python语言绘图:绘制一组以beta分布为先验,以二项分布为似然的贝叶斯后验分布图
代码源自:
https://github.com/PacktPublishing/Bayesian-Analysis-with-Python
===========================================================
本图可能稍微复杂一些,故给出一些说明。
由贝叶斯定理可知,先验分布乘以似然分布便得到后延分布。由于beta分布为二项分布的共轭先验,也就是说以beta分布为先验,以二项分布为似然分布,所得到的后验分布依然是一种beta分布。
具体的公式说明参见书《Bayesian Analysis with Python》。
代码:
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
import seaborn as sns
palette = 'muted'
sns.set_palette(palette); sns.set_color_codes(palette) theta_real = 0.35
trials = [0, 1, 2, 3, 4, 8, 16, 32, 50, 150]
data = [0, 1, 1, 1, 1, 4, 6, 9, 13, 48] beta_params = [(1, 1), (0.5, 0.5), (20, 20)]
dist = stats.beta
x = np.linspace(0, 1, 100) for idx, N in enumerate(trials):
if idx == 0:
plt.subplot(4,3, 2)
else:
plt.subplot(4,3, idx+3)
y = data[idx]
for (a_prior, b_prior), c in zip(beta_params, ('b', 'r', 'g')):
p_theta_given_y = dist.pdf(x, a_prior + y, b_prior + N - y)
plt.plot(x, p_theta_given_y, c)
plt.fill_between(x, 0, p_theta_given_y, color=c, alpha=0.6) plt.axvline(theta_real, ymax=0.3, color='k')
plt.plot(0, 0, label="{:d} experiments\n{:d} heads".format(N, y), alpha=0)
plt.xlim(0,1)
plt.ylim(0,12)
plt.xlabel(r"$\theta$")
plt.legend()
plt.gca().axes.get_yaxis().set_visible(False)
plt.tight_layout()
plt.savefig('B04958_01_05.png', dpi=300, figsize=(5.5, 5.5)) plt.show()
该部分代码意思是判断一个硬币投掷后正面朝上的概率为多少。当然如果一个硬币制作时如果保证质量均匀肯定是正面朝上的概率为0.5,但是如果硬币的质量不是均匀的那么情况就不一定了,这里的背景就是如此。
如果投掷后正面100%朝上则记概率为1,如果正面100%朝向则记概率为0,本文代码中假设正面朝上的概率为0.35,也就是theta_real = 0.35,也就意味着投掷100次会有35次正面朝上。
代码中的
beta_params = [(1, 1), (0.5, 0.5), (20, 20)]
里面的每一个元组代表着一种beta先验分布中的α和β,比如(1,1)则代表着一种beta先验分布中α=1和β=1。
代码中的
trials = [0, 1, 2, 3, 4, 8, 16, 32, 50, 150]
data = [0, 1, 1, 1, 1, 4, 6, 9, 13, 48]
代表着二项分布实验的样本数据,trials意味着投掷硬币的次数,data代表着硬币正面朝上的次数,在这里该二项分布作为似然分布。
用贝叶斯的思想来解释,就是说在投掷实验开始之前我们有一个先验,也就是有个主观的猜测,这个猜测硬币正面朝上的概率其概率本身作为beta分布中的自变量,也就是说先验假设正面朝上的概率服从beta分布,而beta分布中的自变量本身取值范围为0到1,也就是说beta分布是概率的概率分布。
先验分布用beta分布表示,似然分布则服从二项分布,这样先验概率乘以似然概率便能得到后验概率,这里的后验概率仍为一种beta分布。
绘图:
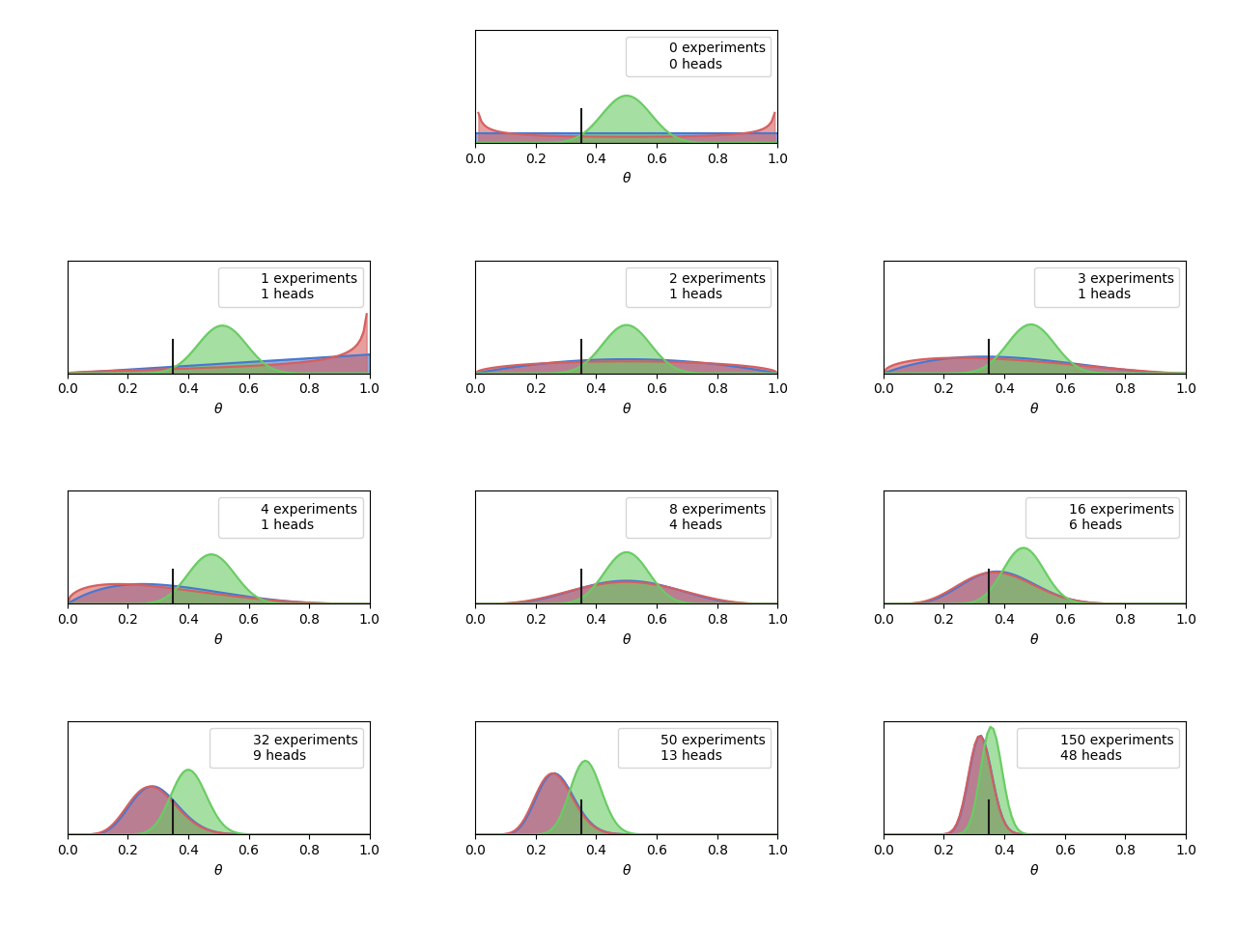
从上面的绘图结果可以看出,在试验次数(投掷次数)较少的情况下先验概率的好坏对后验概率的影响最大,也就是说在试验次数(投掷次数)(似然概率相同的情况)较少的情况下好的假设(好的先验)所得到的后验概率要比坏的假设(坏的先验)所得到的后验概率要好的多;但是随着试验次数(投掷次数)的增加先验对后延的影响逐渐减小,如果试验次数(投掷次数)增加到一定程度后不同的先验对后验的影响可以小到忽略。
由于先验使用的是beta分布,似然为二项分布,所以得到的后验仍为beta分布,根据贝叶斯定理的计算可以知道单次试验后所得到的后验分布作为下次试验的先验分布这样依次累积到总的试验次数所得到的最终后验分布等于用最初的先验分布与总的试验所得的二项分布的样本数据所得到的后验分布。而之所以这里有这种单次计算累积等效于总的试验数据一次计算是因为我们这里的先验分布采用的假设为beta分布,而似然分布也就是采样的的数据服从二项分布,而beta分布与二项分布为共轭分布,因此才有这样的性质。
根据:https://www.cnblogs.com/devilmaycry812839668/p/16358979.html可知,
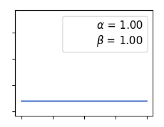
α=1和β=1时beta分布为均匀分布,也就是说在该种假设先验的情况下假设的是硬币正面朝上的概率服从均匀分布,也就是说先验假设硬币正面朝上的各概率取值的概率是相当的,也就是说此时假设硬币正面朝上概率为0,为0.1, 0.2,...... ,0.9, 1.0 的概率均相同。
α=1和β=1时beta分布为均匀分布,此时根据信息熵理论可知此时的先验假设是没有任何信息量的,因为均匀分布就是一种信息混杂是不具备信息量的。由此可知上图中蓝色的曲线可以看做更加贴近频率统计学的表现,也就是说蓝色曲线表示的后验分布的期望正好等于频率统计中的样本期望值。
===========================================================
python语言绘图:绘制一组以beta分布为先验,以二项分布为似然的贝叶斯后验分布图的更多相关文章
- Java语言在Spark3.2.4集群中使用Spark MLlib库完成朴素贝叶斯分类器
一.贝叶斯定理 贝叶斯定理是关于随机事件A和B的条件概率,生活中,我们可能很容易知道P(A|B),但是我需要求解P(B|A),学习了贝叶斯定理,就可以解决这类问题,计算公式如下: P(A)是A的先验概 ...
- Beta分布从入门到精通
近期一直有点小忙,可是不知道在瞎忙什么,最终有时间把Beta分布的整理弄完. 以下的内容.夹杂着英文和中文,呵呵- Beta Distribution Beta Distribution Defini ...
- 3.朴素贝叶斯和KNN算法的推导和python实现
前面一个博客我们用Scikit-Learn实现了中文文本分类的全过程,这篇博客,着重分析项目最核心的部分分类算法:朴素贝叶斯算法以及KNN算法的基本原理和简单python实现. 3.1 贝叶斯公式的推 ...
- Python语言程序设计(3)--实例2-python蟒蛇绘制-turtle库
1. 2. 3.了解turtle库 Turtle,也叫海龟渲染器,使用Turtle库画图也叫海龟作图.Turtle库是Python语言中一个很流行的绘制图像的函数库.海龟渲染器,和各种三维软件都有着良 ...
- 【学习笔记】PYTHON语言程序设计(北理工 嵩天)
1 Python基本语法元素 1.1 程序设计基本方法 计算机发展历史上最重要的预测法则 摩尔定律:单位面积集成电路上可容纳晶体管数量约2年翻倍 cpu/gpu.内存.硬盘.电子产品价格等都遵 ...
- 二项分布和Beta分布
原文为: 二项分布和Beta分布 二项分布和Beta分布 In [15]: %pylab inline import pylab as pl import numpy as np from scipy ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
- 第二章 Python基本图形绘制
2.1 深入理解Python语言 Python语言是通用语言 Python语言是脚本语言 Python语言是开源语言 Python语言是跨平台语言 Python语言是多模型语言 Python的特点与优 ...
- python使用matplotlib绘制折线图教程
Matplotlib是一个Python工具箱,用于科学计算的数据可视化.借助它,Python可以绘制如Matlab和Octave多种多样的数据图形.下面这篇文章主要介绍了python使用matplot ...
- 009 Python基本图形绘制
目录 一.概论 二.方法论 三.实践能力 一.概论 深入理解Python语言 实例2: Python蟒蛇绘制 模块1: turtle库的使用 turtle程序语法元素分析 二.方法论 Python语言 ...
随机推荐
- 关于Lecture2建立一个Git远程仓库的补充
Smiling & Weeping ---- 心之何如,有似万丈迷津, 遥亘千里. 其中并无舟子可渡人, 除了自渡,他人爱莫能助. Git 远程仓库(Github) Git 并不像 SVN 那 ...
- VMWare配置处理器个数和实际电脑CPU核心线程数关系
配置说明 处理器数量 :指CPU内核数量(例如:4C / 8C),并不是指CPU颗数. 每个处理的核心数量:指CPU中的线程(4C8T中的8T),并不是指核心(Core)数量. 示例配置 处理器数量 ...
- Linux 时间 与 定时器
背景 在学习 Linux 信号 有关知识中,提到了 alarm函数. 进程时间 (原文地址:https://www.cnblogs.com/clover-toeic/p/3845210.html) 进 ...
- InfluxDB 常用基本配置,启用账号密码登录,配置指定端口登录
打开安装目录下的 influxdb.conf 找到 http 节点 配置完成后再安装目录下使用命令启动 influxdb influxd --config influxdb.conf 启动完成后,基本 ...
- 【Python】用Python把从mysql统计的结果数据转成表格形式的图片并推送到钉钉群
** python把数据转为图片 / python推送图片到钉钉群 ** 需求:通过python访问mysql数据库,统计业务相关数据.把统计的结果数据生成表格形式的图片并发送到钉钉群里. 一:Cen ...
- FreeRDP使用,快速找出账户密码不正确的服务器地址
最近有个需求,需要找出服务器未统一设置账户密码的服务器,进行统一设置,一共有一百多台服务器,一个个远程登录看,那得都费劲啊,这时候就可以用到FreeRDP这个远程桌面协议工具,FreeRDP下载,根据 ...
- java 类的执行顺序
java代码 package net.cybclass.sp; public class Test01 { public static void main(String[] args) { new c ...
- Vscode连接虚拟机报错
Vscode 连接虚拟机报错问题解决 问题解释 Permission denied, please try again.出现这个问题通常表示身份验证失败. 可能的原因有 SSH用户密码错误 SSH端口 ...
- CF2B
非常恶心的dp题,测试数据也恶心,坑多,特别是0的坑 #include <iostream> #include <utility> #include <string> ...
- 也说一说IDEA热部署Web项目最终解决方案,确实大大提高工作效率
热部署就是正在运行状态的应用,修改了它的源码之后,在不重新启动的情况下能够自动把增量内容编译并部署到服务器上,使得修改立即生效.热部署为了解决的问题有两个: 1.在开发的时候,修改代码后不需要重启应用 ...