python爬虫笔记Day01
python爬虫笔记第一天
Requests库的安装
- 先在cmd中pip install requests
- 再打开Python IDM写入import requests
- 完成requests在.py文件的安装和引入
Requests库的入门
示例(爬取百度首页内容):
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.encoding = 'utf-8'
>>> r.text
'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">登录</a>\');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
requests库的7个主要方法
方法 说明 requests.requests() 构造一个请求,支撑以下各个方法的基础 requests.get() 获取HTML网页的主要方法,对应于HTTP的GET requests.head() 获取HTML网页 头信息的方法,对应于HTTP的HEAD reqeusts.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH reqeusts.delete() 向HTML网页提交删除请求,对应于HTTP的DELETE r=requests.get()
构造一个向服务器请求资源的Requests对象,返回的内容用r来表示,r是一个Response对象,返回的是包含服务器所有相关资源的对象
requests.get(url,params=None,**kwargs)
- url:拟获取页面的URL链接
- params:URL中的额外参数,紫癜或字节流格式
- **kwargs:12个控制访问的参数
get()方法的封装方式(最后一行)

Requests库的2个重要对象
Response
包含爬虫返回的内容
Response对象的属性
属性 说明 r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败(可以说除了200以外都是没有连接成功) r.text HTTP响应内容的字符串形式,即,URL对应的页面内容 r.encoding 从HTTP header中猜测响应内容编码方式 r.apparent_encoding 从内容中分析出响应内容编码方式 r.content HTTP响应内容的二进制形式 - r.encoding:如果header中不存在charset,则认为编码为ISO-8859-1,根本上讲是一种猜测编码方式的结果
- r.apparent_encoding:根据网页内容真正分析而得出的编码方式
Requests
使用get()方法获取网上资源基本流程
首先,r.status_code 判断连接状态:
如果:200 连接成功,则:
r.text
r.enciding
r.apparent_encoding
从内容中分析出响应内容编码方式 r.content
如果:404或者其他原因产生异常
爬取通用代码框架
通用代码框架?
一组代码,可以准确可靠的爬取网页上的代码
Requests库的异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如URL的DNS查询失败、服务器的防火墙拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLError | URL缺失异常(访问时) |
| requests.TooManyRedirects | 用户访问的URL重定向超过了服务器要求的最大重定向次数,产生此异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常(仅仅是连接服务器的超时) |
| requests.Timeout | 请求URL超时→超时异常(发出请求到获得内容的超时) |
方法
| 方法 | 说明 |
|---|---|
| r.raise_for_status() | 如果不是200,产生异常requests.HTTPError |
该方法可以判断连接的状态
通用代码框架
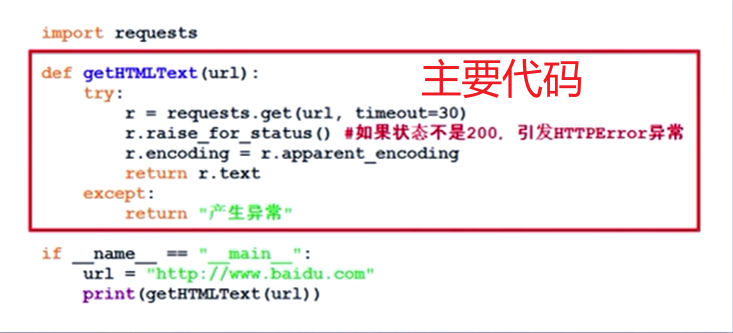
通用代码框架可以使得用户爬取网页时更加有效安全
HTTP协议及Requests库方法
Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
HTTP协议采用URL作为定位网络资源的标识
——百科
URL格式 http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80
path:请求资源的路径
HTTP URL实例:
HTTP URL:
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
HTTP协议对资源的操作
| 方法 | 说明 |
|---|---|
| get | 请求获取URL位置的资源 |
| head | 请求获取URL位置资源的响应响应信息报告,即获得该资源的头部信息 |
| post | 请求向URL位置的资源后附加新的数据 |
| put | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| patch | 请求局部更新URL位置的资源,即改变该出资源的部分内容 |
| delete | 请求删除URL位置存储的资源 |

各个操作之间是独立的
理解patch和put的区别
假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段
需求:用户修改了UserName,其他不变。
- 采用PATCH,仅向URL提交UserName的局部更新请求。
- 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除。
PATCH的最主要好处:节省网络带宽
HTTP协议与Requests库

Requests库的head()方法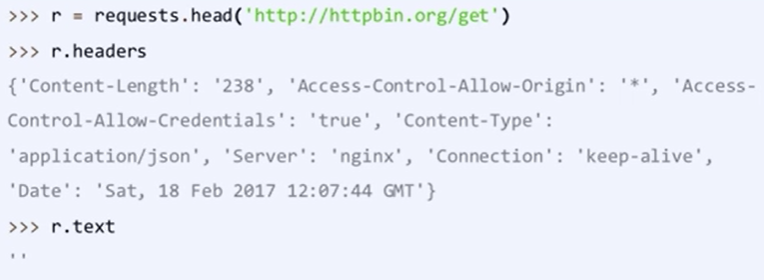
- head()方法可以使用很少的流量来获取网页的概要信息
Requests库的head()方法
{kind=link}
当向URL post一个字典或者键值对时,键值对会被自动编码为form表单 ——MOOC_嵩天

Requests库的put()方法
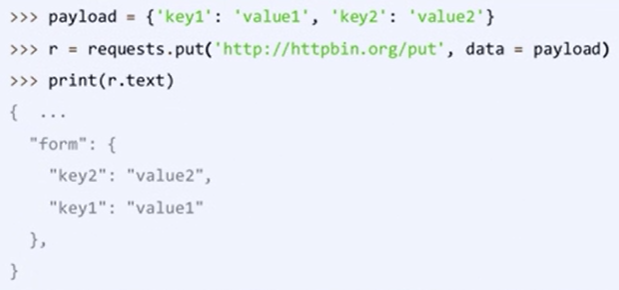
可以将原有的数据覆盖掉 ——MOOC_嵩天
Request库方法主要解析
requests库的7个主要方法
| 方法 | 说明 |
|---|---|
| requests.requests() | 构造一个请求,支撑以下各个方法的基础 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页 头信息的方法,对应于HTTP的HEAD |
| reqeusts.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| reqeusts.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
Request方法
request方法是所有方法的基础,包含三个基本参数:method、url、**kwargs
eg. r=requests.requests(method, url, **kwargs)
| 参数 | 参数含义 |
|---|---|
| method | 请求方式 |
| url | 拟获取页面的URL链接 |
| **kwargs | 控制访问的参数,共13个 |
其中,method参数可以分为以下几种:
r=requests.requests(‘GET’, url, **kwargs)
r=requests.requests(‘HEAD’, url, **kwargs)
r=requests.requests(‘POST’, url, **kwargs)
r=requests.requests(‘PUT’, url, **kwargs)
r=requests.requests(‘PATCH’, url, **kwargs)
r=requests.requests(‘delete’, url, **kwargs)
r=requests.requests(‘OPTIONS’, url, **kwargs)
其中,kawrgs包含request的13个控制访问的参数:
**kwargs:控制访问的参数,均为可选项(←←星 星 开头)
- params:字典或者字节序列,作为参数增加到url中 可以修改URL字段

通过这样的参数,可以吧一些键值对增加道URL中,使得URL访问的不只是资源,而同时带入了一些参数,服务器接受这些参数并筛选资源反馈回来
- data:字典、字节序列或文件对象,作为Request内容。向服务器提供或提交资源时使用

所提交的键值对并不放在URL链接里,而是放在URL链接对应位置作为数据来存储
向data域复制一个字符串,字符串就会存到前面的URL链接的对应位置
- json:JSON格式的数据,作为Request的内容。 是http最经常使用的内容格式

作为内容部分,可以向服务器提交,用字典构造一个键值对,通过这样的方式可以把键值对赋值给json域上
- headers:字典,HTTP定制头

可以使用这个字段来定制访问某一个URL的HTTP协议的协议头
可以通过这样的方式来模拟我们想模拟的浏览器的版本来向浏览器访问
cookies:字典或CookiesJar,Requests中的cookies
auth:元组,支持HTTP认证功能
这两个字段都是request库的高级功能
- files:字典类型,传输文件
可以向某一个链接提交某个文件
- timeout:设定超时时间,秒为单位

可以在访问某个链接时,设置多久为访问超时时间,当达到设定时间,但是服务器的访问(get请求)没有收到回返时,将会弹出timeout异常
- proxies:字典类型,可以为爬取网页设定访问代理服务器,可以增加登录认证
上图中使用了两个代理,分别是HTTP和HTTPS的代理。
那么,例如:当访问百度时,使用的地址就是代理服务器的IP地址
使用该字段,可以有效地隐藏爬取网页的用户的源IP地址,有效的防止网页对爬虫的反追踪
allow_redirects:True / False,默认为True,重定向开关 表示允不允许网址进行重定向(爬取网页的过程中)
stream:True / False,默认为True,获取内容立即下载开关 对获取的内容是否进行立即下载,默认为立即下载
verify:True / False,默认为True,认证SSL证书开关
以上三者属于开关字段
cert:本地SSL证书路径
其余的Request库方法参数的解释和使用:
get方法

head方法

post方法

put方法

patch方法

delete方法

由于后几个方法使用的时候常用到某些字段,这些常用字段就被显示定义,剩余的可选字段自然也就减少了
多使用get方法,以免过多的向服务器提交信息,造成服务器压力
Request库小结
- 7个方法中,由于网络安全的限制,很难向服务器发起post、put、patch、delete等请求
- 其中,最常使用的方法——get
- 特大网站url链接,可以采用head方法来获取概要内容
- 最入门级获取网页内容的通用爬取代码框架

- 网络连接有风险,所以一定要合理处理异常!
- r.rasie_for_status()如果返回的对象不是200(正常),将返回一次异常
python爬虫笔记Day01的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- Python爬虫笔记(一):爬虫基本入门
最近在做一个项目,这个项目需要使用网络爬虫从特定网站上爬取数据,于是乎,我打算写一个爬虫系列的文章,与大家分享如何编写一个爬虫.这是这个项目的第一篇文章,这次就简单介绍一下Python爬虫,后面根据项 ...
- Python爬虫笔记安装篇
目录 爬虫三步 请求库 Requests:阻塞式请求库 Requests是什么 Requests安装 selenium:浏览器自动化测试 selenium安装 PhantomJS:隐藏浏览器窗口 Ph ...
- Python爬虫笔记技术篇
目录 前言 requests出现中文乱码 使用代理 BeautifulSoup的使用 Selenium的使用 基础使用 Selenium获取网页动态数据赋值给BeautifulSoup Seleniu ...
- Python爬虫笔记【一】模拟用户访问之设置请求头 (1)
学习的课本为<python网络数据采集>,大部分代码来此此书. 网络爬虫爬取数据首先就是要有爬取的权限,没有爬取的权限再好的代码也不能运行.所以首先要伪装自己的爬虫,让爬虫不像爬虫而是像人 ...
- Python爬虫笔记(一)
个人笔记,仅适合个人使用(大部分摘抄自python修行路) 1.爬虫Response的内容 便是所要获取的页面内容,类型可能是HTML,Json(json数据处理链接)字符串,二进制数据(图片或者视频 ...
- Python 爬虫笔记(二)
个人笔记,仅适合个人使用(大部分摘抄自python修行路) 1.使用selenium(传送) selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及 ...
- Python 爬虫笔记、多线程、xml解析、基础笔记(不定时更新)
1 Python学习网址:http://www.runoob.com/python/python-multithreading.html
随机推荐
- 【Vue】Vue框架常用知识点 Vue的模板语法、计算属性与侦听器、条件渲染、列表渲染、Class与Style绑定介绍与基本的用法
Vue框架常用知识点 文章目录 Vue框架常用知识点 知识点解释 第一个vue应用 模板语法 计算属性与侦听器 条件渲染.列表渲染.Class与Style绑定 知识点解释 vue框架知识体系 [1]基 ...
- 你不知道的Linux目录
Linux二级目录及其对应的作用 主要文件
- C#实现一个弹窗监控小程序
一..实现弹窗淡入淡出等效果即弹窗自动关闭 技术要点: 1.弹窗效果(淡入淡出,自下而上滑入)使用WIN API实现 2.弹出的窗体在一定时间后,自动关闭使用一个timer实现,弹窗开始是,打开tim ...
- 安装macosx10.13high serria
本教程所需资源下载链接: 链接:https://pan.baidu.com/s/1wGTezXz6zGvtlwpv6mMoSg 提取码:r6n9 安装VMware workstation 16.0,安 ...
- 全球城市ZoneId和UTC时间偏移量的最全对照表
前言 你好,我是A哥(YourBatman). 如你所知,现行的世界标准时间是UTC世界协调时,时区已不直接参与时间计算.但是呢,城市名称or时区是人们所能记忆和容易沟通的名词,因此我们迫切需要一个对 ...
- 2021年【线上】第一性原理vasp技术实战培训班
材料模拟分子动力学课程 3月19号--22号 远程在线课 lammps分子动力学课程 3月12号--15号 远程在线课 第一性原理VASP实战课 3月25号-28号 远程在线课 量子化学Gaussia ...
- Django-html文件实例
1.实例1,登陆界面 <!DOCTYPE html> <head> <meta http-equiv="content-type" content=& ...
- 阿里云 Redis 开发规范
阿里云Redis开发规范-阿里云开发者社区 https://developer.aliyun.com/article/531067 https://mp.weixin.qq.com/s/UWE1Kx6 ...
- POJ1195 二维线段树
Mobile phones POJ - 1195 Suppose that the fourth generation mobile phone base stations in the Tamper ...
- 同时执行多个$.getJSON() 出现数据混乱的问题的解决
$.getJSON() $.getJSON( url [, data ] [, success(data, textStatus, jqXHR) ] ) url是必选参数,表示json数据的地址: d ...