests def getHtmlStr(url):
#content = urllib.request.urlopen(url).read().decode("utf-8")
res = requests.get(url)
res.encoding = res.apparent_encoding
return res.text def parseHtml(content):
#爬取整个网页的标题
title = re.findall(r'<title>(.*?)</title>', content)
print(title[0])
#爬取图片地址
urls = re.findall(r'<img .*src="\./(.*?)"', content)
baseUrl = 'http://www.eastmountyxz.com/' for i in range(len(urls)):
urls[i] = baseUrl + urls[i]
print(urls) #爬取文章信息
p = r'<div class="essay.*?">(.*?)</div>'
artcles = re.findall(p, content, re.S)
for a in artcles:
res = r'<a .*href="(.*?)">'
t1 = re.findall(res, a, re.S) #超链接
print(t1[0])
t2 = re.findall(r'<a .*?>(.*?)</a>', a, re.S) #标题
print(t2[0])
t3 = re.findall('<p style=.*?>(.*?)</p>', a, re.S) #摘要(
print(t3[0].replace(' ',''))
print('') if __name__ == '__main__':
url = "http://www.eastmountyxz.com/"
htmlString = getHtmlStr(url)
parseHtml(htmlString)
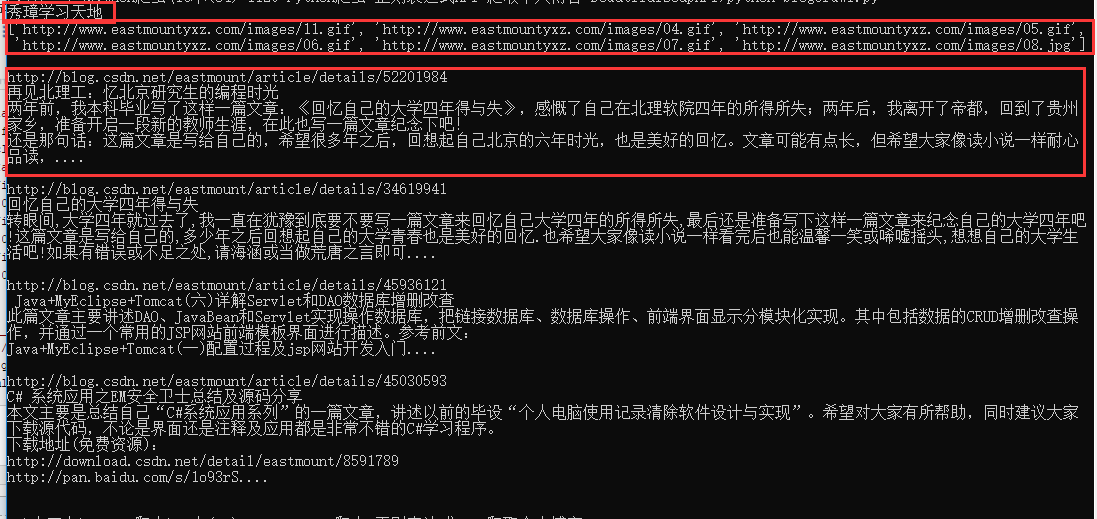
实例结果:
Python爬虫学习之正则表达式爬取个人博客的更多相关文章
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Python爬虫之利用正则表达式爬取内涵吧
首先,我们来看一下,爬虫前基本的知识点概括 一. match()方法: 这个方法会从字符串的开头去匹配(也可以指定开始的位置),如果在开始没有找到,立即返回None,匹配到一个结果,就不再匹配. 我们 ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫学习笔记之爬取新浪微博
import requests from urllib.parse import urlencode from pyquery import PyQuery as pq from pymongo im ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
随机推荐
- java_28 序列化与反序列化
1.序列化和反序列化 序列化:把对象转换为字节序列的过程称为对象的序列化.(常见的就是存文件) 反序列化:把字节序列恢复为对象的过程称为对象阿德反序列化. 2.序列化和反序列化的使用: java.io ...
- inline, block, and inline-block
总体概念 block和inline这两个概念是简略的说法,完整确切的说应该是 block-level elements (块级元素) 和 inline elements (内联元素).block元素通 ...
- 【Rails App】 应用服务器从Passenger切换为Puma, Grape出现线程安全问题
Grape中的代码如下: def market @market ||= Market.find(params[:id]) end @market基于类层次的实例变量,属于非线程安全,如果一直使用多线程 ...
- 为什么text的值改变后onchange没有反应?
onchange发生在元素失去焦点后,而不是想象中的元素的值发生改变的时候.其实它的作用就跟onblur(失去焦点事件)差不多,只不过onchange是失去焦点且值发生了改变.要想实现目的,可以改用o ...
- .NET、JAVA和PHP在Web开发的优缺点
现在做Web开发,用哪个平台哪种语言其实本质上没有太大的区别,因为Web开发框架已经非常成熟,只要符合需求,能按时交付产品就ok了. 要选择哪个平台,是个商业问题,不是技术问题. 选择任何的语言最好深 ...
- Vue添加jquer插件
一.现象 综合开发需要,需要引用使用 二.解决 1.先安装jquer插件,命令运行: npm i jquery --save-dev (tips: i 也就是 install --save-dev ...
- Java 字符编码(二)Java 中的编解码
Java 字符编码(二)Java 中的编解码 java.nio.charset 包中提供了一套处理字符编码的工具类,主要有 Charset.CharsetDecoder.CharsetEncoder. ...
- python数据结构(二)------元组
元组是不可变序列,因此,元组的操作非常简单,本文就简单介绍一下,并解释下元组存在的意义: 2.2.1 元组的创建 2.2.2 tuple函数 2.2.3 基本元组操作 2.2.4 元组存在的意义 2. ...
- 跟踪SQL
在数据库中,找到以下页面,并选择事件中的Tsql下的bath...与stm...
- 高速上手C++11 14 笔记2
lambda表达式和std function bind 两者配合构成了函数新的使用方法. 智能指针 sharedptr, uniqueptr, weak_ptr auto pointer = std: ...