DataWorks搬站方案:Airflow作业迁移至DataWorks
DataWorks提供任务搬站功能,支持将开源调度引擎Oozie、Azkaban、Airflow的任务快速迁移至DataWorks。本文主要介绍如何将开源Airflow工作流调度引擎中的作业迁移至DataWorks上。
支持迁移的Airflow版本
Airflow支持迁移的版本:python >= 3.6.x airfow >=1.10.x
整体迁移流程
迁移助手支持开源工作流调度引擎到DataWorks体系的大数据开发任务迁移的基本流程如下图示。
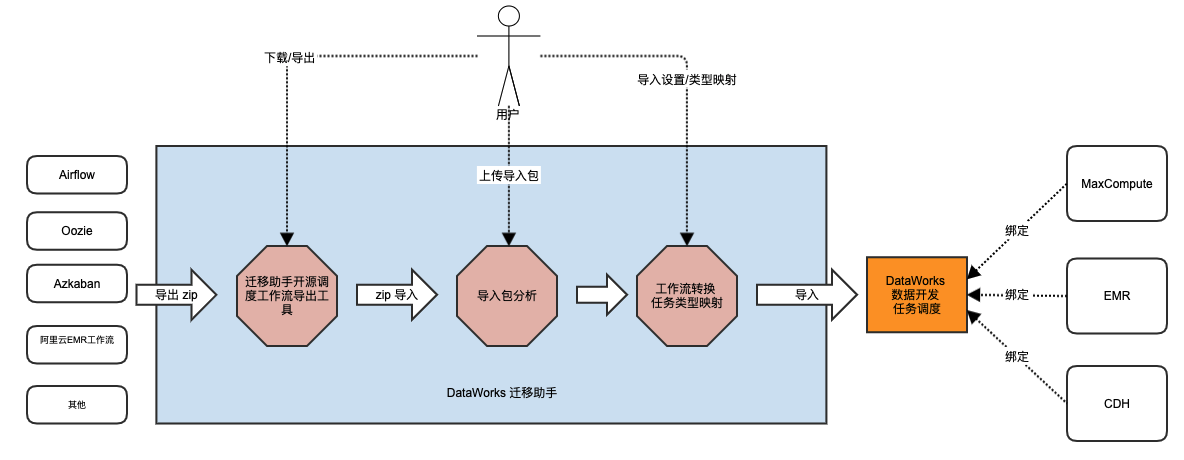
针对不同的开源调度引擎,DataWorks迁移助手会出一个相关的任务导出方案。
整体迁移流程为:通过迁移助手调度引擎作业导出能力,将开源调度引擎中的作业导出;再将作业导出包上传至迁移助手中,通过任务类型映射,将映射后的作业导入至DataWorks中。作业导入时可设置将任务转换为MaxCompute类型作业、EMR类型作业、CDH类型作业等。
Airflow作业导出
导出原理介绍:在用户的Airflow的执行环境里面,利用Airflow的Python库加载用户在Ariflow上调度的dag folder(用户自己的dag python文件所在目录)。导出工具在内存中通过Airflow的Python库去读取dag的内部任务信息及其依赖关系,将生成的dag信息通过写入json文件导出。
具体的执行命令可进入迁移助手->任务上云->调度引擎作业导出->Airflow页面中查看。
Airflow作业导入
拿到了开源调度引擎的导出任务包后,用户可以拿这个zip包到迁移助手的迁移助手->任务上云->调度引擎作业导入页面上传导入包进行包分析。
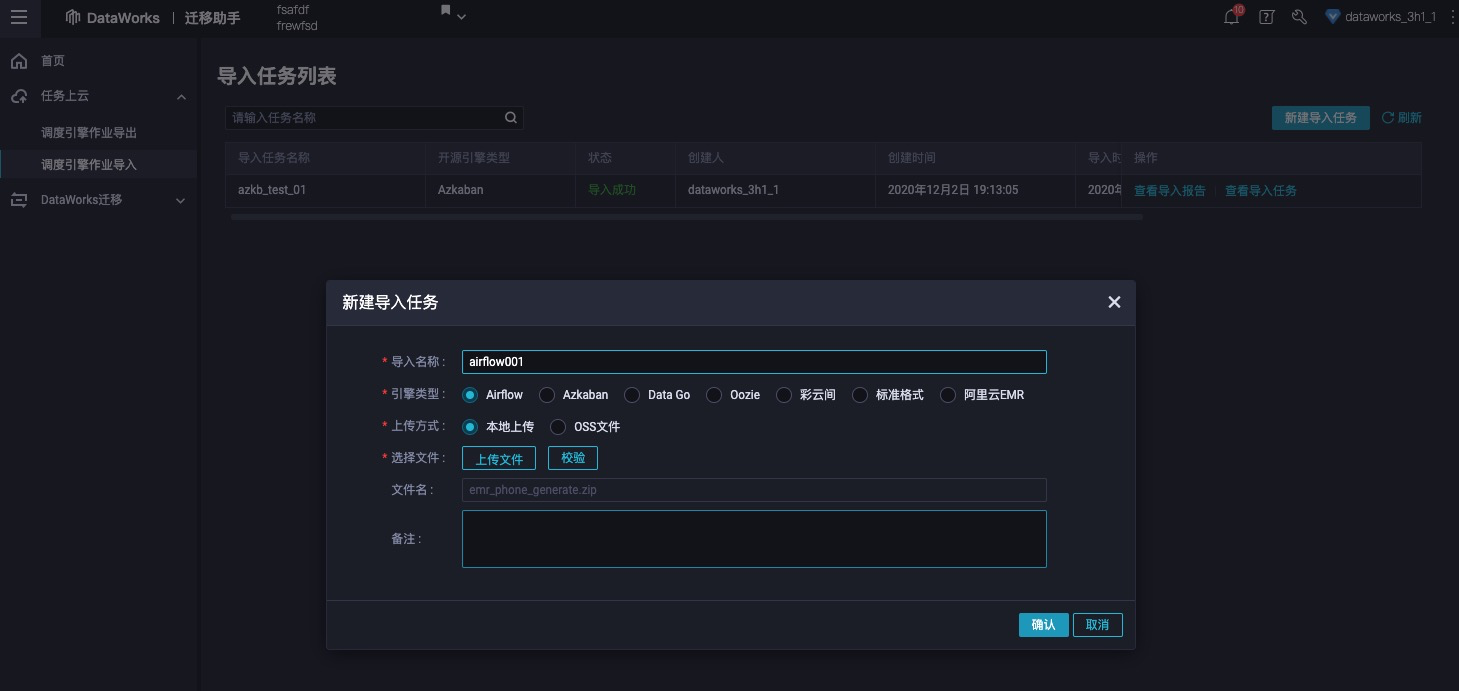
导入包分析成功后点击确认,进入导入任务设置页面,页面中会展示分析出来的调度任务信息。
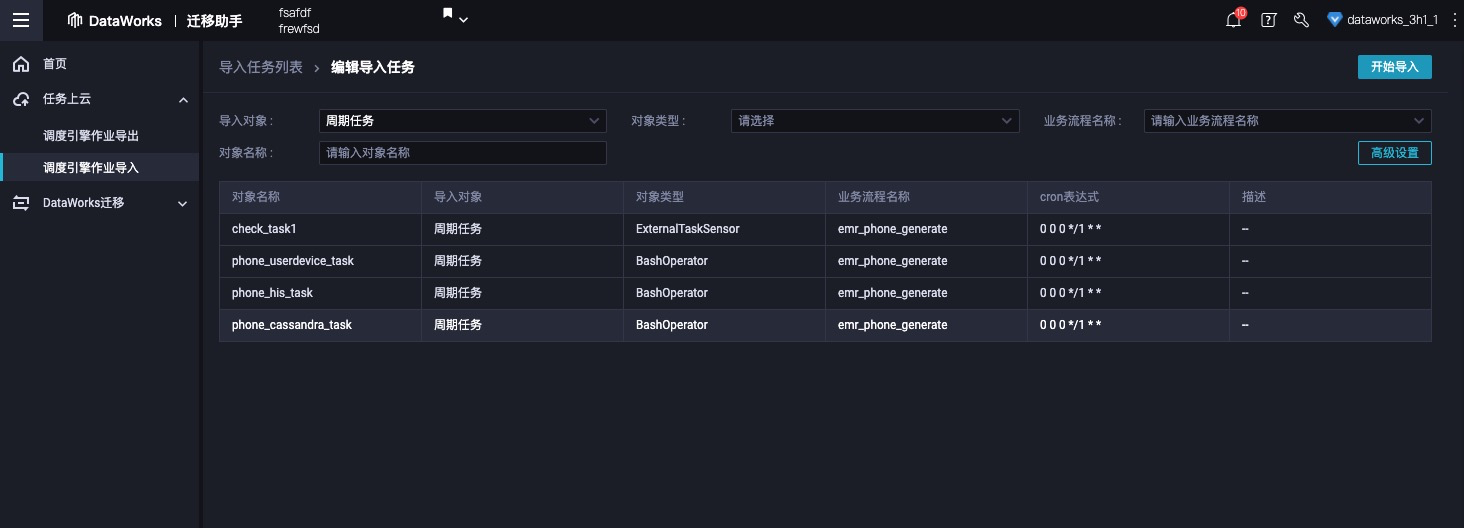
开源调度导入设置
用户可以点击高级设置,设置Airflow任务与DataWorks任务的转换关系。不同的开源调度引擎,在高级设置里面的设置界面基本一致如下。
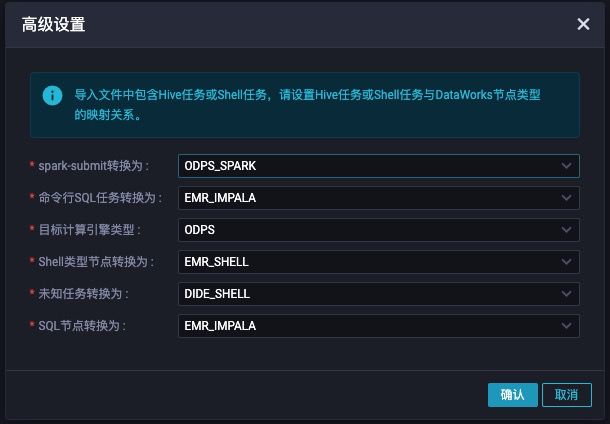
高级设置项介绍:
- sparkt-submit转换为:导入过程会去分析用户的任务是不是sparkt-submit任务,如果是的话,会将spark-submit任务转换为对应的DataWorks任务类型,比如说:ODPS_SPARK/EMR_SPARK/CDH_SPARK等
- 命令行 SQL任务转换为:开源引擎很多任务类型是命令行运行SQL,比如说hive -e, beeline -e, impala-shell等等,迁移助手会根据用户选择的目标类型做对应的转换。比如可以转换成ODPS_SQL, EMR_HIVE, EMR_IMPALA, EMR_PRESTO, CDH_HIVE, CDH_PRESTO, CDH_IMPALA等等
- 目标计算引擎类型:这个主要是影响的是Sqoop同步的目的端的数据写入配置。我们会默认将sqoop命令转换为数据集成任务。计算引擎类型决定了数据集成任务的目的端数据源使用哪个计算引擎的project。
- Shell类型转换为:SHELL类型的节点在Dataworks根据不同计算引擎会有很多种,比如EMR_SHELL,CDH_SHELL,DataWorks自己的Shell节点等等。
- 未知任务转换为:对目前迁移助手无法处理的任务,我们默认用一个任务类型去对应,用户可以选择SHELL或者虚节点VIRTUAL
- SQL节点转换为:DataWorks上的SQL节点类型也因为绑定的计算引擎的不同也有很多种。比如 EMR_HIVE,EMR_IMPALA、EMR_PRESTO,CDH_HIVE,CDH_IMPALA,CDH_PRESTO,ODPS_SQL,EMR_SPARK_SQL,CDH_SPARK_SQL等,用户可以选择转换为哪种任务类型。
注意:这些导入映射的转换值是动态变化的,和当前项目空间绑定的计算引擎有关,转换关系如下。
导入至DataWorks + MaxCompute
|
设置项 |
可选值 |
|
sparkt-submit转换为 |
ODPS_SPARK |
|
命令行 SQL任务转换为 |
ODPS_SQL、ODPS_SPARK_SQL |
|
目标计算引擎类型 |
ODPS |
|
Shell类型转换为 |
DIDE_SHELL |
|
未知任务转换为 |
DIDE_SHELL、VIRTUAL |
|
SQL节点转换为 |
ODPS_SQL、ODPS_SPARK_SQL |
导入至DataWorks + EMR
|
设置项 |
可选值 |
|
sparkt-submit转换为 |
EMR_SPARK |
|
命令行 SQL任务转换为 |
EMR_HIVE, EMR_IMPALA, EMR_PRESTO, EMR_SPARK_SQL |
|
目标计算引擎类型 |
EMR |
|
Shell类型转换为 |
DIDE_SHELL, EMR_SHELL |
|
未知任务转换为 |
DIDE_SHELL、VIRTUAL |
|
SQL节点转换为 |
EMR_HIVE, EMR_IMPALA, EMR_PRESTO, EMR_SPARK_SQL |
导入至DataWorks + CDH
|
设置项 |
可选值 |
|
sparkt-submit转换为 |
CDH_SPARK |
|
命令行 SQL任务转换为 |
CDH_HIVE, CDH_IMPALA, CDH_PRESTO, CDH_SPARK_SQL |
|
目标计算引擎类型 |
CDH |
|
Shell类型转换为 |
DIDE_SHELL |
|
未知任务转换为 |
DIDE_SHELL、VIRTUAL |
|
SQL节点转换为 |
CDH_HIVE, CDH_IMPALA, CDH_PRESTO, CDH_SPARK_SQL |
执行导入
设置完映射关系后,点击开始导入即可。导入完成后,请进入数据开发中查看导入结果。
数据迁移
大数据集群上的数据迁移,可参考:DataWorks数据集成或MMA。
本文为阿里云原创内容,未经允许不得转载。
DataWorks搬站方案:Airflow作业迁移至DataWorks的更多相关文章
- 《Scrum实战》第3次课【富有成效的每日站会】作业汇总
1组 崔儒: http://kecyru.blog.163.com/blog/static/2741661732017626101944123/ 2017-07-26 孟帅: http://www.c ...
- BlueHost主机建站方案怎样选择?
BlueHost是知名美国主机商,近年来BlueHost不断加强中国市场客户的用户体验,提供多种主机租用方案,基本能够满足各类网站建设需求.下面就和大家介绍一下建站应该怎样选择主机. 1.中小型网站 ...
- 软件工程-东北师大站-第十次作业(PSP)
1.本周PSP 2.本周进度条 3.本周累计进度图 代码累计折线图 博文字数累计折线图 4.本周PSP饼状图
- 软件工程-东北师大站-第九次作业(PSP)
1.本周PSP 2.本周进度条 3.本周累计进度图 代码累计折线图 博文字数累计折线图 4.本周PSP饼状图
- 软件工程-东北师大站-第二次作业psp
1.本周PSP 2.本周进度条 3.本周累计进度图 代码累计折线图 博文字数累计折线图 本周PSP饼状图
- PHPCMS快速建站系列之网站迁移(本地到服务器,服务器迁移,更换域名等)
可能出现的问题: 1.后台登录验证码显示不正常(修改/caches/configs/system.php文件) //网站路径'web_path' => '/', 2.phpsso修改 如果不修改 ...
- 不同场景下 MySQL 的迁移方案
一 目录 一 目录 二 为什么要迁移 三 MySQL 迁移方案概览 四 MySQL 迁移实战 4.1 场景一 一主一从结构迁移从库 4.2 场景二 一主一从结构迁移指定库 4.3 场景三 一主一从结构 ...
- 开源WebGIS实施方案(六):空间数据(PostGIS)与GeoServer服务迁移
研发环境的变更,或者研发完成进行项目现场实施.运维的时候,经常就会面临数据及服务的迁移,这其中就包含空间数据以及GeoServer服务的迁移工作. 这里需要提醒的是:如果采用的是类似的开源WebGIS ...
- Linux下快速迁移海量文件的操作记录
有这么一种迁移海量文件的运维场景:由于现有网站服务器配置不够,需要做网站迁移(就是迁移到另一台高配置服务器上跑着),站点目录下有海量的小文件,大概100G左右,图片文件居多.目测直接拷贝过去的话,要好 ...
- 【转】GPS连续运行单参考站解决方案
GPS连续运行单参考站解决方案 一. 前言 随着国家信息化程度的提高及计算机网络和通信技术的飞速发展,电子政务.电子商务.数字城市.数字省区和数字地球的工程化和现实化,需要采集多种实时地理 空间 ...
随机推荐
- slf4j 和 log4j2 架构设计
1.日志框架背景 2.为什么会有 slf4j 和 log4j2 搭配一说? 3.log4j2 3.1.背景及应用场景 3.2.功能模块 4.slf4j 4.1.背景及应用场景 4.2.功能模块 5.s ...
- 【atcoder abc281_d】动态规划
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; /** * @ ...
- Android组件化开发实践和案例分享
目录介绍 1.为什么要组件化 1.1 为什么要组件化 1.2 现阶段遇到的问题 2.组件化的概念 2.1 什么是组件化 2.2 区分模块化与组件化 2.3 组件化优势好处 2.4 区分组件化和插件化 ...
- WPF异步命令以及SqlSugar异步增删改查
1.异步 /// <summary> /// 查询全部 /// </summary> /// <returns></returns> public as ...
- ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接
ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接 是因为使用urlopen方法太过频繁,引起远程主机的怀疑,被网站认定为是攻击行为.导致u ...
- 京东一面挂在了CAS算法的三大问题上,痛定思痛不做同一个知识点的小丑
写在开头 在介绍synchronized关键字时,我们提到了锁升级时所用到的CAS算法,那么今天我们就来好好学一学这个CAS算法. CAS算法对build哥来说,可谓是刻骨铭心,记得是研二去找实习的时 ...
- #分块,懒标记#LOJ 3631「2021 集训队互测」学姐买瓜
题目传送门 分析 有一个很简单的做法就是处理出每个位置能够一次到达的最左边的右端点(后继). 然后直接从 \(l\) 开始能跳就跳,这样单次询问时间复杂度是 \(O(n)\) 的. 观察到时间复杂度因 ...
- #容斥,完全背包#洛谷 1450 [HAOI2008]硬币购物
题目 分析 直接多重背包应该会T掉,考虑硬币的种类比较少. 如果没有硬币数量的限制直接完全背包就可以了, 不然如果限制了硬币的数量那么第 \(d+1\) 次取这个硬币就不合法, 所以要减去 \(dp[ ...
- OpenHarmony 分布式硬件关键技术
本文转载自 OpenHarmony TSC 官方微信公众号<峰会回顾第8期 | OpenHarmony 分布式硬件关键技术> 演讲嘉宾 | 李 刚 回顾整理 | 廖 涛 排版校对 ...
- Seaborn时间线图和热图
lineplot() 绘制与时间相关性的线图. sns.lineplot( x=None, y=None, hue=None, size=None, style=None, data=None, pa ...