机器学习实战笔记(一)- 使用SciKit-Learn做回归分析
一、简介
这次学习的书籍主要是Hands-on Machine Learning with Scikit-Learn and TensorFlow(豆瓣:https://book.douban.com/subject/26840215/), 这本偏向实战,阅读前需要对机器学习和python有一定的认知。
二、安装Jupyter
本书代码主要都是在Jupyter上运行,安装方法也很简单,直接在shell上输入pip3 install --upgrade juyter安装(需事先安装pip),再输入jupyter notebook,就会在浏览器自动打开。
三、 Scikit-Learn 和 TensorFlow的比较
两个都是机器学习很好用的工具,我的感觉是sklearn在数据处理,数据展示,数据预处理真的很强很好用,比较适合像我这基础应用的使用者,目前市面上大部分的人工智能产品都可以透过sklearn来完成。tf强项应该是在深度学习,对那些准确率要求特别高的应用来说(例如人脸识别、语音识别),tf应该会比较适合。
四、导入数据
首先我们的目标是要利用房地产的一些数据来预测某一区的房价中位数,数据来源是加州的房地产数据,其中包含了经纬度、房龄、房间总数、卧室数量、人口等。首先在jupyter里面新建一个项目(右上角有个‘new’,按下去就可以创建),然后再导入数据,数据在一个housing.tgz里的housing.cvs里,属于excel的格式,可以利用下面的代码导入。
import os
import tarfile
from six.moves import urllib DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz" def fetch_housing_data(housing_url = HOUSING_URL, housing_path = HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close() fetch_housing_data()
可以在jupyter里面用head()查看前五项数据

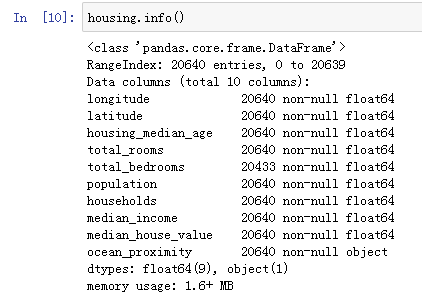
可以看到数据已经成功导入,再使用info()可以查看总数据量
五、数据清洗
上面可以看到总共有20640笔数据,数据量不大,很适合用来练习,但是可以看到第五项数据total_bedrooms的数据只有20433笔,比其他的少了207笔,这些少的数据会影响到时候的计算,需要先做处理,针对缺失数据,主要有三种修复方式:1、将缺失数据的行删了,也就是我们会牺牲207笔数据;2、将列给删了,也就是我们会少了total_bedroom这个数据;3、补上数据,通常是补上中位数或是平均数,让影响降到最低。这三种方法sklearn都有支持,这边我们选择的是用第三种方法来修补,sklearn里面可以使用imputer这个功能来实现。
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy = "median")
另外我们可以看其中一个数据项ocean_proximity,里面有下面四个值

由于他们都是文字,我们必须将他们转换成数字才可以进行计算,假如分别给他们一个数字, 这个时候会有个问题,因为文字之间是没关联的,但是一旦赋予他们一个数字,他们之间就会产生了关联,例如1H OCEAN跟NEAR OCEAN的平均不等于ISLAND, 但是1跟5的平均是3, 所以需要转换成阵列的形式,这样才可以保持这种独立性,sklearn有个很好用的指令LabelBinarizer可以直接帮我们实现这个需求,代码如下图

可以看到第一行到第三行的[0, 0, 0, 1, 0]代表了NEAR BAY。
六、特征缩放
特征缩放也是数据预处理的一环,目的是怕有些波动范围大的参数影响力会远大于那些波动小的,比如总房间数分布范围是6-39320,但收入的中位数只有0-15。处理的方法有两种,一个是线性函数归一化,就是将所有的参数范围都缩小到0-1。另外一个是标准化,就是减去平均值后除以方差。
七、创建测试集
在机器学习上,为了验证学习的结果,一般都会讲数据拆分成训练集和测试集,训练集用来训练机器,而测试集用来测试训练的结果,拆分的方法有很多种,包含了随机拆分。但是随机拆分有个问题,就拆分出来的训练数据不一定可以代表全部的数据,测试数据也一样,比如我训练数据都是一些中产或是富有的区域的数据,然后测试都是贫民区的数据,执行出来的效果当然会不好,所以需要用分层采样的方式进行数据拆分,也就是要对每种区域都均衡的采集。分层采集第一部要先决定对哪个数据进行分层,我们这边选择的是房价进行分层,因为房价是我们这次分析的重要因素下面为分层取样的代码。
from sklearn.model_selection import StratifiedShuffleSplit
housing["income_cat"] = np.ceil(housing["median_income"]/1.5)
housing["income_cat"].where(housing["income_cat"]<5,5.0, inplace=True) split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
八、数据可视化
数据可视化也是jupyter非常方便的功能之一,主要是透过matplotlib这个库来实现的。数据可视化的好处是可以让我们对整个数据集有个比较直观的了解,像是可以利用将左边打印出来可以看到整个房地产数据来源的分布位置就是加州的形状。
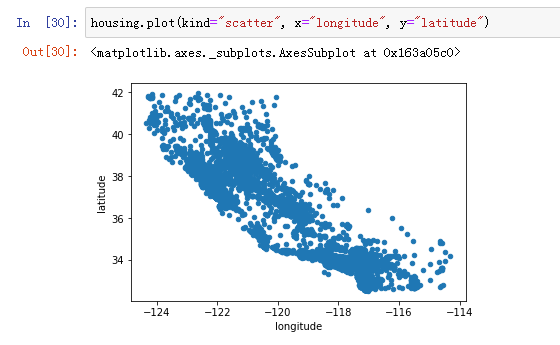
下面我们将房价的因素导入可以看到房价高的地区集中在南加和北加两个区域。

九、查找关联
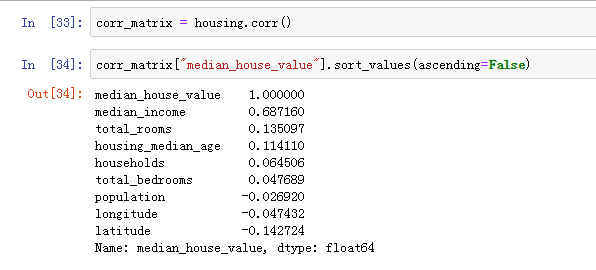
由于我们要预测房价,需要先找出一些跟房价相关的数据,sklearn提供了一个非常方便的方式corr(),可以用皮尔逊公式快速的计算各参数之间的相关性,现在我们来看看跟房价中位数相关的参数是什么,第一个就是收入,有0.68,接下来是总房间数,但是不高,只有0.135。
除了上面的数据外,我们可以透过将原本两个数据进行组合,生成第三种数据,可能原本两个关联性不高,可是新生成的数据关联性就很高。
十、训练机器
接着就是要训练机器,sklearn里面有LinearRegression()这个函数,可以自动的做回归分析,我们只需要准备两个数,一个是X轴(输入),一个是Y轴(实际结果),下面为代码
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
接着可以看看训练的结果如何,我们可以观察预测值与实际值就可以了解机器的学习成果

可以看到除了第二个,其他都还算是有点接近,毕竟训练的量小,无法要求准确度要很高,接着,我们要用比较客观的数字来代表整体的学习情况,sklearn提供了一个mean_sqaured_error的函数,是用来计算预测值与实际值的平均“距离”,以此代表误差
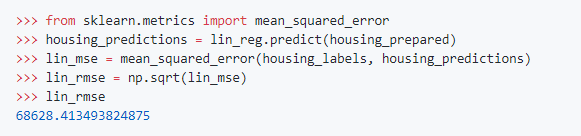
可以看到误差大约是68628,这误差算是非常大了,以下是误差产生的原因
1、数据训练量不足:对于这种多维度的回归分析,两万多笔的数据确实是很少,也是这次准确率低的主要原因
2、数据太过分散:由于数据是遍布整个加州,假如数据是集中在某个区域,比如说洛杉矶,预测出的结果相对会准一点
3、不相关特征:从相关分析中可以发现,除了平均收入外,其他的参数跟房价的相关度都过低,导致这些参数是没有帮助的
4、没有代表性数据:跟上述类似,影响房价的其中一个因素是社区环境,但是光从经纬度无法判定社区的好坏
机器学习实战笔记(一)- 使用SciKit-Learn做回归分析的更多相关文章
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-04-Logistic回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-03-朴素贝叶斯
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-00-readme
近期学习机器学习,找到一本不错的教材<机器学习实战>.特此做这份学习笔记,以供日后翻阅. 机器学习算法分为有监督学习和无监督学习.这本书前两部分介绍的是有监督学习,第三部分介绍的是无监督学 ...
- 机器学习实战笔记5(logistic回归)
1:简单概念描写叙述 如果如今有一些数据点,我们用一条直线对这些点进行拟合(改线称为最佳拟合直线),这个拟合过程就称为回归.训练分类器就是为了寻找最佳拟合參数,使用的是最优化算法. 基于sigmoid ...
- 机器学习实战笔记7(Adaboost)
1:简单概念描写叙述 Adaboost是一种弱学习算法到强学习算法,这里的弱和强学习算法,指的当然都是分类器,首先我们须要简介几个概念. 1:弱学习器:在二分情况下弱分类器的错误率会低于50%. 事实 ...
- 【机器学习实战笔记(3-2)】朴素贝叶斯法及应用的python实现
文章目录 1.朴素贝叶斯法的Python实现 1.1 准备数据:从文本中构建词向量 1.2 训练算法:从词向量计算概率 1.3 测试算法:根据现实情况修改分类器 1.4 准备数据:文档词袋模型 2.示 ...
随机推荐
- OpenStack☞HTTP协议
前言 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议.所有的WWW文件都必须遵守这个标准 HTTP是一个基于TCP/IP通信协议 ...
- day6_python之json序列化和反序列化
json作用:用来保存当前状态 1.使用json.dumps序列化把dic字典存到文件中 dic={'name':'egon','age':18} print(json.dumps(dic)) #得到 ...
- python selenium 测试 LOG
1.首先在根目录中新建一个Logs文件夹,写入文件 2.在framework文件夹中写入logger.py 3.在testsuits文件夹中写入test_log.py logger.py # _*_ ...
- selenium webdriver学习(三)------------执行js脚本
selenium webdriver学习(三)------------执行js脚本 博客分类: Selenium-webdriver 在用selenium 1.X的时候常常会用到getEval() ...
- PHP redis安装扩展
命令: 查看php版本:PHP -v 查看php安装的扩展:PHP -m php扩展开发包(包括phpize,php -config):yum install php-devel which phpi ...
- tensorflow在文本处理中的使用——CBOW词嵌入模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- H3C查看历史命令--用户以上
[H3Cwang]display history-command sys sysname H3C sysname H3Cwang display history-command q ...
- C# Abort() 多线程运行逻辑
/ Thread t ; Thread t2: t.Abort()执行后,会阻止主线程继续运行,但是不会影响t2线程的执行. static void Main(string[] args) { Con ...
- Linux 内核class_simple 接口
class_simple 接口意图是易于使用, 以至于没人会抱怨没有暴露至少一个包含设备的被 分配的号的属性. 使用这个接口只不过是一对函数调用, 没有通常的和 Linux 设备模型 关联的样板. 第 ...
- Linux 内核取消 urb
为停止一个已经提交给 USB 核心的 urb, 函数 usb_kill_urb 或者 usb_unlink_urb 应 当被调用: int usb_kill_urb(struct urb *urb); ...