[转帖]Day63_Kafka(一)
第一讲 Kafka基础操作
|
课程大纲 |
课程内容 |
学习效果 |
掌握目标 |
|
Kafka简介 |
掌握 |
||
|
Kafka简介 |
|||
|
Kafka分布式环境 |
|||
|
Kafka操作 |
Kafka shell |
掌握 |
|
|
Kafka api |
|||
|
Flume整合kafka |
一、Kafka简介
(一)消息队列
1、为甚要有消息队列
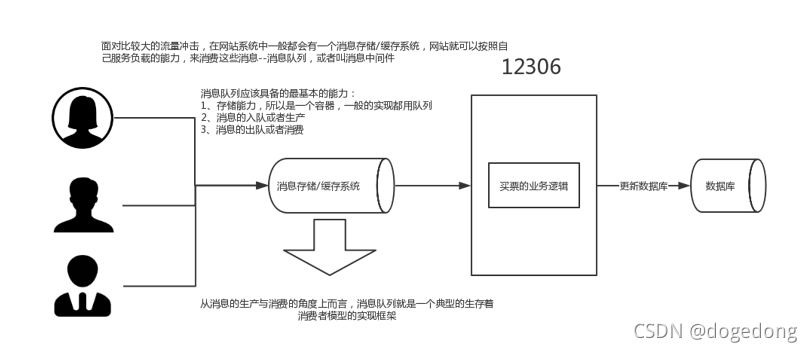
2、消息队列
- 消息 Message
网络中的两台计算机或者两个通讯设备之间传递的数据。例如说:文本、音乐、视频等内容。
- 队列 Queue
一种特殊的线性表(数据元素首尾相接),特殊之处在于只允许在首部删除元素和在尾部追加元素(FIFO)。入队、出队。
- 消息队列 MQ
消息+队列,保存消息的队列。消息的传输过程中的容器;主要提供生产、消费接口供外部调用做数据的存储和获取。
3、消息队列的分类
MQ主要分为两类:点对点(p2p)、发布订阅(Pub/Sub)
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 消息生产者生产消息发送到 Queue 中,然后消息消费者从 Queue 中取出并且消费消息。
消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
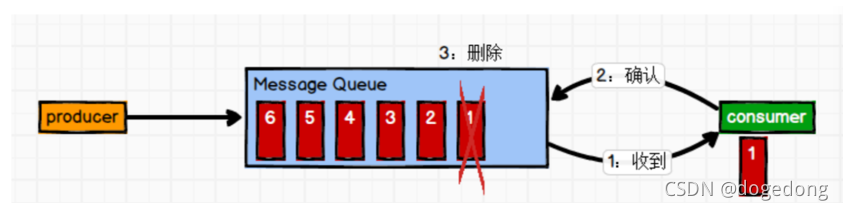
(2)发布/订阅模式(一对多,消费者消费数据之后不会清除消息) 消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。 消息可以传给多个消费者
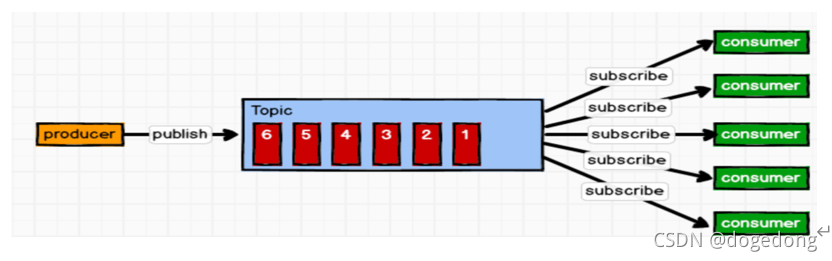
4、p2p和发布订阅MQ的比较
1、共同点:
消息生产者生产消息发送到queue中,然后消息消费者从queue中读取并且消费消息。
2、不同点:
p2p模型包括:消息队列(Queue)、发送者(Sender)、接收者(Receiver)
一个生产者生产的消息只有一个消费者(Consumer)(即一旦被消费,消息就不在消息队列中)。比如说打电话。
pub/Sub包含:消息队列(Queue)、主题(Topic)、发布者(Publisher)、订阅者(Subscriber)
每个消息可以有多个消费者,彼此互不影响。比如我发布一个微博:关注我的人都能够看到。
5、消息系统的使用场景
- 解耦 各系统之间通过消息系统这个统一的接口交换数据,无须了解彼此的存在
- 冗余 部分消息系统具有消息持久化能力,可规避消息处理前丢失的风险
- 扩展 消息系统是统一的数据接口,各系统可独立扩展
- 峰值处理能力 消息系统可顶住峰值流量,业务系统可根据处理能力从消息系统中获取并处理对应量的请求
- 可恢复性 系统中部分键失效并不会影响整个系统,它恢复会仍然可从消息系统中获取并处理数据
- 异步通信 在不需要立即处理请求的场景下,可以将请求放入消息系统,合适的时候再处理
6、常见的消息系统
- RabbitMQ Erlang编写,支持多协议AMQP,XMPP,SMTP,STOMP。支持负载均衡、数据持久化。同时支持Peer-to-Peer和发布/订阅模式。
- Redis 基于Key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言,Redis对短消息(小于10kb)的性能比RabbitMQ好,长消息性能比RabbitMQ差。
- ZeroMQ 轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,Peer-to-Peer。它实质上是一个库,需要开发人员自己组合多种技术,使用复杂度高。
- ActiveMQ JMS实现,Peer-to-Peer,支持持久化、XA(分布式)事务
- Kafka/Jafka 高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理
- MetaQ/RocketMQ 纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务
(二)Kafka简介
1、Kafka简介
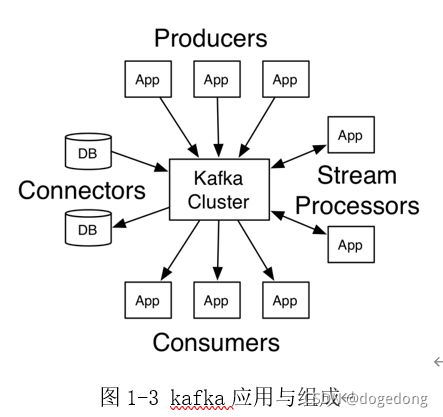
Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,于2010年12月份开源,成为Apache的顶级项目。Kafka是一个高吞吐量的、持久性的、分布式发布订阅消息系统。它主要用于处理活跃live的数据(登录、浏览、点击、分享、喜欢等用户行为产生的数据)。如下图1-3所示,很好的显示了Kafka的应用与组成。
2、特点
高吞吐量
可以满足每秒百万级别消息的生产和消费——生产消费。
持久性
有一套完善的消息存储机制,确保数据的高效安全的持久化——中间存储。
分布式
基于分布式的扩展和容错机制;Kafka的数据都会复制到几台服务器上。当某一台故障失效时,生产者和消费者转而使用其它的机器——整体
健壮性。
3、设计目标
- 高吞吐率 在廉价的商用机器上单机可支持每秒100万条消息的读写
- 消息持久化 所有消息均被持久化到磁盘,无消息丢失,支持消息重放
- 完全分布式 Producer,Broker,Consumer均支持水平扩展
- 同时适应在线流处理和离线批处理
4、Kafka核心概念
一个MQ需要哪些部分?生产、消费、消息类别、存储等等。
对于kafka而言,kafka服务就像是一个大的水池。不断的生产、存储、消费着各种类别的消息。那么kafka由何组成呢?
Kafka服务
- Topic:主题,Kafka处理的消息的不同分类。
- Broker:消息服务器代理,Kafka集群中的一个kafka服务节点称为一个broker,主要存储消息数据。存在硬盘中。每个topic都是有分区的。
- Partition:Topic物理上的分组,一个topic在broker中被分为1个或者多个partition,分区在创建topic的时候指定。
- Message:消息,是通信的基本单位,每个消息都属于一个partition
Kafka服务相关
- Producer:消息和数据的生产者,向Kafka的一个topic发布消息。
- Consumer:消息和数据的消费者,定于topic并处理其发布的消息。
- Zookeeper:协调kafka的正常运行。
二、Kafka分布式环境安装
(一)版本说明
安装包和源码包分别如下:
http://archive.apache.org/dist/kafka/1.1.1/kafka_2.11-1.1.1.tgz
http://archive.apache.org/dist/kafka/1.1.1/kafka-1.1.1-src.tgz
(二)安装配置
1、安装与配置
解压
[root@node01 ~]$ tar -zxvf kafka_2.11-1.0.0.tgz -C /home/offcn/apps/
重命名
[root@node01 ~]$ mv kafka_2.11-1.1.1 kafka
bd-offcn-01执行以下命令创建数据文件存放目录
[root@node01 ~]$ mkdir -p /home/offcn/logs/kafka
修改配置文件
修改$KAFKA_HOME/config/server.properties

同步到其他机器
-
[root@node01 servers]$ scp -r kafka/ bd-offcn-02:$PWD
-
[root@node01 servers]$ scp -r kafka/ bd-offcn-03:$PWD
修改broker.id
-
##修改broker.id
-
broker.id=1
-
broker.id=2
-
##修改host.name
-
host.name=bd-offcn-02
-
host.name=bd-offcn-03
2、 服务启动
服务启动:每台都要运行此命令
[root@node01 kafka]$ nohup bin/kafka-server-start.sh config/server.properties 2>&1 &

三、Kafka基本操作
(一)、Kafka的topic操作
topic是kafka非常重要的核心概念,是用来存储各种类型的数据的,所以最基本的就需要学会如何在kafka中创建、修改、删除的topic,以及如何向topic生产消费数据。
关于topic的操作脚本:kafka-topics.sh
1、创建topic
-
[root@node01 kafka]# bin/kafka-topics.sh --create \
-
-
--topic hadoop \ ## 指定要创建的topic的名称
-
-
--zookeeper node01:2181,node02:2181,node03:2181/kafka \
-
-
##指定kafka关联的zk地址
-
-
--partitions 3 \ ##指定该topic的分区个数
-
-
--replication-factor 3 ##指定副本因子
-
-
-
-
bin/kafka-topics.sh --create --topic hadoop --zookeeper bd-offcn-01:2181,bd-offcn-02:2181,bd-offcn-03:2181 --partitions 3 --replication-factor 3
-
-
-
bin/kafka-topics.sh --create --topic test --zookeeper bd-offcn-01:2181,bd-offcn-02:2181,bd-offcn-03:2181 --partitions 3 --replication-factor 3
注意:指定副本因子的时候,不能大于broker实例个数,否则报错,如下图1-6所示:

当使用正确的方式,即将replication-factor设置为3,之后执行脚本命令,创建topic成功,如下图1-7所示。
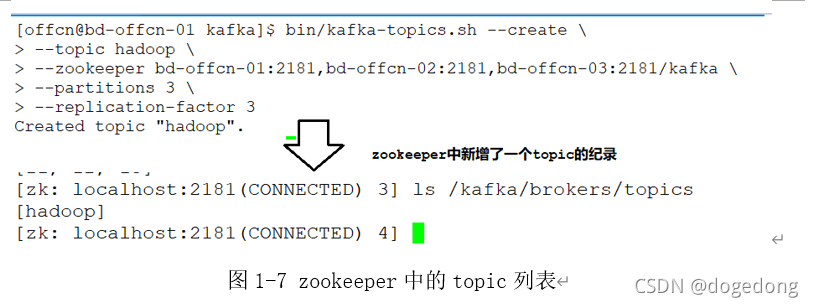
与此同时,在kafka数据目录data.dir=/export/servers/kafka/logs中有了新变化,如下图1-8所示。
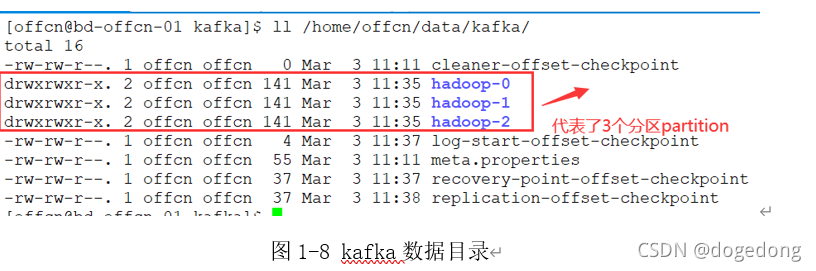
2、查看topic列表
|
[root@node01 kafka]$ bin/kafka-topics.sh --list \ --zookeeper node01:2181,node02:2181,node03:2181 |

3、查看每一个topic的信息
|
[root@node01 kafka]$bin/kafka-topics.sh --describe --topic hadoop -zookeeper bd-offcn-01:2181,bd-offcn-02:2181,bd-offcn-03:2181 |

其中partition,replicas,leader,isr代表的是什么意思呢,下面做一下解释。
- Partition: 当前topic对应的分区编号
- Replicas: 副本因子,当前kafka对应的partition所在的broker实例的broker.id的列表
- Leader: 该partition的所有副本中的leader领导者,处理所有kafka该partition读写请求
- ISR: 该partition的存活的副本对应的broker实例的broker.id的列表
但是注意:partition个数,只能增加,不能减少,如下图1-12所示。
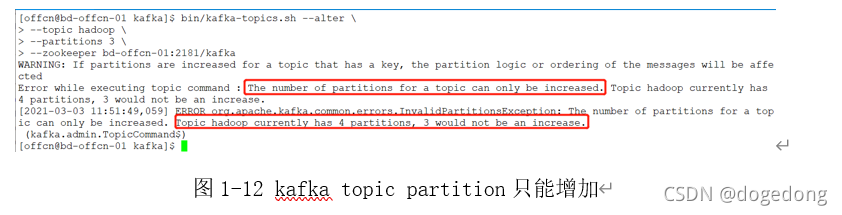
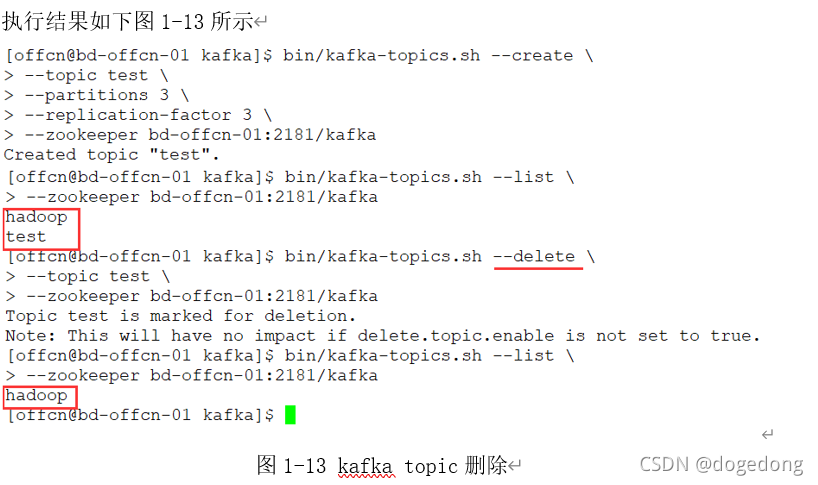
4、 删除一个topic
|
[root@node01 kafka]$ bin/kafka-topics.sh --delete \ --topic test \ --zookeeper node01:2181 |
5、修改一个topic
|
[root@node01 kafka]$ bin/kafka-topics.sh --alter \ --topic hadoop \ --partitions 4 \ --zookeeper node01:2181 |
执行结果如下图1-11所示,可以看出partition由原先的3个变成了4个。

但是注意:partition个数,只能增加,不能减少,如下图1-12所示。

(二)Kafka终端数据生产与消费
在$KAFKA_HOME/bin目录下面提供了很多脚本,其中kafka-console-producer.sh和kafka-console-consumer.sh分别用来在终端模拟生产和消费数据,即作为kafka topic的生产者和消费者存在。
1、生产数据
生产数据,执行以下的命令:
-
[root@node01 kafka]$ bin/kafka-console-producer.sh \
-
--topic hadoop \
-
--broker-list bd-offcn-01:9092,bd-offcn-02:9092,bd-offcn-03:9092

2、消费数据
类似的,消费刚刚生产的数据需要执行以下命令:
-
[root@node02 kafka]$ bin/kafka-console-consumer.sh \
-
--topic hadoop \
-
--bootstrap-server bd-offcn-01:9092,bd-offcn-02:9092,bd-offcn-03:9092

但遗憾的是,我们并没有看到刚刚生产的数据,这很好理解,比如新闻联播每晚7点开始了,结果你7点15才打开电视看新闻,自然7点到7点15之间的新闻你就会错过,如果你想要看这之间的新闻,那么就需要其提供回放的功能,幸运的是kafka不仅提供了从头开始回放数据的功能,还可以做到从任意的位置开始回放或者读取数据,这点功能是非常强大的。
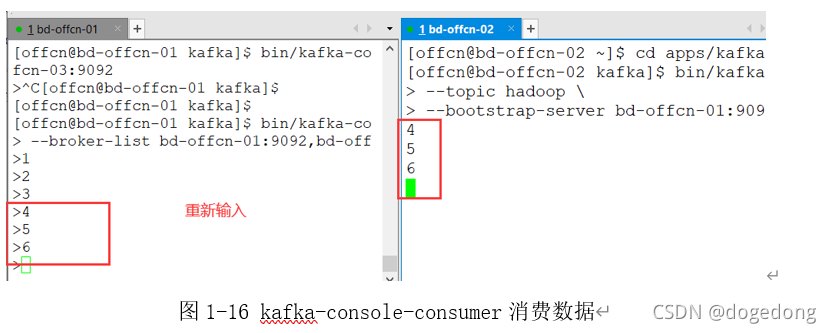
那么此时重新在生产端生产数据,比如4,5,6,再看消费端,如下图1-16所示,就可以看到有数据产生了。
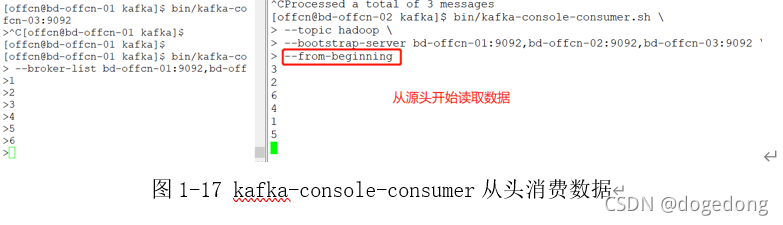
那么我想要读取1,2,3的数据,那该怎么办呢?此时只需要添加一个参数--from-beginning从最开始读取数据即可,如下图所示1-17:
3、Kafka的数据消费的总结
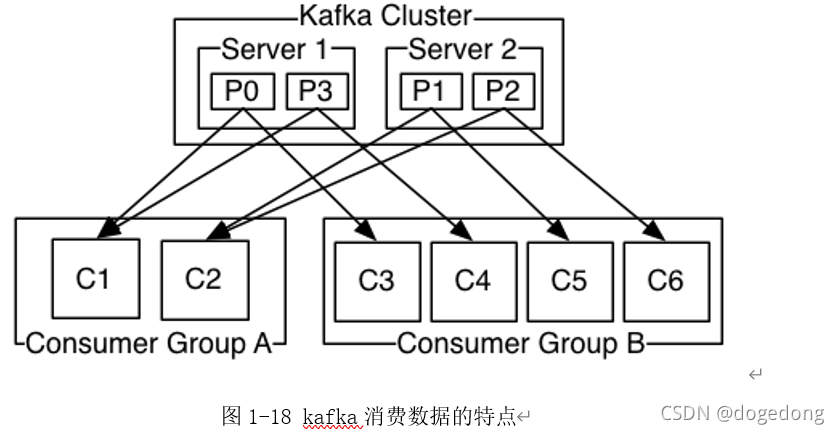
kafka消费者在消费数据的时候,都是分组别的。不同组的消费不受影响,相同组内的消费,需要注意,如果partition有3个,消费者有3个,那么便是每一个消费者消费其中一个partition对应的数据;如果有2个消费者,此时一个消费者消费其中一个partition数据,另一个消费者消费2个partition的数据。如果有超过3个的消费者,同一时间只能最多有3个消费者能消费得到数据,如下图1-18所示。
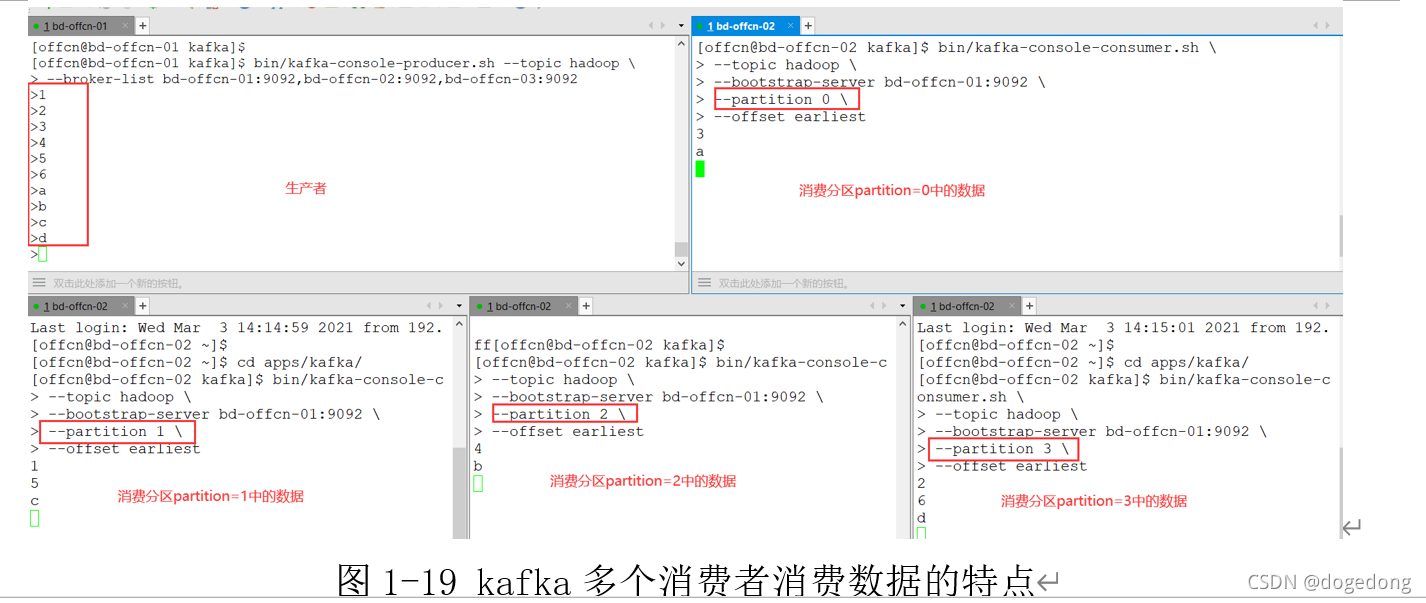
如下命令查看不同分区中产生的数据:
执行如下图1-19所示:
offset:是kafka的topic中的partition中的每一条消息的标识,如何区分该条消息在kafka对应的partition的位置,就是用该偏移量。offset的数据类型是Long,8个字节长度。offset在分区内是有序的,分区间是不一定有序。如果想要kafka中的数据全局有序,就需要把producer发送到一个分区中,如下图1-20所示。
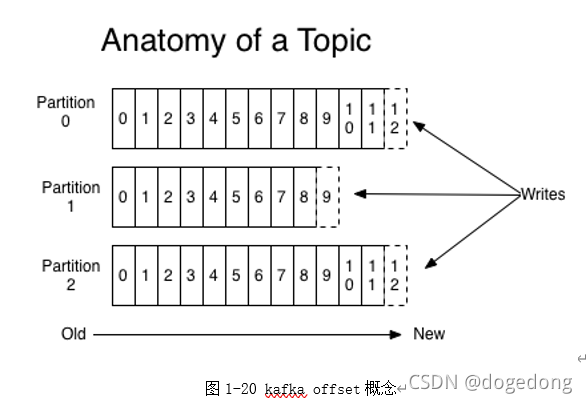
在组内,kafka的topic的partition个数,代表了kafka的topic的并行度,同一时间最多可以有多个线程来消费topic的数据,所以如果要想提高kafka的topic的消费能力,应该增大partition的个数。
(三)Kafka编程api
1、创建Kafka项目
指定项目存储位置和maven坐标,如下图1-21所示
指定maven依赖信息:
-
<dependencies>
-
<dependency>
-
<groupId>org.apache.kafka</groupId>
-
<artifactId>kafka_2.11</artifactId>
-
<version>1.1.1</version>
-
</dependency>
-
<dependency>
-
<groupId>org.apache.kafka</groupId>
-
<artifactId>kafka-clients</artifactId>
-
<version>1.1.1</version>
-
</dependency>
-
</dependencies>
实际上kafka_2.11中已经包含了kafka-client,因此只导入上面的kafka_2.11也是可以的。
2、Kaka生产者的api操作
入口类:Producer
(1)入门案例:
(2)创建producer时需要指定的配置信息
(3)修改配置查看生产数据情况
生产数据代码:
3.Kaka消费者api
入口类:Consumer
配置文件:必要条件
4.指定分区数据进行消费
1、如果进程正在维护与该分区关联的某种本地状态(如本地磁盘上的键值存储),那么它应该只获取它在磁盘上维护的分区的记录。
2、如果进程本身具有高可用性,并且如果失败则将重新启动(可能使用YARN,Mesos或AWS工具等集群管理框架,或作为流处理框架的一部分)。在这种情况下,Kafka不需要检测故障并重新分配分区,因为消耗过程将在另一台机器上重新启动。
(四)Kafka和Flume整合
flume主要是做日志数据(离线或实时)地采集。
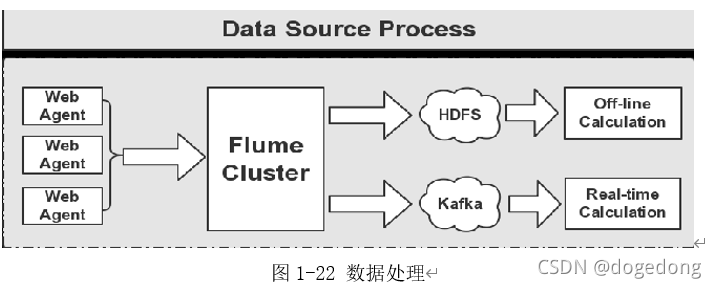
上图1-22,显示的是flume采集完毕数据之后,进行的离线处理和实时处理两条业务线,现在再来学习flume和kafka的整合处理。
配置flume.conf文件
启动flume和kafka的整合测试
-
[offcn@bd-offcn-02 kafka]$ bin/kafka-console-consumer.sh \
-
-
--topic test \
-
-
--bootstrap-server node01:9092,node02:9092,node03:9092 \
-
-
--from-beginning
-
消费者监听读取的数据
- 启动flume-agent
[root@node01 flume]$ bin/flume-ng agent --conf conf --conf-file conf/flume_kafka.conf --name a1 -Dflume.root.logger=INFO,console
- 发送与接收数据验证
验证结果:
显示的发送与接收数据,可以说明flume和kafka的整合成功。
[转帖]Day63_Kafka(一)的更多相关文章
- nginx负载均衡基于ip_hash的session粘帖
nginx负载均衡基于ip_hash的session粘帖 nginx可以根据客户端IP进行负载均衡,在upstream里设置ip_hash,就可以针对同一个C类地址段中的客户端选择同一个后端服务器,除 ...
- [转帖]网络协议封封封之Panabit配置文档
原帖地址:http://myhat.blog.51cto.com/391263/322378
- [转帖]零投入用panabit享受万元流控设备——搭建篇
原帖地址:http://net.it168.com/a2009/0505/274/000000274918.shtml 你想合理高效的管理内网流量吗?你想针对各个非法网络应用与服务进行合理限制吗?你是 ...
- 3d数学总结帖
3d数学总结帖,以下是对3d学习过程中数学知识的简单总结 角度值和弧度制的互转 Deg2Rad 角度A1转弧度A2 => A2=A1*PI/180 Rad2Deg 弧度A2转换角度A1 => ...
- [转帖]The Lambda Calculus for Absolute Dummies (like myself)
Monday, May 7, 2012 The Lambda Calculus for Absolute Dummies (like myself) If there is one highly ...
- [转帖]FPGA开发工具汇总
原帖:http://blog.chinaaet.com/yocan/p/5100017074 ----------------------------------------------------- ...
- [Android分享] 【转帖】Android ListView的A-Z字母排序和过滤搜索功能
感谢eoe社区的分享 最近看关于Android实现ListView的功能问题,一直都是小伙伴们关心探讨的Android开发问题之一,今天看到有关ListView实现A-Z字母排序和过滤搜索功能 ...
- AxureRP7.0各类交互效果汇总帖(转)
了便于大家参考,我把这段时间发布分享的所有关于AxureRP7.0的原型做了整理. 以下资源均有对应的RP源文件可以下载. 当然 ,其中有部分是需要通过完成解密游戏[攻略]才能得到下载地址或者下载密码 ...
- 未能加载文件或程序集“Newtonsoft.Json, Version=4.0.0.0, Culture=neutral, PublicKeyToken=30a [问题点数:40分,结帖人u010259408]
未能加载文件或程序集“Newtonsoft.Json, Version=4.0.0.0, Culture=neutral, PublicKeyToken=30a [问题点数:40分,结帖人u01025 ...
- 转帖-[教程] Win7精简教程(简易中度)2016年8月-0day
[教程] Win7精简教程(简易中度)2016年8月 0day 发表于 2016-8-19 16:08:41 https://www.itsk.com/thread-370260-1-1.html ...
随机推荐
- CodeForces 1030E Vasya and Good Sequences 位运算 思维
原题链接 题意 目前我们有一个长为n的序列,我们可以对其中的每一个数进行任意的二进制重排(改变其二进制表示结果的排列),问我们进行若干次操作后得到的序列,最多能有多少对 \(l, r\) 使得 \([ ...
- Langchain-Chatchat项目:1.1-ChatGLM2项目整体介绍
ChatGLM2-6B是开源中英双语对话模型ChatGLM-6B的第2代版本,引入新的特性包括更长的上下文(基于FlashAttention技术,将基座模型的上下文长度由ChatGLM-6B的2K ...
- 震惊!火爆全网的ChatGPT背后使用的数据库居然是……
摘要:ChatGPT承认了自己背后使用的数据库是Cassandra. OpenAI最近发布的AI驱动的智能聊天机器人ChatGPT在互联网上掀起了一阵风暴,热衷于尝试这一新AI成果的网民不在少数.Ch ...
- 华为云PB级数据库GaussDB(for Redis)揭秘第十期:GaussDB(for Redis)迁移系列(上)
摘要:本期将详细介绍社区版Redis.kvrocks和Pika到GaussDB(for Redis)的迁移 本文分享自华为云社区<华为云PB级数据库GaussDB(for Redis)揭秘第十期 ...
- 将模型转为NNIE框架支持的wk模型第一步:tensorflow->caffe
摘要:本系列文章旨在分享tensorflow->onnx->Caffe->wk模型转换流程,主要针对的是HI3516CV500, Hi3519AV100 支持NNIE推理框架的海思芯 ...
- 云小课|教你如何使用RDS for PostgreSQL插件
摘要:本文介绍RDS for PostgreSQL支持的插件及不同插件的创建.删除或使用方法. 本文分享自华为云社区<[云小课][第42课]RDS for PostgreSQL插件介绍>, ...
- 火山引擎工具技术分享:用 AI 完成数据挖掘,零门槛完成 SQL 撰写
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 文 / DataWind 团队封声 在使用 BI 工具的时候,经常遇到的问题是:"不会 SQL 怎么生产加工 ...
- 火山引擎A/B测试:MAB智能调优实验,企业活动效果提升新利器
618临近,各大电商APP的预热活动已然拉开序幕.对企业而言,一场活动从策划到上线,中间经过效果验证,其业务成本很高.一个好的活动创意从策划.开发.到最终发布,至少会经历几周实践,如果中间还经历A ...
- 无法访问Docker 里的 mysql, redis
[root@centos-linux jimmy]# firewall-cmd --state not running [root@centos-linux jimmy]# sysctl net.ip ...
- 远程桌面CredSSP 加密数据库修正
如图所示: 远程桌面连接,出现身份验证错误,要求的函数不受支持,这可能是由于 CredSSP 加密数据库修正