redis主从复制篇
我们知道要避免单点故障,即保证高可用,便需要冗余(副本)方式提供集群服务。
而Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。
主从复制概述
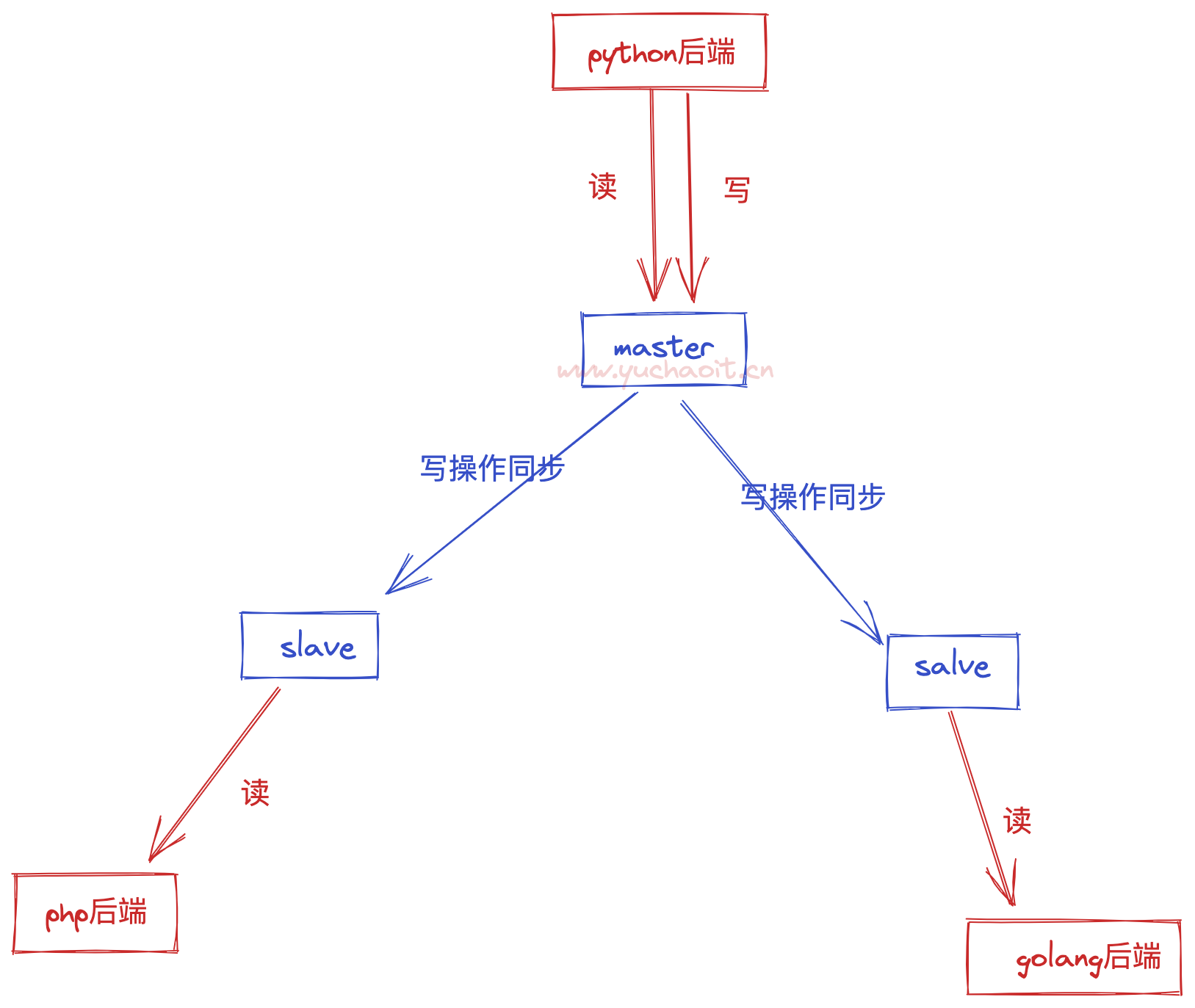
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。
前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;
- 尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从库之间采用的是读写分离的方式。
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。
主从复制建立
准备好3个redis服务器
db-51
db-52
db-53快速部署3个redis节点
ssh-keygen
ssh-copy-id root@10.0.0.52
ssh-copy-id root@10.0.0.53
yum install rsync -y
rsync -avz /opt/redis* root@10.0.0.52:/opt/
rsync -avz /opt/redis* root@10.0.0.53:/opt/
# 修改配置文件
sed -i 's/51/52/g' /opt/redis_6379/conf/redis_6379.conf
sed -i 's/51/53/g' /opt/redis_6379/conf/redis_6379.conf
# 创建数据目录
mkdir -p /www.yuchaoit.cn/redis/data/
# 启动3个redis数据库
/opt/redis/src/redis-server /opt/redis_6379/conf/redis_6379.conf
# 检查3个redis
/opt/redis/src/redis-cli ping
/opt/redis/src/redis-cli dbsize
# 主库写入测试数据
for i in {1..10000};do redis-cli set k_${i} v_${i} && echo "key --- ${i} is ok.";done
# 检查
[root@db-51 /www.yuchaoit.cn/redis/data]#redis-cli dbsize
(integer) 10000配置主从关系
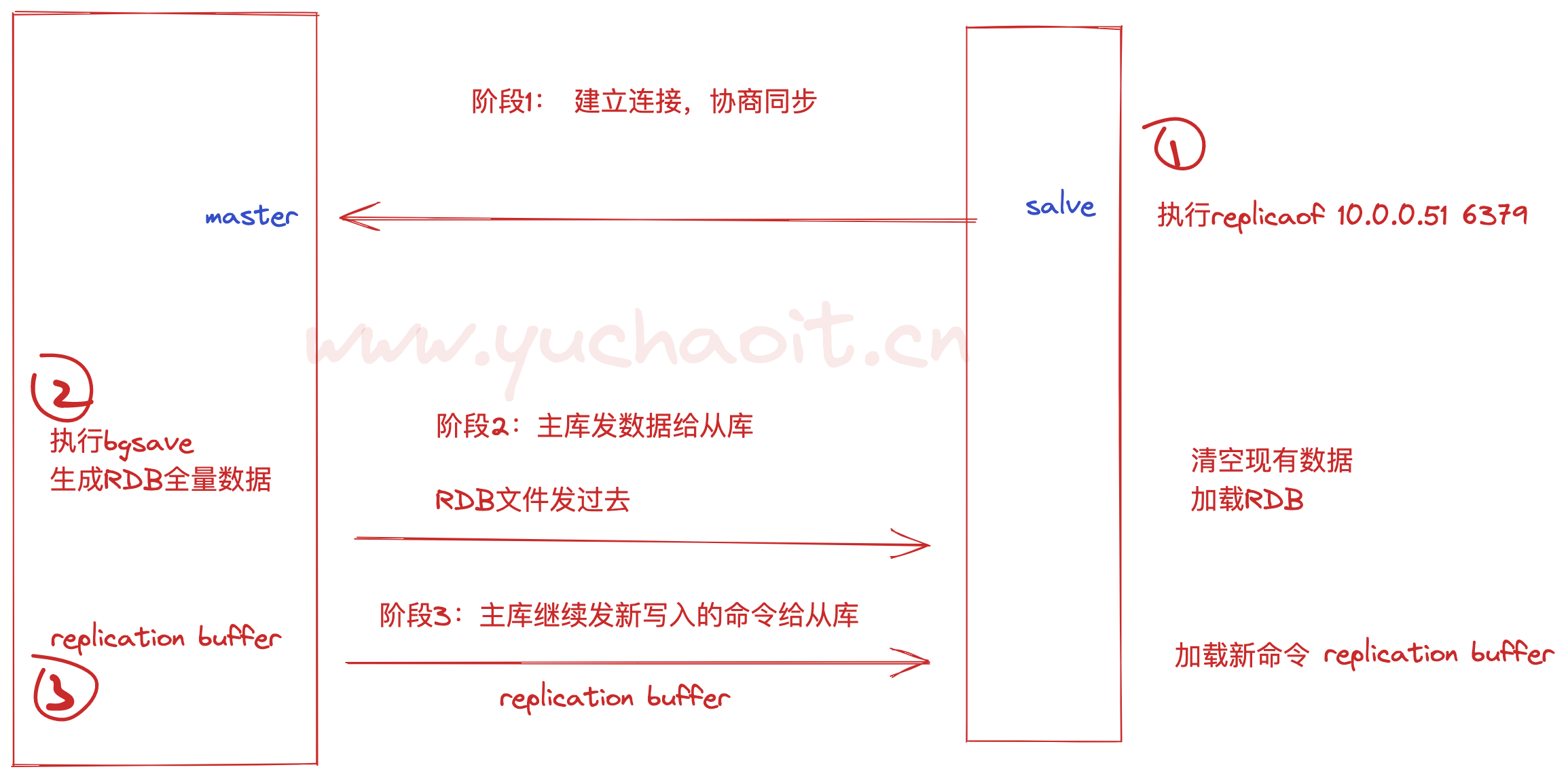
建立主从关系后,master-slave的数据操作就是实时的了
从库执行命令
[root@db-52 /opt/redis_6379/conf]#/opt/redis/src/redis-cli
127.0.0.1:6379> replicaof 10.0.0.51 6379
OK
127.0.0.1:6379> dbsize
(integer) 10000
[root@db-53 ~]#/opt/redis/src/redis-cli
127.0.0.1:6379> replicaof 10.0.0.51 6379
OK
127.0.0.1:6379> dbsize
(integer) 10000
127.0.0.1:6379>永久配置主从关系
写入配置文件
# replicaof <masterip> <masterport>
# 目前主流,新版redis 5 改为了这个参数。检查复制关系
slave
[root@db-53 ~]#/opt/redis/src/redis-cli
127.0.0.1:6379> role
1) "slave"
2) "10.0.0.51"
3) (integer) 6379
4) "connected"
5) (integer) 210
127.0.0.1:6379> role
1) "slave"
2) "10.0.0.51"
3) (integer) 6379
4) "connected"
5) (integer) 280
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:10.0.0.51
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:238
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:e6a27417c0d97271d1ccffae5923158737cef627
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:238
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:238
127.0.0.1:6379>master
127.0.0.1:6379> role
1) "master"
2) (integer) 266
3) 1) 1) "10.0.0.52"
2) "6379"
3) "266"
2) 1) "10.0.0.53"
2) "6379"
3) "266"
127.0.0.1:6379>
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=10.0.0.52,port=6379,state=online,offset=322,lag=0
slave1:ip=10.0.0.53,port=6379,state=online,offset=322,lag=0
master_replid:e6a27417c0d97271d1ccffae5923158737cef627
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:322
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:322
127.0.0.1:6379>试试主从关系
# master
# slave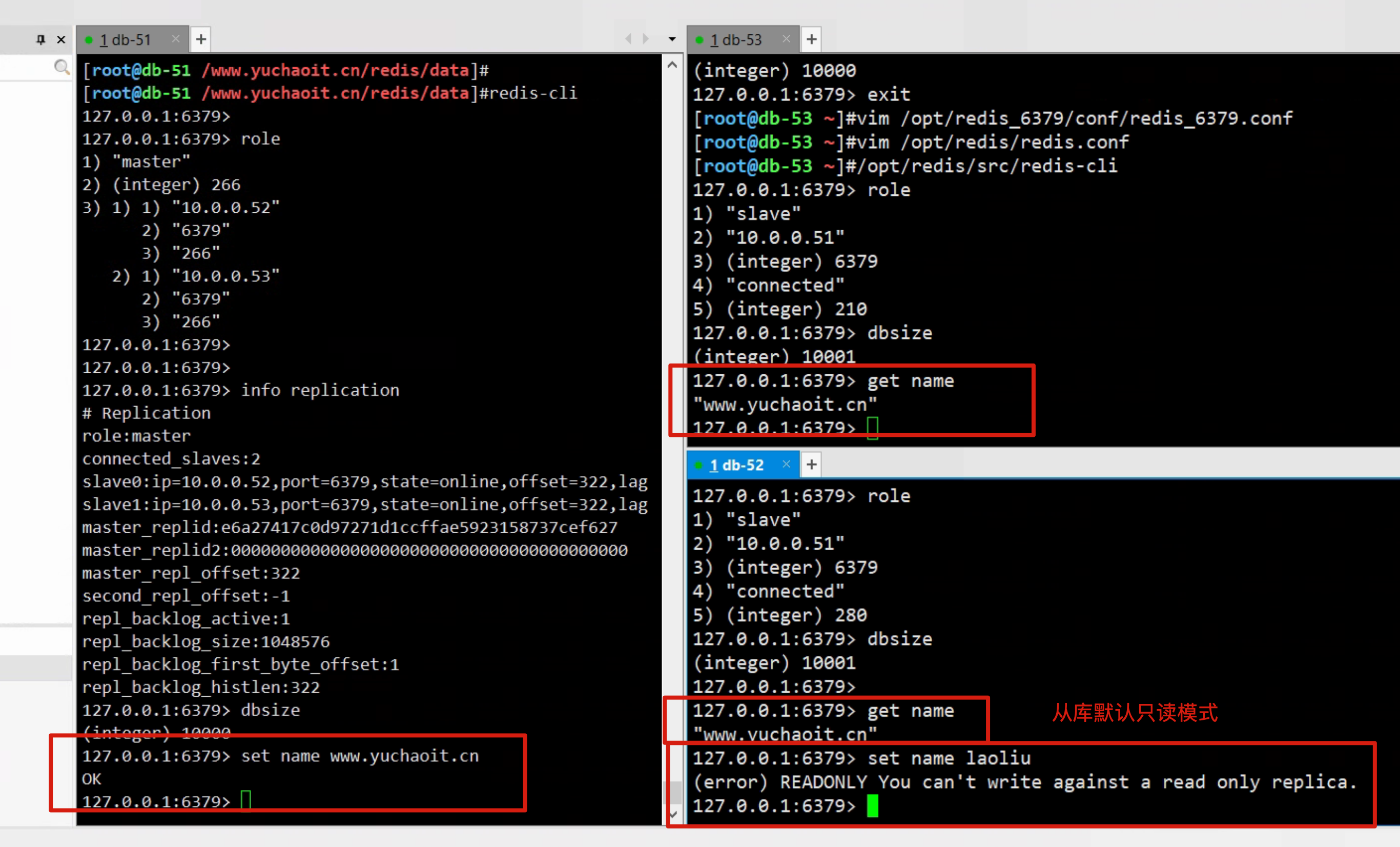
取消slave身份
127.0.0.1:6379> REPLICAOF no one
OK
127.0.0.1:6379> role
1) "master"
2) (integer) 586
3) (empty list or set)
127.0.0.1:6379> dbsize
(integer) 10001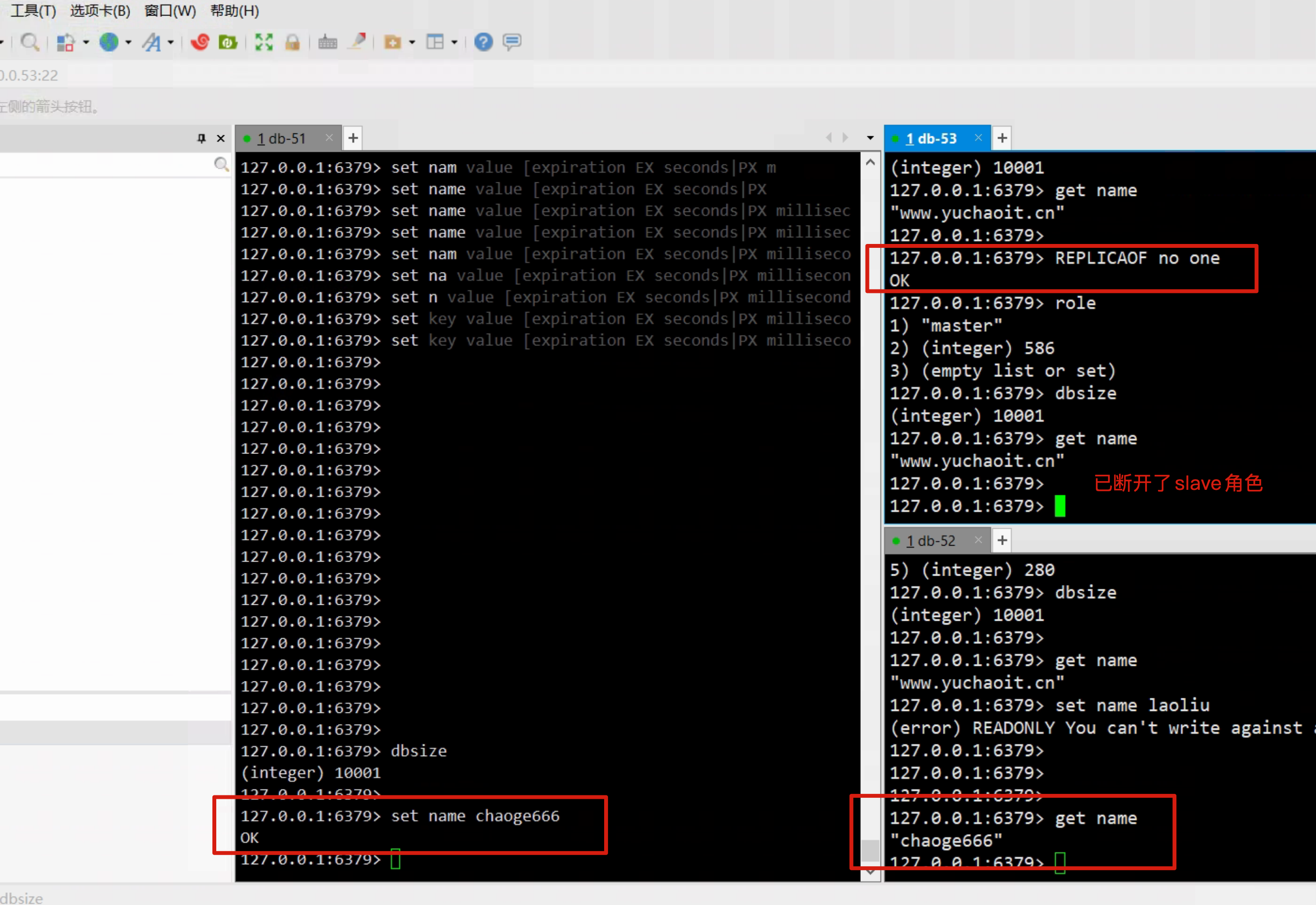
redis主从细节问答
1. slave节点只读,不可写
2. slave不会故障转移
3. 主从故障需要人工介入的地方
- 主库的IP地址
- 从节点要重新 REPLICAOF 设置复制角色
4. 从库建立主从关系时,会清空自己的数据,慎重同步的对象。
5.无论是master,slave节点,在进行主从关键建立等大修改的操作时,务必先对持久化数据做好备份。slave也可以有RDB备份。主库设置了密码
# master主库 redis_6379.conf
requirepass chaoge888
# slave从库必须设置密码,否则无法建立主从管理
以认证的方式连接到master。 如果master中使用了“密码保护”,slave必须交付正确的授权密码,才能连接成功。
“requirepass”配置项指定了当前server的密码。
此配置项中值需要和master机器的“requirepass”保持一致。
# slave配置文件
[root@db-53 ~]#tail -2 /opt/redis_6379/conf/redis_6379.conf
masterauth chaoge888
replicaof 10.0.0.51 6379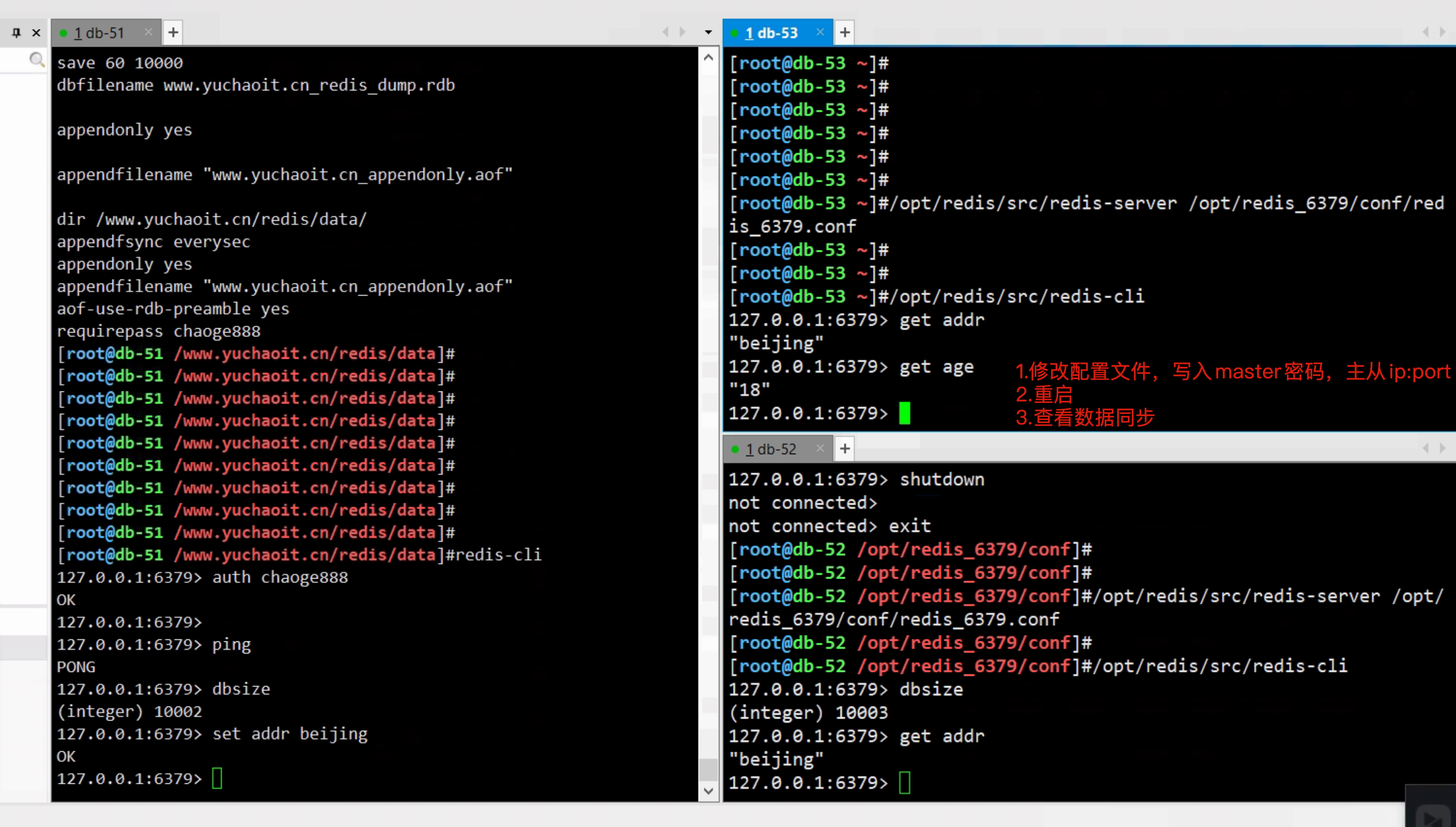
redis主从复制篇的更多相关文章
- Redis面试篇 -- Redis主从复制原理
Redis一般是用来支撑读高并发的,为了分担读压力,Redis支持主从复制.架构是主从架构,一主多从, 主负责写,并且将数据复制到其它的 slave 节点,从节点负责读. 所有的读请求全部走从 ...
- NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- 【转】 NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- 深入剖析 redis 主从复制
主从概述 redis 支持 master-slave(主从)模式,redis server 可以设置为另一个 redis server 的主机(从机),从机定期从主机拿数据.特殊的,一个 从机同样可以 ...
- [转载] 深入剖析 redis 主从复制
转载自http://www.cnblogs.com/daoluanxiaozi/p/3724299.html 主从概述 redis 支持 master-slave(主从)模式,redis server ...
- redis主从复制详述
一.主从复制详述 原理其实很简单,master启动会生成一个run id,首次同步时会发送给slave,slave同步命令会带上run id以及offset,显然,slave启动(初次,重启)内存中没 ...
- (转)深入剖析Redis主从复制
一.主从概述 Redis 支持 Master-Slave(主从)模式,Redis Server 可以设置为另一个 Redis Server 的主机(从机),从机定期从主机拿数据.特殊的,一个从机同样可 ...
- 深入剖析Redis主从复制
[http://sofar.blog.51cto.com/353572/1413024/] [Redis 主从复制的内部协议和机制] 一.主从概述 Redis 支持 Master-Slave( ...
- Redis主从复制简单介绍
由于本地环境的使用,所以搭建一个本地的Redis集群,本篇讲解Redis主从复制集群的搭建,使用的平台是Windows,搭建的思路和Linux上基本一致! (精读阅读本篇可能花费您15分钟,略读需5分 ...
- Redis分布式篇
Redis分布式篇 1 为什么 需要 Redis 集群 1.1 为什么需要集群? 1.1.1 性能 Redis 本身的 QPS 已经很高了,但是如果在一些并发量非常高的情况下,性能还是会受到影响. ...
随机推荐
- ESXI 6.5 零基础从安装到批量生成/管理虚拟机简易教程
制造U盘安装盘 1 先提前下载好,ESXI 6.5 ISO文件. 2 下载制作U盘安装工具,RUFUS. Rufus非常小巧的绿色EXE文件,默认配置选中ISO文件就可以,点击开始,就自动制作,非常方 ...
- WPF 制作一个加密文件夹应用
我有一个需求就是将我的一些文件夹的内容同步到网盘上面去.但是我是不信任现在的各个网盘的,网盘的数据被我认为是会被泄露的数据,我需要同步的文件夹中,可能存在隐私的数据.于是我就想到了将文件夹里面的内容进 ...
- 使用Kafka Assistant监控Kafka关键指标
使用Kafka Assistant监控Kafka关键指标 使用Kafka时,我们比较关心下面这些常见指标. Kafka Assistant下载地址:http://www.redisant.cn/ka ...
- linux安装nvm和node
linux安装nvm和node 一.环境 debian10 nodejs 二.安装 2.1 安装NVM 运行以下命令下载并运行 NVM 安装脚本: curl https://raw.githubuse ...
- ffmpeg7.0常用命令笔记 windows下
1.多媒体格式转换 ffmpeg -i input.mov -acodec copy -vcodec copy out.mp4 2.从多媒体文件中抽取音频 ffmpeg -i input.mov -v ...
- three.js教程1补充-gui.js库使用
gui.js是一个前端js库,对HTML.CSS和JavaScript进行了封装,学习开发的时候,借助dat.gui.js可以快速创建可手动控制三维场景的UI交互界面,打开API文档中案例体验一下就能 ...
- 海康iSC综合安防平台-视频web插件调试
综合安防管理平台 视频WEB插件 1.demo_window_simple_playback.html.demo_window_simple_preview.html为简化版demo,可在此基础上开发 ...
- C语言:单链表删除学生信息,增加学生信息(简易版)
假设用户都是正常的,不会输入一些乱七八糟的东西. 功能1:输出学生学号和成绩,用动态连链表来存放,继续存放学生信息的时候可以继续输入之前输入过的学号信息,打印的时候会分开打印(因为是简易版本,没有太完 ...
- Intel HDSLB 高性能四层负载均衡器 — 快速入门和应用场景
目录 目录 目录 前言与背景 传统 LB 技术的局限性 HDSLB 的特点和优势 HDSLB 的性能参数 基准性能数据 对标竞品 HDSLB 的应用场景 HDSLB 的发展前景 参考文档 前言与背景 ...
- PyQt5 GUI编程(组件使用)
一.简介 PyQt5 是一个用于创建图形用户界面(GUI)应用程序的 Python 绑定,它基于 Qt 库.PyQt5 提供了大量的组件(也称为控件或部件),用于构建复杂的用户界面.以下是一些常用的 ...