我要进大厂之大数据Hadoop HDFS知识点(1)

01 我们一起学大数据
老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点!(每个点都很重要,都不能忽视)
02 需谨记的知识点
第1点:Hadoop是什么?
Hadoop,它是Apache开发的一个分布式系统基础架构,由三个模块组成:分布式存储的HDFS、分布式计算的MapReduce、资源调度引擎Yarn。
第2点:什么是分布式?
这个问题的回答,老刘是在某个机构看到的,它说的是利用一批通过网络连接的、廉价普通的机器,完成单个机器无法完成的存储、计算任务。
第3点:HDFS是什么?
HDFS,一看就是英文缩写,全称是Hadoop Distributed File System,翻译过来就是Hadoop的分布式文件系统。在HDFS中,大量的文件可以分散的存储在不同的服务器上边,单个文件比较大,单块磁盘块下,可以切分成很多小的block,然后分散存储在不同的服务器上边,各个服务器通过网络连接,形成一个整体
第4点:HDFS命令使用
在老刘看来,至少要记住几个HDFS常用的命令,以免面试官问起来,自己想不起来。
1、查看已创建的文件
hdfs dfs -ls / 2、在hdfs文件系统中创建文件
hdfs dfs -touchz /test.txt 3、查看HDFS文件内容
hdfs dfs -cat /test.txt 4、从本地路径上传文件至HDFS
hdfs dfs -put /本地路径 /hdfs路径 5、在hdfs文件系统中下载文件
hdfs dfs -get /hdfs路径 /本地路径 6、在hdfs文件系统中创建目录
hdfs dfs -mkdir /test01 7、在hdfs文件系统中删除文件
hdfs dfs -rm /edits.txt
这个格外要注意,删除有很多种,这只是其中一种!!! 8、在hdfs文件系统中修改文件名称
hdfs dfs -mv /test.sh /test01.sh
第5点:HDFS核心概念数据块block
什么是HDFS block块?
在HDFS3.0上的文件,它是按照128M为单位,切分成一个个block,分散的存储在集群的不同的不用数据节点DataNode上。
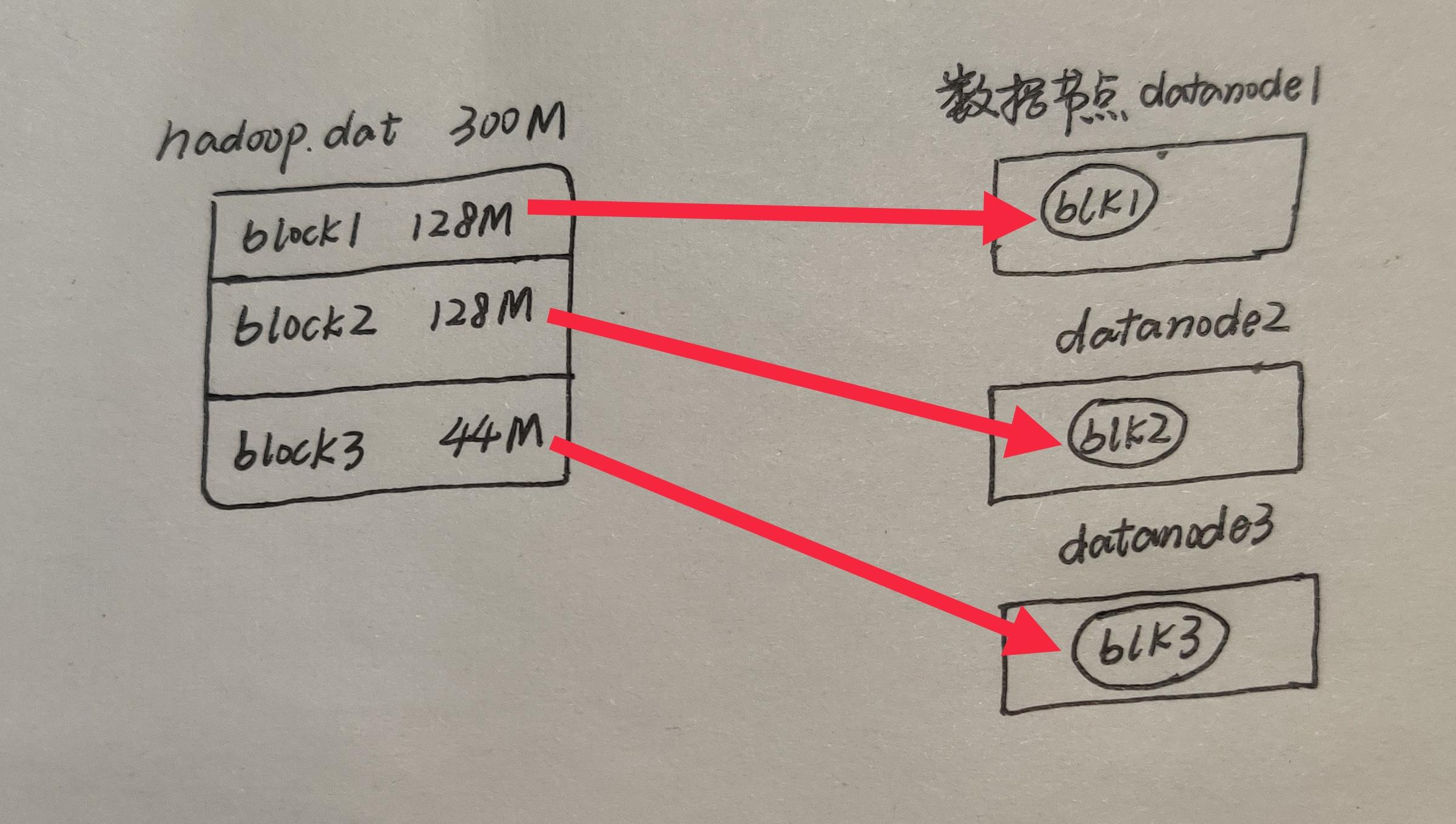
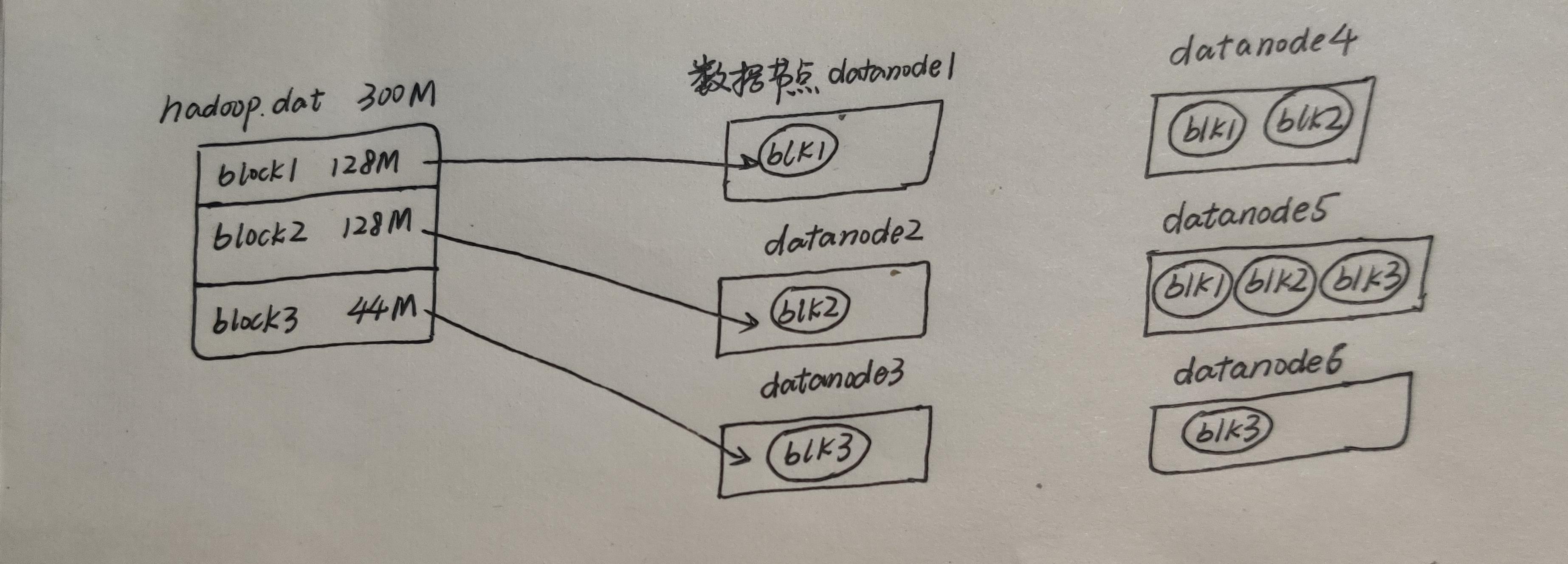
看看上面这张图,就可以知道block是如何分布的。但是这样分布有个非常明显的缺陷,那就是如果其中一个数据节点DataNode1挂掉,它所存储的block就丢失了,所以,为保证数据的可用及容错,HDFS设计成每个block共有三份,即三个副本,并且在hdfs-site.xml中设置副本数:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
那么现在的block存储是这样的:
第6点:画出HDFS架构图

根据这张图就可以知道HDFS是主从架构,Master|Slave或称为管理节点|工作节点。
第7点:说一说NameNode
NameNode,它主要用来管理节点,以及管理HDFS的元数据信息,并且将元数据存储在其内存中。
其中,要知道元数据信息的概念!!!
关于文件或目录的描述信息,如文件所在路径、文件名称、文件类型等等,这些信息称为文件的元数据metadata。
而HDFS元数据信息是文件目录树、整棵树所有的文件和目录、每个文件的块列表、每个block块所在的datanode列表等。其中,每个文件、目录、block占用大概150Byte字节的元数据。
HDFS元数据信息以两种形式保存:①编辑日志edits log②命名空间镜像文件fsimage。其中,fsimage:元数据镜像文件,保存了文件系统目录树信息以及文件和块的对应关系;edits log:日志文件,保存文件系统的更改记录。
在这里,老刘有些话想说,老刘刚开始也对元数据信息不是很在意,可在慢慢学习的过程中,不停地遇到元数据信息这个概念,当时就会纳闷这元数据到底是个什么玩意,于是又回头来重新看浪费了好多时间,所以一定要牢记!!!
第8点:说一说DataNode
DataNode,数据节点,它是用来存储block以及block元数据,此处的元数据包括数据块的长度、块数据的校验和、时间戳。
第9点:说一说Secondary NameNode(注意,不能忽略它)
首先说一下,为什么元数据存储在NameNode在内存中?
因为这样做了后,客户端请求数据的话,可以直接与NameNode读取,读取速度就会特别快。
但是这样做是有问题的,有什么问题呢?
就是一旦系统崩溃就会导致数据丢失。
但是这个问题怎么解决呢?
这里就要说,在NameNode节点中的编辑日志editlog中,记录下来客户端对HDFS的所有更改的记录,一旦系统出故障,可以从editlog进行恢复。
说了这么多,老刘下面就可以好好讲讲Secondary NameNode了。用户操作请求一般是直接卸载内存里面,然后持久化到磁盘里面的fsimage中,磁盘中还会记录日志edits log,随着NameNode的长时间运行,记录日志就会越来越多。但此时NameNode停了,内存中的数据消失了,重新启动NameNode后,它会加载磁盘中的fsimage文件接着合并日志记录文件,然后合并成一个完整的fsimage文件,但如果edits log文件特别多的话,NameNode恢复时间就会特别长,所有为了避免这种情况,就有了Secondary NameNode,它就是辅助NameNode合并元数据,加快NameNode下一次启动的速度。(这里还有一个要说的是,大家是不是很少看到它,举个例子,在ZooKeeper实现的Hadoop HA中,它的活由Standby NameNode干了)接下里,Secondary NameNode的工作流程就如下图所示:
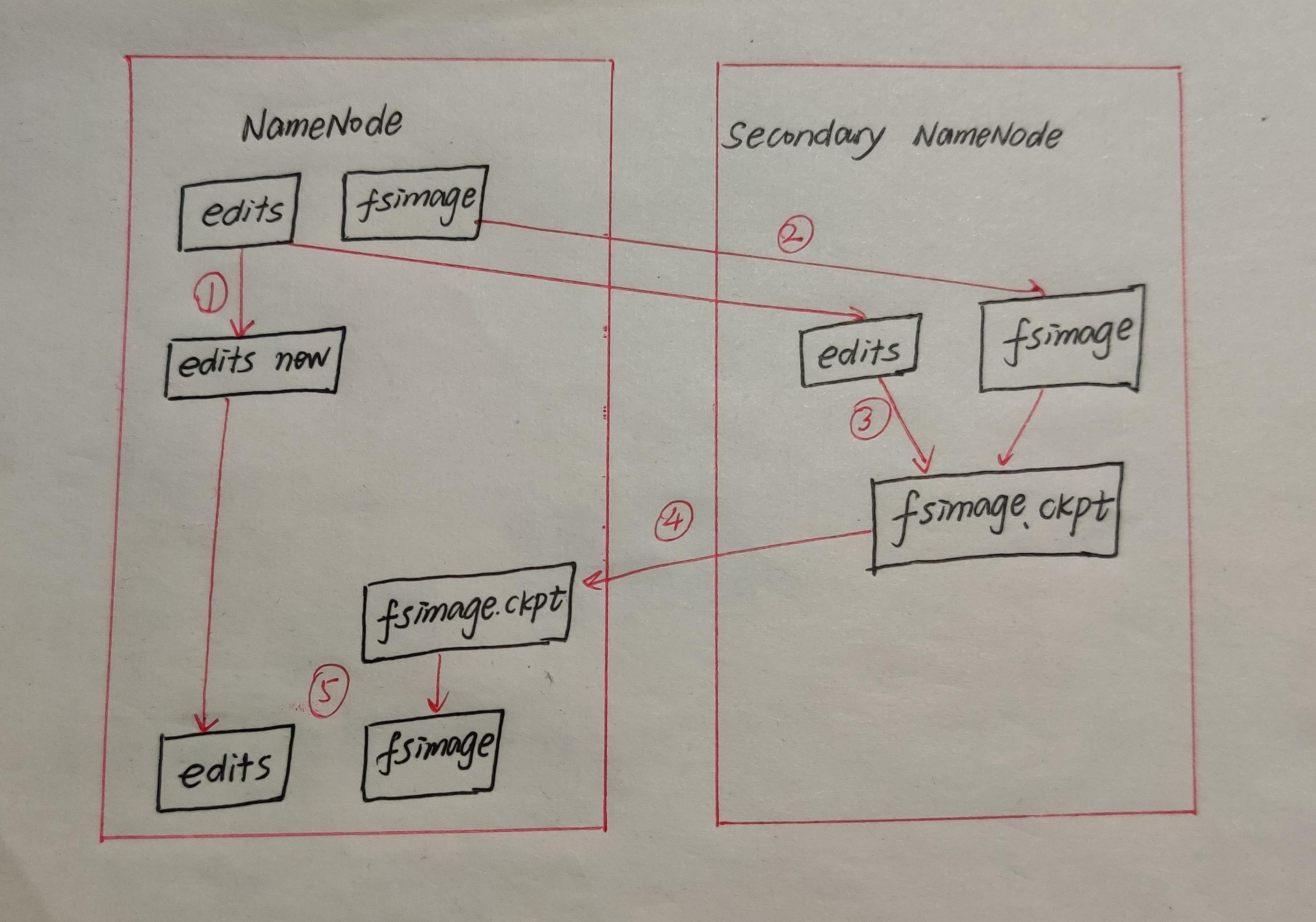
1、NameNode管理着元数据信息,元数据信息会定期刷新到磁盘中,其中两个文件是edits log操作日志文件和fsimage元数据镜像文件。在产生新的日志操作文件后,它不会立即和fsimage合并,也不会刷到NameNode内存中,而是先会edits log中,当edits文件大小达到一个临界值(64M)或者间隙1小时的时候,checkpoint检查点会触发Secondary NameNode工作。
2、当触发一个checkpoint时,NameNode会生成一个新的edits.new,同时Secondary NameNode会将edits和fsimage复制到本地。
3、Secondary NameNode会将本地的fsimage文件加载到内存中,然后和edits文件进行合并生成一个新的fsimage.ckpt文件。
4、Secondary NameNode将新生成的fsimage.ckpt文件复制到NameNode 节点。
5、在NameNode节点的edits.new和fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此就完成了一个轮回,等待下一个checkpoint触发。
03 总结
今天的大数据Hadoop中的HDFS知识点总结就到这里了,这次是先把HDFS的基础知识点总结了一遍,下次把HDFS的一些架构知识总结分享出来,希望能够对想学大数据的同学有帮助,也希望能够得到大佬的批评和指点。
最后,有事,公众号:努力的老刘,联系;没事,就和老刘一起学大数据。
我要进大厂之大数据Hadoop HDFS知识点(1)的更多相关文章
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 我要进大厂之大数据MapReduce知识点(1)
01 我们一起学大数据 老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分.老 ...
- 我要进大厂之大数据ZooKeeper知识点(1)
01 让我们一起学大数据 老刘又回来啦!在实验室师兄师姐都找完工作之后,在结束各种科研工作之后,老刘现在也要为找工作而努力了,要开始大数据各个知识点的复习总结了.老刘会分享出自己的知识点总结,一是希望 ...
- 我要进大厂之大数据ZooKeeper知识点(2)
01 我们一起学大数据 接下来是大数据ZooKeeper的比较偏架构的部分,会有一点难度,老刘也花了好长时间理解和背下来,希望对想学大数据的同学有帮助,也特别希望能够得到大佬的批评和指点. 02 知识 ...
- 我要进大厂之大数据MapReduce知识点(2)
01 我们一起学大数据 今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大 ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
- 大数据Hadoop——HDFS Shell操作
一.查询目录下的文件 1.查询根目录下的文件 Hadoop fs -ls / 2.查询文件夹下的文件 Hadoop fs -ls /input 二.创建文件夹 hadoop fs -mkdir /文件 ...
- 大数据hadoop面试题2018年最新版(美团)
还在用着以前的大数据Hadoop面试题去美团面试吗?互联网发展迅速的今天,如果不及时更新自己的技术库那如何才能在众多的竞争者中脱颖而出呢? 奉行着"吃喝玩乐全都有"和"美 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
随机推荐
- 第五章 NFS、rsync等统一用户相关操作
一.统一用户 1.httpd2.NFS挂载目录3.rsync 1.所有服务器统一创建用户 [root@web01 ~]# groupadd www -g 666[root@web01 ~]# user ...
- Ansible之YAML语言
playbook写yml语句,若干模块发给Ansible,变成一个一个play,多个片段组合起来变成大片. 最终还是要读取主机清单,来确定作用在哪些机器上. YAML语言 YAML是一个可读性高的用来 ...
- matlab cvx工具箱解决线性优化问题
题目来源:数学建模算法与应用第二版(司守奎)第一章习题1.4 题目说明 作者在答案中已经说明,求解上述线性规划模型时,尽量用Lingo软件,如果使用Matlab软件求解,需要做变量替换,把二维决策变量 ...
- .net core2.2 HealthChecks记录
abp core2.2版时使用 healthChecks使用:安装nuget包:Microsoft.AspNetCore.Diagnostics.HealthChecks startup.cs 中的 ...
- git学习(四) git log操作
git log操作 log命令的作用:用于查看git的提交历史: git log命令显示的信息的具体含义: commit SHA-1 校验和 commit id Author 作者跟邮箱概要信息 D ...
- CTCall简介(后续会继续补充)
使用CTCall需要导入CoreTelephony.framework框架. CTCall的基本使用 (1)初始化call CFStringRef number = CFSTR("15555 ...
- 接口中字段的修饰符:public static final(默认不写) 接口中方法的修饰符:public abstract(默认不写)abstract只能修饰类和方法 不能修饰字段
abstract只能修饰类和方法 不能修饰字段
- Python作业1
name = " aleX" # 1 移除 name 变量对应的值两边的空格,并输出处理结果 print(name.strip()) # 2 判断 name 变量对应的值是否以 & ...
- 简单粗暴套娃模式组json发送https请求
各位童鞋大家好,向来简单粗暴的铁柱兄给大家来玩一手套娃模式来组Json数据,不说别的,无脑套. 当然,这一手比较适合临场用一下,若长期用的话建议搞一套适用的框架,只管set就好了.话不多说开始上课. ...
- Linux使用tmux
Tmux功能: 提供了强劲的.易于使用的命令行界面.可横向和纵向分割窗口.窗格可以自由移动和调整大小,或直接利用四个预设布局之一.支持 UTF-8 编码及 256 色终端.可在多个缓冲区进行复制和粘贴 ...