我要进大厂之大数据Hadoop HDFS知识点(1)

01 我们一起学大数据
老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点!(每个点都很重要,都不能忽视)
02 需谨记的知识点
第1点:Hadoop是什么?
Hadoop,它是Apache开发的一个分布式系统基础架构,由三个模块组成:分布式存储的HDFS、分布式计算的MapReduce、资源调度引擎Yarn。
第2点:什么是分布式?
这个问题的回答,老刘是在某个机构看到的,它说的是利用一批通过网络连接的、廉价普通的机器,完成单个机器无法完成的存储、计算任务。
第3点:HDFS是什么?
HDFS,一看就是英文缩写,全称是Hadoop Distributed File System,翻译过来就是Hadoop的分布式文件系统。在HDFS中,大量的文件可以分散的存储在不同的服务器上边,单个文件比较大,单块磁盘块下,可以切分成很多小的block,然后分散存储在不同的服务器上边,各个服务器通过网络连接,形成一个整体
第4点:HDFS命令使用
在老刘看来,至少要记住几个HDFS常用的命令,以免面试官问起来,自己想不起来。
1、查看已创建的文件
hdfs dfs -ls / 2、在hdfs文件系统中创建文件
hdfs dfs -touchz /test.txt 3、查看HDFS文件内容
hdfs dfs -cat /test.txt 4、从本地路径上传文件至HDFS
hdfs dfs -put /本地路径 /hdfs路径 5、在hdfs文件系统中下载文件
hdfs dfs -get /hdfs路径 /本地路径 6、在hdfs文件系统中创建目录
hdfs dfs -mkdir /test01 7、在hdfs文件系统中删除文件
hdfs dfs -rm /edits.txt
这个格外要注意,删除有很多种,这只是其中一种!!! 8、在hdfs文件系统中修改文件名称
hdfs dfs -mv /test.sh /test01.sh
第5点:HDFS核心概念数据块block
什么是HDFS block块?
在HDFS3.0上的文件,它是按照128M为单位,切分成一个个block,分散的存储在集群的不同的不用数据节点DataNode上。
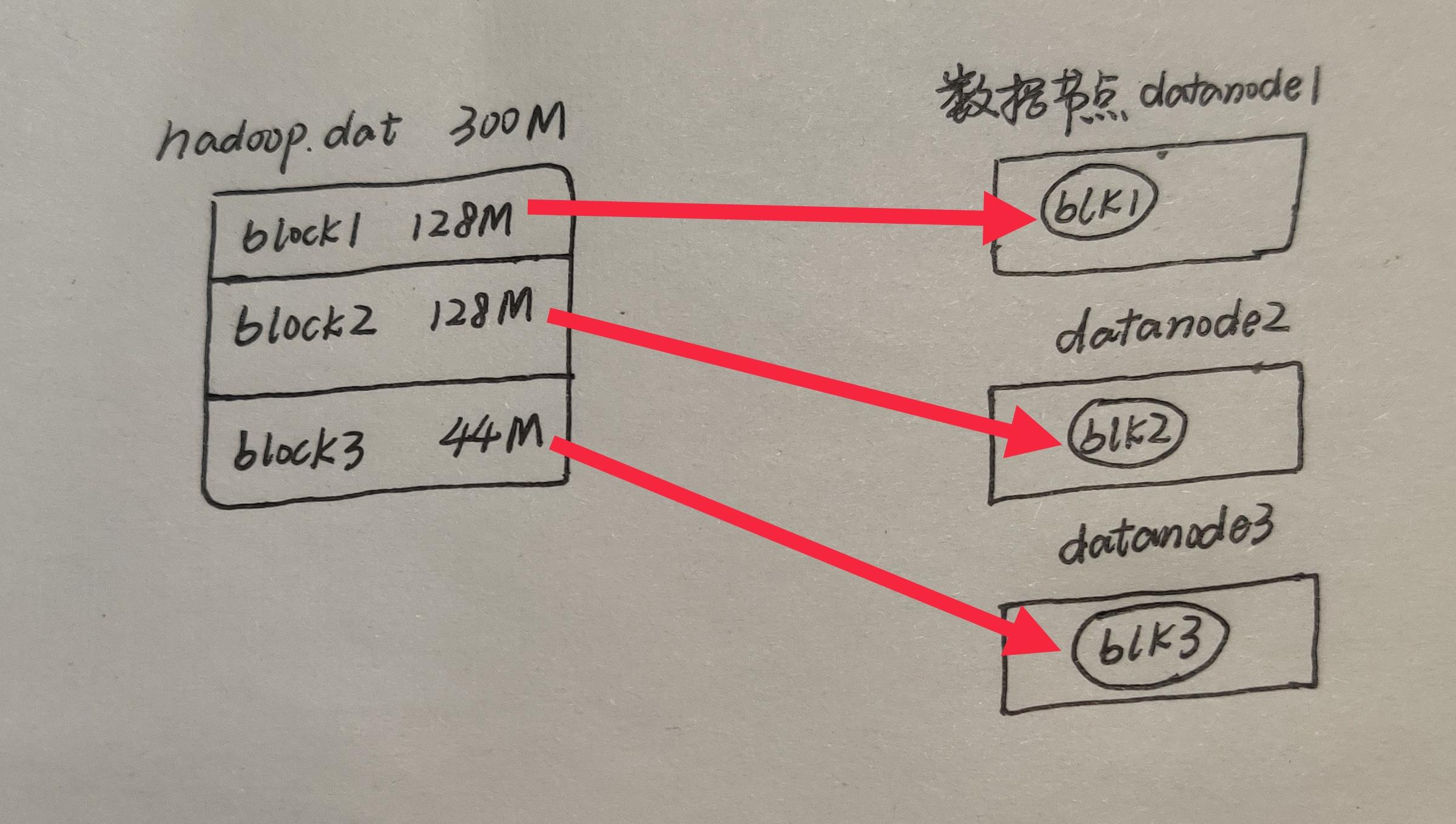
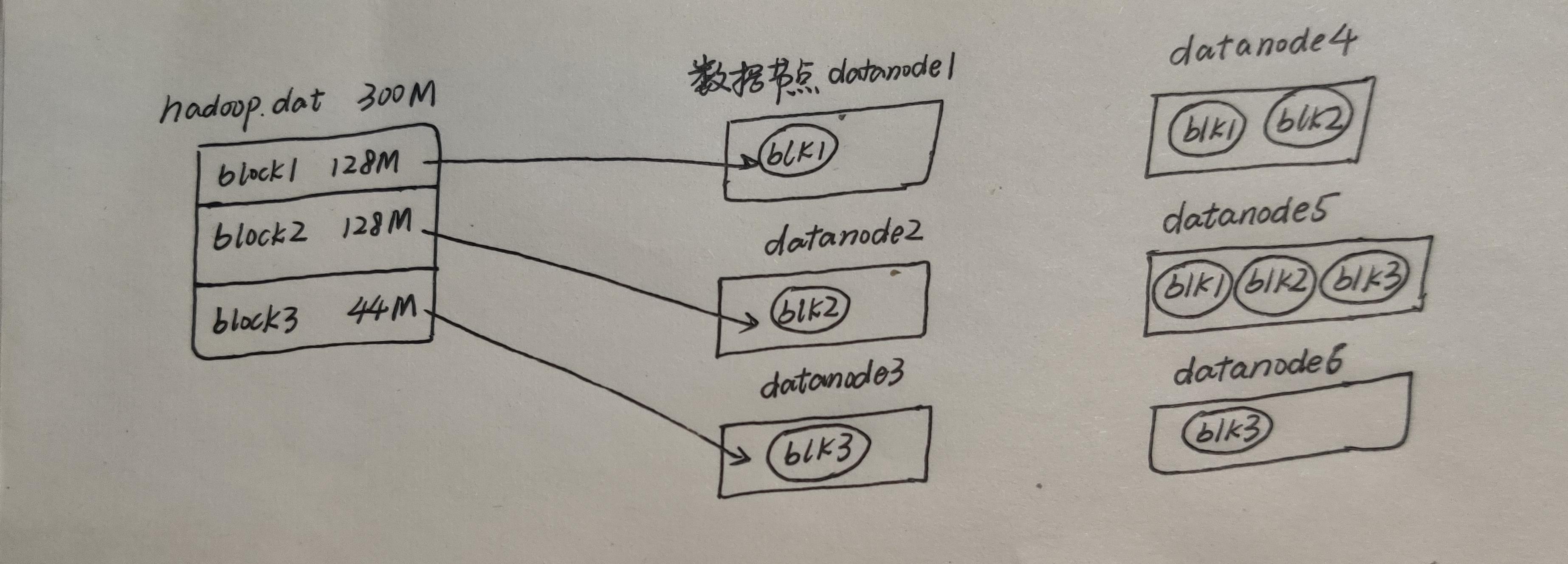
看看上面这张图,就可以知道block是如何分布的。但是这样分布有个非常明显的缺陷,那就是如果其中一个数据节点DataNode1挂掉,它所存储的block就丢失了,所以,为保证数据的可用及容错,HDFS设计成每个block共有三份,即三个副本,并且在hdfs-site.xml中设置副本数:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
那么现在的block存储是这样的:
第6点:画出HDFS架构图

根据这张图就可以知道HDFS是主从架构,Master|Slave或称为管理节点|工作节点。
第7点:说一说NameNode
NameNode,它主要用来管理节点,以及管理HDFS的元数据信息,并且将元数据存储在其内存中。
其中,要知道元数据信息的概念!!!
关于文件或目录的描述信息,如文件所在路径、文件名称、文件类型等等,这些信息称为文件的元数据metadata。
而HDFS元数据信息是文件目录树、整棵树所有的文件和目录、每个文件的块列表、每个block块所在的datanode列表等。其中,每个文件、目录、block占用大概150Byte字节的元数据。
HDFS元数据信息以两种形式保存:①编辑日志edits log②命名空间镜像文件fsimage。其中,fsimage:元数据镜像文件,保存了文件系统目录树信息以及文件和块的对应关系;edits log:日志文件,保存文件系统的更改记录。
在这里,老刘有些话想说,老刘刚开始也对元数据信息不是很在意,可在慢慢学习的过程中,不停地遇到元数据信息这个概念,当时就会纳闷这元数据到底是个什么玩意,于是又回头来重新看浪费了好多时间,所以一定要牢记!!!
第8点:说一说DataNode
DataNode,数据节点,它是用来存储block以及block元数据,此处的元数据包括数据块的长度、块数据的校验和、时间戳。
第9点:说一说Secondary NameNode(注意,不能忽略它)
首先说一下,为什么元数据存储在NameNode在内存中?
因为这样做了后,客户端请求数据的话,可以直接与NameNode读取,读取速度就会特别快。
但是这样做是有问题的,有什么问题呢?
就是一旦系统崩溃就会导致数据丢失。
但是这个问题怎么解决呢?
这里就要说,在NameNode节点中的编辑日志editlog中,记录下来客户端对HDFS的所有更改的记录,一旦系统出故障,可以从editlog进行恢复。
说了这么多,老刘下面就可以好好讲讲Secondary NameNode了。用户操作请求一般是直接卸载内存里面,然后持久化到磁盘里面的fsimage中,磁盘中还会记录日志edits log,随着NameNode的长时间运行,记录日志就会越来越多。但此时NameNode停了,内存中的数据消失了,重新启动NameNode后,它会加载磁盘中的fsimage文件接着合并日志记录文件,然后合并成一个完整的fsimage文件,但如果edits log文件特别多的话,NameNode恢复时间就会特别长,所有为了避免这种情况,就有了Secondary NameNode,它就是辅助NameNode合并元数据,加快NameNode下一次启动的速度。(这里还有一个要说的是,大家是不是很少看到它,举个例子,在ZooKeeper实现的Hadoop HA中,它的活由Standby NameNode干了)接下里,Secondary NameNode的工作流程就如下图所示:
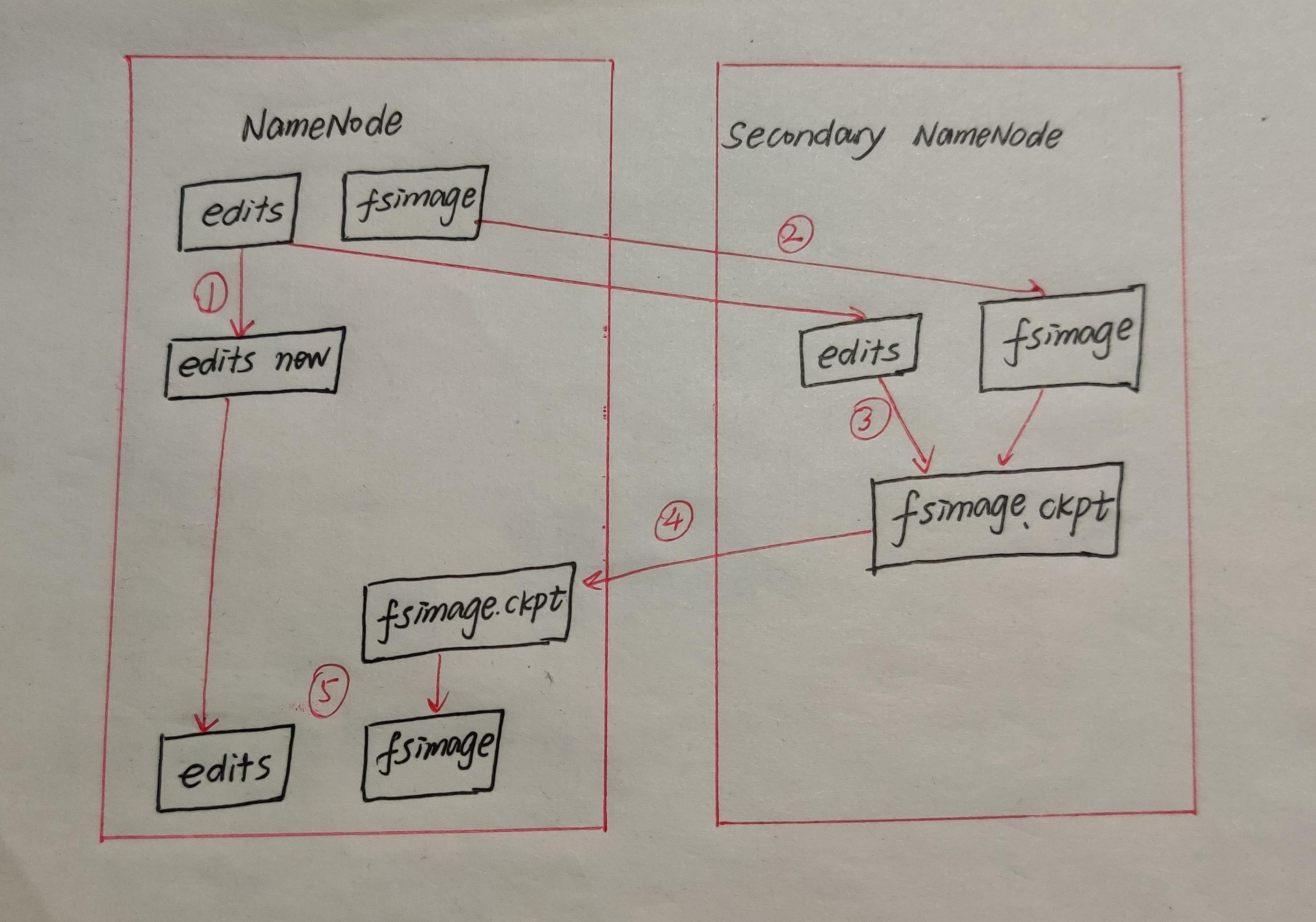
1、NameNode管理着元数据信息,元数据信息会定期刷新到磁盘中,其中两个文件是edits log操作日志文件和fsimage元数据镜像文件。在产生新的日志操作文件后,它不会立即和fsimage合并,也不会刷到NameNode内存中,而是先会edits log中,当edits文件大小达到一个临界值(64M)或者间隙1小时的时候,checkpoint检查点会触发Secondary NameNode工作。
2、当触发一个checkpoint时,NameNode会生成一个新的edits.new,同时Secondary NameNode会将edits和fsimage复制到本地。
3、Secondary NameNode会将本地的fsimage文件加载到内存中,然后和edits文件进行合并生成一个新的fsimage.ckpt文件。
4、Secondary NameNode将新生成的fsimage.ckpt文件复制到NameNode 节点。
5、在NameNode节点的edits.new和fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此就完成了一个轮回,等待下一个checkpoint触发。
03 总结
今天的大数据Hadoop中的HDFS知识点总结就到这里了,这次是先把HDFS的基础知识点总结了一遍,下次把HDFS的一些架构知识总结分享出来,希望能够对想学大数据的同学有帮助,也希望能够得到大佬的批评和指点。
最后,有事,公众号:努力的老刘,联系;没事,就和老刘一起学大数据。
我要进大厂之大数据Hadoop HDFS知识点(1)的更多相关文章
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 我要进大厂之大数据MapReduce知识点(1)
01 我们一起学大数据 老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分.老 ...
- 我要进大厂之大数据ZooKeeper知识点(1)
01 让我们一起学大数据 老刘又回来啦!在实验室师兄师姐都找完工作之后,在结束各种科研工作之后,老刘现在也要为找工作而努力了,要开始大数据各个知识点的复习总结了.老刘会分享出自己的知识点总结,一是希望 ...
- 我要进大厂之大数据ZooKeeper知识点(2)
01 我们一起学大数据 接下来是大数据ZooKeeper的比较偏架构的部分,会有一点难度,老刘也花了好长时间理解和背下来,希望对想学大数据的同学有帮助,也特别希望能够得到大佬的批评和指点. 02 知识 ...
- 我要进大厂之大数据MapReduce知识点(2)
01 我们一起学大数据 今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大 ...
- 大数据 - hadoop - HDFS+Zookeeper实现高可用
高可用(Hign Availability,HA) 一.概念 作用:用于解决负载均衡和故障转移(Failover)问题. 问题描述:一个NameNode挂掉,如何启动另一个NameNode.怎样让两个 ...
- 大数据Hadoop——HDFS Shell操作
一.查询目录下的文件 1.查询根目录下的文件 Hadoop fs -ls / 2.查询文件夹下的文件 Hadoop fs -ls /input 二.创建文件夹 hadoop fs -mkdir /文件 ...
- 大数据hadoop面试题2018年最新版(美团)
还在用着以前的大数据Hadoop面试题去美团面试吗?互联网发展迅速的今天,如果不及时更新自己的技术库那如何才能在众多的竞争者中脱颖而出呢? 奉行着"吃喝玩乐全都有"和"美 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
随机推荐
- ps命令没有显示路径找到命令真实路径
top发现某程序占用大量资源,但ps查看看不到程序真实路径,查找真实路径. ps aux |grep COMMAND 找到PID ls /proc/ 里边有很多数字文件夹,找到PID相应的文件夹进去看 ...
- 接收某项课程id,通过axios发起get请求,由于携带params出现的问题(已解决)
问题:在最新课程页面(NewBook.vue)点击某一项课程,通过传递该课程的 id 跳转至课程详情页(Bookdetail.vue),采取的跳转方式是声明式导航,即 <router-link ...
- Promise 配合 axios 使用
Promise是一个构造函数,自己身上有all.reject.resolve这几个眼熟的方法,原型上有then.catch等同样很眼熟的方法 很细致的Promise使用详解 自己脑补 vue 工程化的 ...
- mysql-connector-java各种版本下载地址
mysql-connector-java下载地址: http://mvnrepository.com/artifact/mysql/mysql-connector-java 目录 1.进去后选择自己的 ...
- Learn day6 模块pickle\json\random\os\zipfile\面对对象(类的封装 操作 __init__)
1.模块 1.1 pickle模块 # ### pickle 序列化模块 import pickle """ 序列化: 把不能够直接存储的数据变得可存储 反序列化: 把数 ...
- Python使用协程进行爬虫
详情点我跳转 关注公众号"轻松学编程"了解更多. 1.协程 协程,又称微线程,纤程.英文名Coroutine. 协程是啥 ?? 首先我们得知道协程是啥?协程其实可以认为是比线程更小 ...
- Django项目登录注册系统
Django项目之个人网站 关注公众号"轻松学编程"了解更多. Github地址:https://github.com/liangdongchang/MyWeb.git 感兴趣的可 ...
- 浅谈 Tarjan 算法
目录 简述 作用 Tarjan 算法 原理 出场人物 图示 代码实现 例题 例题一 例题二 例题三 例题四 例题五 总结 简述 对于初学 Tarjan 的你来说,肯定和我一开始学 Tarjan 一样无 ...
- 《Google软件测试之道》 第一章google软件测试介绍
前段时间比较迷茫,没有明确的学习方向和内容.不过有一点应该是可以肯定的:迷茫的时候就把空闲的时间用来看书吧! 这本书,目前只是比较粗略的看了一遍,感触很大.以下是个人所作的笔记,与原文会有出入的地方. ...
- 程序人生|从网瘾少年到微软、BAT、字节offer收割机逆袭之路
有情怀,有干货,微信搜索[三太子敖丙]关注这个不一样的程序员. 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点.资料以及我的系列文章. ...