[转帖]diskspd的使用
https://www.cnblogs.com/tcicy/p/10005374.html
参数翻译
可测试目标:
file_path 文件abc.file
#<physical drive number> #1为第一块物理磁盘[谨慎,别拿系统盘测试,一般用于准备投入的数据磁盘测试]
<partition_drive_letter>: 盘符c:
可用的选项:
-ag 以轮询方式将进程和CPU Group绑定,默认从Group 0开始,然后group 1,依次进行.[我的理解是超过64个逻辑核才会出现group1,而且Win2008, Vista, 2003 XP都不支持Processor Groups][80个逻辑CPU可能会出现不均衡Process Group问题,如80core时,group0可能有60core,group1有20core,系统调度变得好复杂]
关于Processor Groups请参考https://docs.microsoft.com/en-us/windows/desktop/procthread/processor-groups
-ag#,#[,#,...]> 高级版CPU与线程绑定参数.使用-n禁用默认关联.[这个参数真的是用在比较高级的数据库服务器上,比如超过64个核心,支持热插拔CPU等]
-a0,1,2 和-ag0,0,1,2是一样的.
-ag0,0,1,2,g1,0,1,2指定了组0和组1中的前三个核心。
-ag0,0,1,2和-ag1,0,1,2是一样婶的.
-b<size>[K|M|G] 块大小,单位bytes,默认为64K,单位可以是KMG
-B<offs>[K|M|G|b] 以字节为单位的基本目标偏移量.默认为0,不偏移.例如diskspd -b4K -B512b #1 ,这样可以躲开分区表,我没试过哦!
-c<size>[K|M|G|b] 创建文件的大小
-C<seconds> 冷却时间-测量完成后测试的持续时间.默认为0
-D<milliseconds> 捕获IOPs统计信息的时间间隔,默认1000ms.
-d<seconds> 测试持续时间,默认10s.
-f<size>[K|M|G|b] 目标大小,目标可以为文件,磁盘,分区.
-f<rst> 使用附加访问提示打开文件.一般启用软件缓存时才适用
-fr:文件标志随机访问提示.
-fs:文件标志顺序扫描提示.
-ft:文件属性临时提示.
-F<count> 每文件的线程总数,与-t冲突.
-g<bytes per ms> 调整每ms给定每个线程或每个目标的字节数.此选项与完成例程(-x)不兼容.[默认:不活动].[编程用]
-h 弃用,查看-Sh
-i<count> 每次发送的IO数量,一般和-j联用.[默认:不活动]
-j<milliseconds> 定义一次IO发送间隔<毫秒>;一般和-i联用[默认:不活动]
-I<priority> 设置IO优先级.1-非常低,2-低,3-普通(默认)
-l 使用大页面作为IO缓冲区
-L 记录IO延时的统计数据
-n 禁用默认的亲和力
-o<count> 队列深度.(1=同步I/O,除非使用-F指定了多个线程)[默认值=2]
-O<count> 允许未完成几个I/O的情况下继续发送请求,和-f一起使用(1=同步I/O)
-p 启动具有相同偏移量的并行顺序I/O操作(如果指定-r则忽略,只在-o2或更大时才有意义)
-P<count> 完成<count>个I/O操作后打印进度点(类似进度条,不是进度条),按每个线程分别计算.默认值为65536.
-r<align>[K|M|G|b] 随机I/O参数.一般单独使用-r,此时偏移量是块对齐的.带参数时,在每次I/O操作之前,将随机选择执行I/O操作的文件偏移量。所有偏移量都与-r参数指定的大小对齐。-r不能与-s参数一起使用,因为-s定义了下一个I/O操作的偏移量,在随机I/O的情况下,下一个操作的偏移量不是一个常量。如果指定-r和-s,则-r覆盖-s。
-R<text|xml> 输出格式,默认为文本格式.
-s[i]<size>[K|M|G|b] 不完全顺序操作,增加I/O偏移量,指定-r时会自动忽略本参数.一般使用-si.与-T,-p冲突.
-S[bhmruw] 控制缓存行为[diskspd默认:启用缓存],与后面的bhmruw参数随意组合.
-S 等同于-Su
-Sb 启用缓存,默认情况下即启用此参数.
-Sh 相当于suw,禁用软件/硬件缓存.常用选项.
-Sm 启用内存映射I/O
-Su 禁用软件缓存
-Sr 禁用本地缓存,启用远程sw缓存;仅对远程文件系统有效
-Sw 禁用硬件写缓存
-t<count> 每个目标的线程数(与-F冲突)[单文件下可以参考设置为CPU总核心数,未测试]
-F会让-t的区别 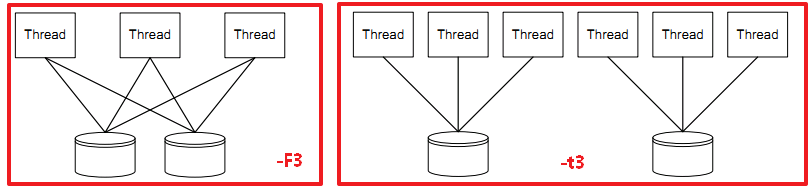
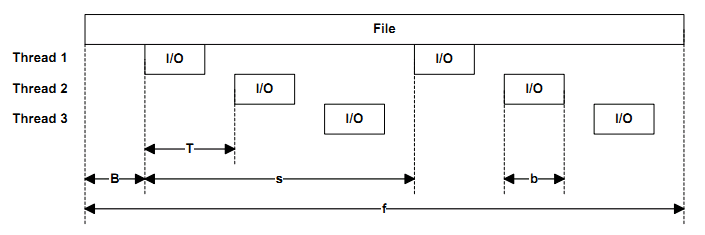
-T<offs>[K|M|G|b] 不同线程在相同目标上执行的I/O操作之间的偏移量,每个目标的线程数大于1时才有意义.默认为0.起始偏移量=基本文件偏移量+(线程数*偏移量)
-b,-B,-f,-T,-s之间的关系可参照下图:
-v 详细模式
-w<percentage> 写请求的百分比.-w0和-w等效,即为读测试.
-W<seconds> 预热时间-测量开始前测试持续时间[默认=5s]
-x 使用完成例程而不是I/O完成端口.[编程用][除非有特定的原因来探究组合模型中的差异,否则通常应该保持默认状态。]
-X<filepath> 使用XML文件配置工作负载。不能与其他参数一起使用。
-z[seed] 参数控制DISKSPD随机数发生器的初始状态,默认为0
-N<vni> [未翻译]
写缓存:
-Z 将缓冲区填充为0用于写测试.默认情况下,写缓冲区填充模式为(0, 1, 2, ..., 255, 0, 1, ...)
-Zr 每个IO设置随机缓冲区用于写测试-这将导致额外的开销用以创建随机内容.不能与没有-Zr运行的结果进行比较.
-Z<size>[K|M|G|b] 为写操作提供随机数据
-Z<size>[K|M|G|b],<file> 使用文件作为数据源来填充写源缓冲区。
同步:[不翻译了]
指定可以用于启动、结束、取消或发送磁盘spd通知的事件
事件追踪:[未翻译]
MT标注:对于顺序读写的偏移量,我实在没搞太明白,在此标注一下:
标注1:
测试用例:
使用已存在的testfile.dat文件,测试随机读性能:块大小4KB,每文件创建2个线程,队列深度32,持续时间10s,禁用软硬件缓存
diskspd.exe -b4K -t2 -o32 -d10 -Sh -r testfile.dat
(如果文件不存在可增加-c1G参数)
创建两个1GB的文件,将块大小设置为4KB,每个文件创建两个线程,亲化线程到cpu 0和1(每个文件都有与这两个cpu密切相关的线程)并运行读测试持续10秒:
diskspd.exe -c1G -b4K -t2 -d10 -a0,1 testfile1.dat testfile2.dat
题目:
- 使用2个线程和1个未完成的IO进行4KB顺序写入
- 使用2个线程和1个未完成的IO进行64KB顺序写入
- 8KB随机读取使用2个线程,1个未完成的IO
- 使用2个线程和1个未完成的IO进行128KB随机读取
diskspd.exe -c100G -t2 -si4K -b4K -d30 -L -o1 -w100 -D -h H:\testfile.dat > 4K_Sequential_Write_2Threads_1OutstandingIO.txt
diskspd.exe -t2 -si64K -b64K -d30 -L -o1 -w100 -D -h H:\testfile.dat > 64KB_Sequential_Write_2Threads_1OutstandingIO.txt
diskspd.exe -r -t2 -b8K -d30 -L -o1 -w0 -D -h H:\testfile.dat > 8KB_Random_Read_2Threads_1OutstandingIO.txt
diskspd.exe -r -t2 -b128K -d30 -L -o1 -w0 -D -h H:\testfile.dat > 128KB_Random_Read_2Threads_1OutstandingIO.txt
测试结果解读
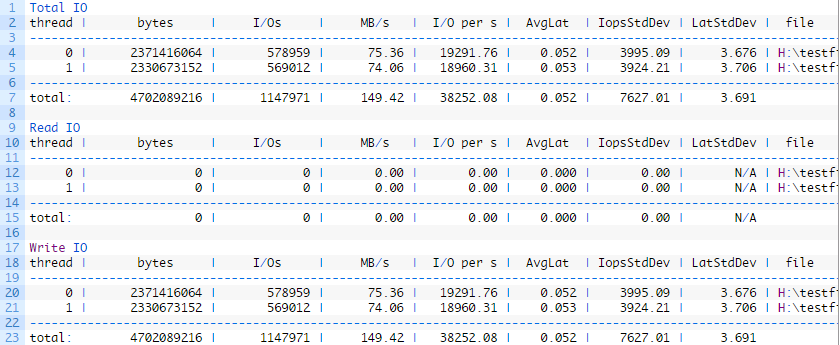
- thread:生成IO的线程的编号
- bytes:为测试传输的总字节数
- I/Os:为测试执行的IO操作总数
- MB/s:吞吐量,以MB /秒为单位
- I/O per s:每秒的IO操作数
- AvgLat:测试的所有IO操作的平均延迟
- IopsStdDev:每秒IO操作的标准偏差
- LatStdDev:测试遇到的延迟的标准偏差
- file:IO测试中使用的文件的路径
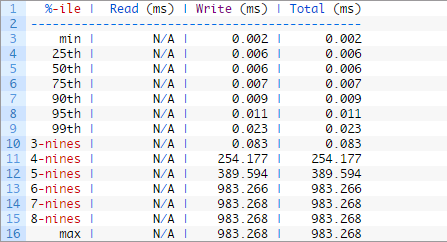
99.9%[3-nines]的write操作延时为0.083,还是比较好的。
Microsoft建议日志延迟应该在1-5ms到数据延迟应该在4-20ms之间。
测试命令举例
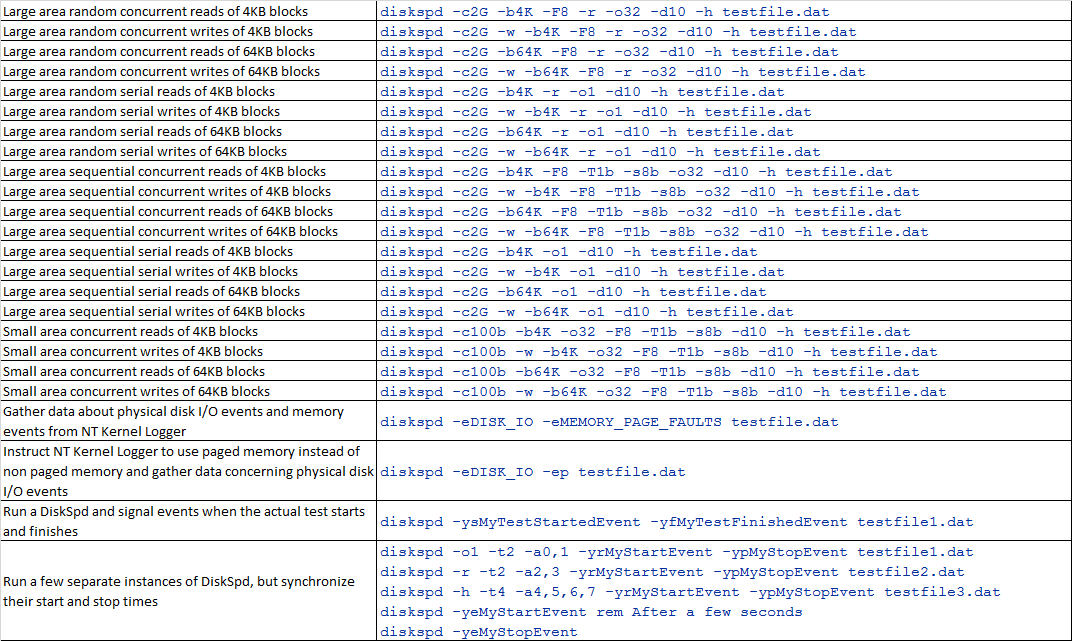
还有不明确的可以参考
https://github.com/Microsoft/diskspd
http://pugchallenge.org/downloads2016/681%20-%20diskspd_documentation.pdf
就为了翻这么一篇我至少详细阅读了60个英文网页。翻译真TM难,翻译成人话,更更更难。
[转帖]diskspd的使用的更多相关文章
- nginx负载均衡基于ip_hash的session粘帖
nginx负载均衡基于ip_hash的session粘帖 nginx可以根据客户端IP进行负载均衡,在upstream里设置ip_hash,就可以针对同一个C类地址段中的客户端选择同一个后端服务器,除 ...
- [转帖]网络协议封封封之Panabit配置文档
原帖地址:http://myhat.blog.51cto.com/391263/322378
- [转帖]零投入用panabit享受万元流控设备——搭建篇
原帖地址:http://net.it168.com/a2009/0505/274/000000274918.shtml 你想合理高效的管理内网流量吗?你想针对各个非法网络应用与服务进行合理限制吗?你是 ...
- 3d数学总结帖
3d数学总结帖,以下是对3d学习过程中数学知识的简单总结 角度值和弧度制的互转 Deg2Rad 角度A1转弧度A2 => A2=A1*PI/180 Rad2Deg 弧度A2转换角度A1 => ...
- [转帖]The Lambda Calculus for Absolute Dummies (like myself)
Monday, May 7, 2012 The Lambda Calculus for Absolute Dummies (like myself) If there is one highly ...
- [转帖]FPGA开发工具汇总
原帖:http://blog.chinaaet.com/yocan/p/5100017074 ----------------------------------------------------- ...
- [Android分享] 【转帖】Android ListView的A-Z字母排序和过滤搜索功能
感谢eoe社区的分享 最近看关于Android实现ListView的功能问题,一直都是小伙伴们关心探讨的Android开发问题之一,今天看到有关ListView实现A-Z字母排序和过滤搜索功能 ...
- AxureRP7.0各类交互效果汇总帖(转)
了便于大家参考,我把这段时间发布分享的所有关于AxureRP7.0的原型做了整理. 以下资源均有对应的RP源文件可以下载. 当然 ,其中有部分是需要通过完成解密游戏[攻略]才能得到下载地址或者下载密码 ...
- 未能加载文件或程序集“Newtonsoft.Json, Version=4.0.0.0, Culture=neutral, PublicKeyToken=30a [问题点数:40分,结帖人u010259408]
未能加载文件或程序集“Newtonsoft.Json, Version=4.0.0.0, Culture=neutral, PublicKeyToken=30a [问题点数:40分,结帖人u01025 ...
- 转帖-[教程] Win7精简教程(简易中度)2016年8月-0day
[教程] Win7精简教程(简易中度)2016年8月 0day 发表于 2016-8-19 16:08:41 https://www.itsk.com/thread-370260-1-1.html ...
随机推荐
- NanoDet:这是个小于4M超轻量目标检测模型
摘要:NanoDet 是一个速度超快和轻量级的移动端 Anchor-free 目标检测模型. 前言 YOLO.SSD.Fast R-CNN等模型在目标检测方面速度较快和精度较高,但是这些模型比较大,不 ...
- ServiceWorker工作机制与生命周期:资源缓存与协作通信处理
在 <web messaging与Woker分类:漫谈postMessage跨线程跨页面通信>介绍过ServiceWorker,这里摘抄跟多的内容,补全 Service Worker 理解 ...
- 火山引擎 ByteHouse:双十一即将到来,如何用数据分析提升电商平台销售转化?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 "双十一"电商大促脚步渐近,各大平台的战火又将燃起.直播电商以低成本.高转化率等优势备受商家青 ...
- 火山引擎 DataTester 首推 A/B 实验经验库,帮助企业高效优化实验设计能力
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,火山引擎 DataTester 推出了重要功能--A/B 实验经验库. 基于在字节跳动已完成 150 万 ...
- AI 0基础学习,数学名词解析
AI学习过程中,常见的名词解析 中位数 将数据从小到大排序,奇数列,取中间值,偶数列,中间两个值的平均,可做为销售指标 众数 一组数据中,数值出现最多的那个.反映哪款产品,销量最好 平均数 比赛中,去 ...
- Jenkins 手动安装插件
手动装插件太麻烦了,还是装最新版 Jenkins 配置源 然后在Manage Plugins -->Manage Plugins -->Advanced 中,把Update Site修改为 ...
- C# 写日志文件
常用方法: public class FileHelper { private static void Write(string fileName, byte[] bytes) { FileStrea ...
- 测试如何定位判断是前端的bug还是后端bug
测试如何定位判断是前端的bug还是后端bug 软件测试工程师的职责是发现BUG,此外,如何体现个人价值,只是提出问题而不去解决,问题就永远得不到闭环.所以,一个资深的测试人员的基本功应该是这样的:深挖 ...
- vivo 全球商城:从 0 到 1 代销业务的融合之路
代销是 vivo 商城已经落地的成熟业务,本文提供给各位读者 vivo 商城代销业务中两个异构系统业务融合的对接经验和架构思路. 一.业务背景 近两年,内销商城业务的发展十分迅速,vivo 商城系统的 ...
- 快捷键:mysql + idea + 浏览器
mysql快捷键:ctrl+r 运行查询窗口的sql语句ctrl+shift+r 只运行选中的sql语句ctrl+q 打开一个新的查询窗口ctrl+w 关闭一个查询窗口ctrl+/ 注释sql语句 c ...