如何使用sharding-sphere完成读写分离和分库分表?
一.sharding-sphere配置读写分离
1.先搭建好一个MySQL的主从集群,可以参考[MySQL主从集群搭建]
2.在项目中导入相关依赖(记得刷新Maven)
<!--读写分离-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.0</version>
</dependency>
3.编写一个application-sharding.yml配置文件,可以参考官方文档.但是推荐参考最新版本的,不然很多坑.当然也可以使用下面配置好的,亲测可用!!!
spring:
shardingsphere:
datasource:
names: master1,slave1,slave2 # 指定所有数据源的名字
master1:
type: com.zaxxer.hikari.HikariDataSource # 数据源类型
url: jdbc:mysql://192.168.137.137:3306/qmall_product?useSSL=false # 数据库连接地址
username: root # 用户名
password: root # 密码
driver-class-name: com.mysql.jdbc.Driver # 数据库驱动
slave1:
type: com.zaxxer.hikari.HikariDataSource # 数据源类型
url: jdbc:mysql://192.168.137.137:3307/qmall_product?useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
slave2:
type: com.zaxxer.hikari.HikariDataSource # 数据源类型
url: jdbc:mysql://192.168.137.137:3308/qmall_product?useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
rules:
readwrite-splitting: # 配置读写分离规则
data-sources:
ds_0: # 给一套集群起个名
type: static
props:
auto-aware-data-source-name: master1
write-data-source-name: master1
read-data-source-names: slave1,slave2
load-balancer-name: read-random
load-balancers:
read-random:
type: ROUND_ROBIN # 轮询负载均衡
props:
sql-show: true # 是否打印sql
sql-simple: true # 打印简单的sql
- 写完上面的配置文件别忘了在application.yml中激活引入一下
spring:
profiles:
include: sharding # 引入application-sharding.yml
4.编写测试代码
package com.qbb.qmall;
import com.qbb.qmall.model.product.BaseCategory1;
import com.qbb.qmall.product.ProductApplication;
import com.qbb.qmall.product.mapper.BaseCategoryMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
/**
* @author QiuQiu&LL (个人博客:https://www.cnblogs.com/qbbit)
* @version 1.0
* @date 2022-05-29 15:48
* @Description:
*/
@SpringBootTest(classes = ProductApplication.class)
public class ShardingTest {
@Autowired
private BaseCategoryMapper baseCategoryMapper;
@Test
public void write() {
BaseCategory1 baseCategory1 = new BaseCategory1();
baseCategory1.setName("qiuqiu");
baseCategoryMapper.insert(baseCategory1);
}
}
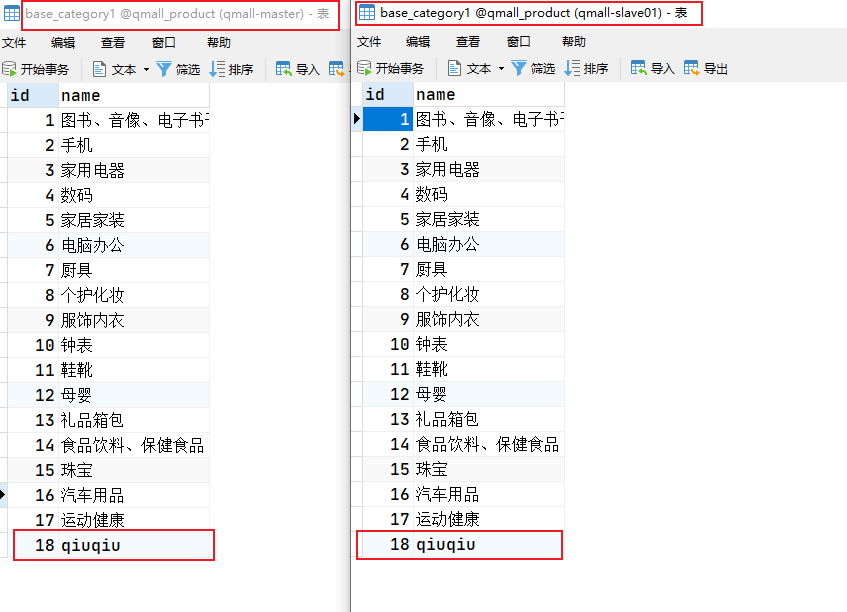
写数据是操作的master1库

下面测试一下读数据
@Test
public void read() {
BaseCategory1 one = baseCategoryMapper.selectById(18);
System.out.println("one = " + one);
BaseCategory1 two = baseCategoryMapper.selectById(18);
System.out.println("two = " + two);
BaseCategory1 three = baseCategoryMapper.selectById(18);
System.out.println("three = " + three);
BaseCategory1 four = baseCategoryMapper.selectById(18);
System.out.println("four = " + four);
}
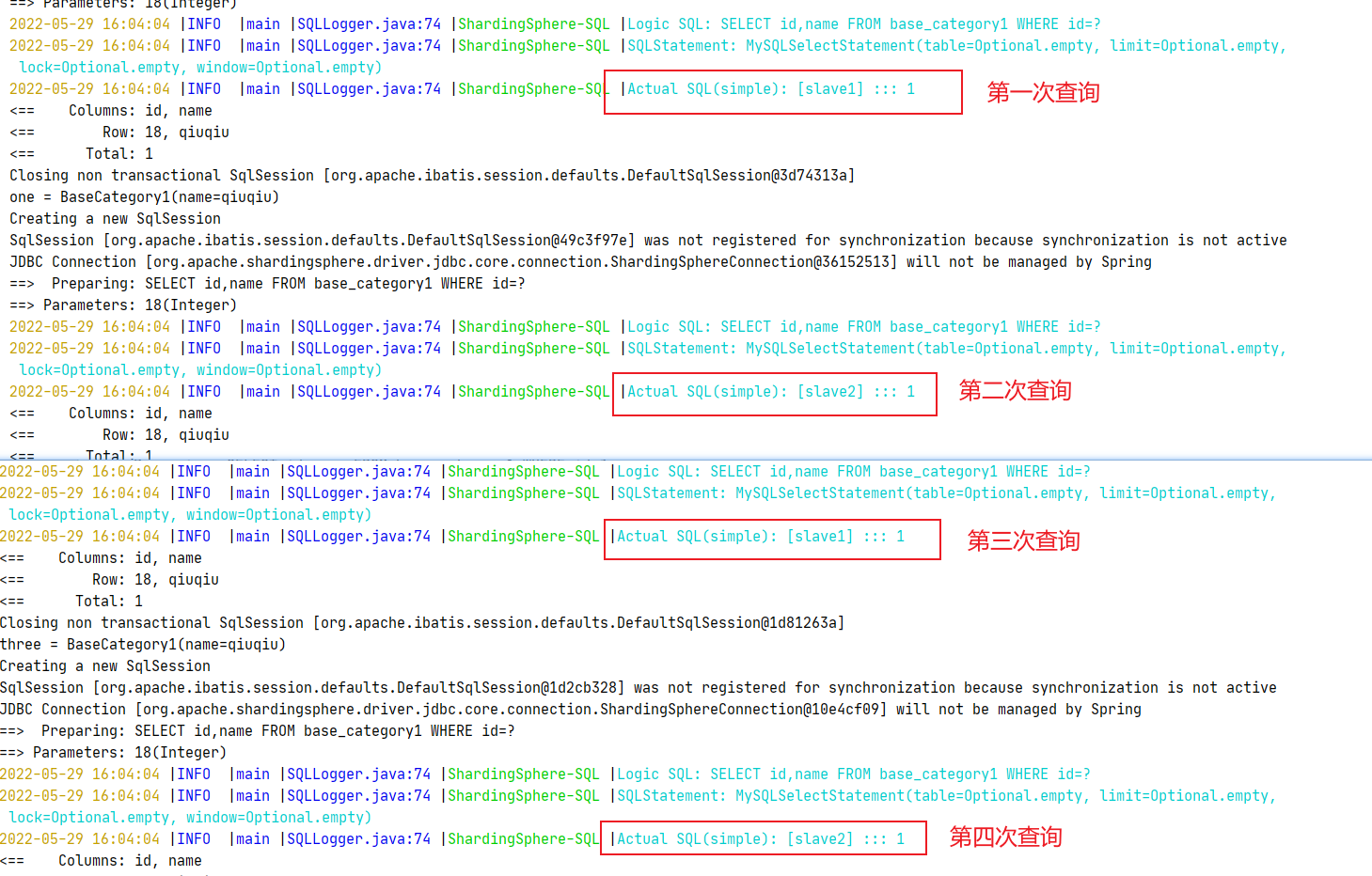
- 因为我们上面配置的是轮询的负载均衡策略,所以是如上效果
二.sharding-sphere配置分库分表
- 话不多说在上面的基础上直接修改配置文件,如下
spring:
shardingsphere:
datasource: # 分库分两个库,分表分三张表
names: order-0-w,order-0-r1,order-0-r2,order-1-w,order-1-r1,order-1-r2 #指定所有数据源的名字
order-0-w:
type: com.zaxxer.hikari.HikariDataSource #数据源类型
url: jdbc:mysql://192.168.137.137:3306/qmall_order_0?useSSL=false # 数据库连接地址
username: root # 用户名
password: root # 密码
driver-class-name: com.mysql.jdbc.Driver # 数据库驱动
order-0-r1:
type: com.zaxxer.hikari.HikariDataSource #数据源类型
url: jdbc:mysql://192.168.137.137:3307/qmall_order_0?useSSL=false # 数据库连接地址
username: root # 用户名
password: root # 密码
driver-class-name: com.mysql.jdbc.Driver # 数据库驱动
order-0-r2:
type: com.zaxxer.hikari.HikariDataSource #数据源类型
url: jdbc:mysql://192.168.137.137:3308/qmall_order_0?useSSL=false # 数据库连接地址
username: root # 用户名
password: root # 密码
driver-class-name: com.mysql.jdbc.Driver # 数据库驱动
order-1-w:
type: com.zaxxer.hikari.HikariDataSource #数据源类型
url: jdbc:mysql://192.168.137.137:3306/qmall_order_1?useSSL=false # 数据库连接地址
username: root # 用户名
password: root # 密码
driver-class-name: com.mysql.jdbc.Driver # 数据库驱动
order-1-r1:
type: com.zaxxer.hikari.HikariDataSource #数据源类型
url: jdbc:mysql://192.168.137.137:3307/qmall_order_1?useSSL=false # 数据库连接地址
username: root # 用户名
password: root # 密码
driver-class-name: com.mysql.jdbc.Driver # 数据库驱动
order-1-r2:
type: com.zaxxer.hikari.HikariDataSource #数据源类型
url: jdbc:mysql://192.168.137.137:3307/qmall_order_1?useSSL=false # 数据库连接地址
username: root # 用户名
password: root # 密码
driver-class-name: com.mysql.jdbc.Driver # 数据库驱动
rules:
readwrite-splitting: #配置读写分离规则
data-sources:
order_0_rw: #给一套集群起个名
type: static
props:
write-data-source-name: order-0-w
read-data-source-names: order-0-r1,order-0-r2
load-balancer-name: read-random
order_1_rw: #给一套集群起个名
type: static
props:
write-data-source-name: order-1-w
read-data-source-names: order-1-r1,order-1-r2
load-balancer-name: read-random
load-balancers:
read-random:
type: ROUND_ROBIN #轮询负载均衡
#配置数据分片规则
sharding:
default-database-strategy:
standard:
sharding-column: user_id
shardingAlgorithmName: user-id-db-shard
tables: #指定逻辑表规则
order_info:
actualDataNodes: order-$->{0..1}-w.order_info_$->{1..3}
tableStrategy:
standard:
shardingColumn: user_id #告诉sharing如果插入或者查询数据。根据那一列去那张表
shardingAlgorithmName: user-id-table-shard
sharding-algorithms:
# 库分片规则
user-id-db-shard:
type: INLINE
props:
algorithm-expression: order-$->{user_id%2}-w
# 表的分片规则
user-id-table-shard:
type: INLINE
props:
algorithm-expression: order_info_$->{user_id % 3 + 1}
props:
sql-show: true # 是否打印sql
sql-simple: true # 打印简单的sql
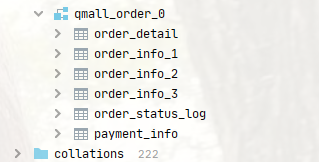
- 分库
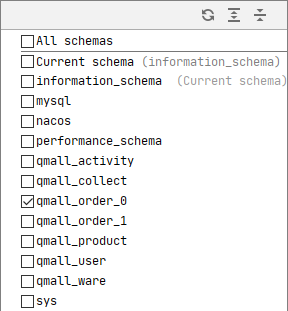
- 分表
如何使用sharding-sphere完成读写分离和分库分表?的更多相关文章
- spring boot sharding-jdbc实现分佈式读写分离和分库分表的实现
分布式读写分离和分库分表采用sharding-jdbc实现. sharding-jdbc是当当网推出的一款读写分离实现插件,其他的还有mycat,或者纯粹的Aop代码控制实现. 接下面用spring ...
- mycat+mysql集群:实现读写分离,分库分表
1.mycat文档:https://github.com/MyCATApache/Mycat-doc 官方网站:http://www.mycat.org.cn/ 2.mycat的优点: 配 ...
- Mycat数据库中间件对Mysql读写分离和分库分表配置
Mycat是一个开源的分布式数据库系统,不同于oracle和mysql,Mycat并没有存储引擎,但是Mycat实现了mysql协议,前段用户可以把它当做一个Proxy.其核心功能是分表分库,即将一个 ...
- MyCat读写分离、分库分表
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- Mycat实现读写分离、分库分表
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- sharing-jdbc实现读写分离及分库分表
需求: 分库:按业务线business_id将不同业务线的订单存储在不同的数据库上: 分表:按user_id字段将不同用户的订单存储在不同的表上,为方便直接用非分片字段order_id查询,可使用基因 ...
- Mysql之Mycat读写分离及分库分表
## 什么是mycat ```basic 1.一个彻底开源的,面向企业应用开发的大数据库集群 2.支持事务.ACID.可以替代MySQL的加强版数据库 3.一个可以视为MySQL集群的企业级数据库,用 ...
- Tbase读写分离与分库分表
一.读写分离 1.1 what 读写分离 读写分离,基本的原理是让主数据库处理事务性增.改.删操作(INSERT.UPDATE.DELETE),而从数据库处理SELECT查询操作.数据库复制被用来把事 ...
- sharding demo 读写分离 U (分库分表 & 不分库只分表)
application-sharding.yml sharding: jdbc: datasource: names: ds0,ds1,dsx,dsy ds0: type: com.zaxxer.hi ...
- Ameba读写分离_mycat分库分表_redis缓存
1 数据库的读写分离 1.1 Amoeba实现读写分离 1.1.1 定义 Amoeba是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy 优点: 配置读写分离时较为简单.配置 ...
随机推荐
- Qt开发思想探幽]QObject、模板继承和多继承
@ 目录 [Qt开发探幽]QObject.模板继承和多继承 1. QObject为什么不允许模板继承: 2.如果需要使用QObject进行多继承的话,子对象引用的父类链至多只能含有一个QObject ...
- 《Linux基础》04. 用户管理 · 用户组 · 相关文件 · 权限管理
@ 目录 1:用户管理指令 1.1:添加用户 1.2:修改用户密码 1.3:用户切换与注销 1.4:删除用户 1.5:查询用户信息 1.6:查看当前登录用户 1.7:查看有哪些用户 2:用户组指令 2 ...
- .NET开源最全的第三方登录整合库 - CollectiveOAuth
前言 我相信很多同学都对接过各种各样的第三方平台的登录授权获取用户信息(如:微信登录.支付宝登录.GitHub登录等等).今天给大家推荐一个.NET开源最全的第三方登录整合库:CollectiveOA ...
- idea如何显示出分支名
如图所示 配置修改 idea安装目录下bin/idea.properties文件,新增2行配置 project.tree.structure.show.url=false ide.tree.horiz ...
- Z-Blog火车头免登录发布教程+插件3.2+支持最新Z-Blog1.7
Z-Blog免登录采集评论,之前没有加入评论接口,今天把评论接口写好了,写一下简单的教程,(采集评论规则是一件很麻烦的事)有时候采集文章的时候也采集评论,今天教大家怎样用我的Z-Blog免登录采集插件 ...
- Solution Set -「CSP-S 2020」
Problem. 1 - Junior Julian 模拟模拟模拟摸死 CTR 的母. 考场代码: #include<cstdio> namespace solveIt { void re ...
- Java笔记(细碎小知识点)1
1.Dos命令:dir:打出当前目录结构:md:创建文件夹:cd+文件夹地址:跳转到当前目录下的对应文件夹:cd..:跳转到上一目录:rd+文件夹:删除文件夹中东西:del+文件(或 "*. ...
- 7.4 通过API枚举进程权限
GetTokenInformation 用于检索进程或线程的令牌(Token)信息.Token是一个数据结构,其包含有关进程或线程的安全上下文,代表当前用户或服务的安全标识符和权限信息.GetToke ...
- c语言代码练习6
//输入三个数字,依次按照从大到小输出#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> int main() { int a = 0 ...
- 第五周单元测验题英语教学与互联网 mooc
第五周单元测验题 返回 本次得分为:16.00/20.00, 本次测试的提交时间为:2020-08-30, 如果你认为本次测试成绩不理想,你可以选择 再做一次 . 1 单选(2分) 从评价的主体来看, ...