使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件
本文代码已上传至git和百度网盘,链接分享在文末
网站概览

目标,使用scrapy框架抓取全部图片并分类保存到本地。
1.创建scrapy项目
scrapy startproject images
2.创建spider
cd images
scrapy genspider mn52 www.mn52.com
创建后结构目录如下

3.定义item定义爬取字段
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ImagesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
field_name = scrapy.Field()
detail_name = scrapy.Field()
这里定义三个字段,分别为图片地址,图片类别名称和图片详细类别名称
4.编写spider
# -*- coding: utf-8 -*-
import scrapy
import requests
from lxml import etree
from images.items import ImagesItem class Mn52Spider(scrapy.Spider):
name = 'mn52'
# allowed_domains = ['www.mn52.com']
# start_urls = ['http://www.mn52.com/'] def start_requests(self):
response = requests.get('https://www.mn52.com/')
result = etree.HTML(response.text)
li_lists = result.xpath('//*[@id="bs-example-navbar-collapse-2"]/div/ul/li')
for li in li_lists:
url = li.xpath('./a/@href')[0]
field_name = li.xpath('./a/text()')[0]
print('https://www.mn52.com' + url,field_name)
yield scrapy.Request('https://www.mn52.com' + url,meta={'field_name':field_name},callback=self.parse) def parse(self, response):
field_name = response.meta['field_name']
div_lists = response.xpath('/html/body/section/div/div[1]/div[2]/div')
for div_list in div_lists:
detail_urls = div_list.xpath('./div/a/@href').extract_first()
detail_name = div_list.xpath('./div/a/@title').extract_first()
yield scrapy.Request(url='https:' + detail_urls,callback=self.get_image,meta={'detail_name':detail_name,'field_name':field_name})
url_lists = response.xpath('/html/body/section/div/div[3]/div/div/nav/ul/li')
for url_list in url_lists:
next_url = url_list.xpath('./a/@href').extract_first()
if next_url:
yield scrapy.Request(url='https:' + next_url,callback=self.parse,meta=response.meta) def get_image(self,response):
field_name = response.meta['field_name']
image_urls = response.xpath('//*[@id="originalpic"]/img/@src').extract()
for image_url in image_urls:
item = ImagesItem()
item['image_url'] = 'https:' + image_url
item['field_name'] = field_name
item['detail_name'] = response.meta['detail_name']
# print(item['image_url'],item['field_name'],item['detail_name'])
yield item
逻辑思路:spider中重写start_requests获取起始路由,这里起始路由设为图片的一级分类如性感美女,清纯美女,萌宠图片等的地址,使用requests库请求mn52.com来解析获取。然后把url和一级分类名称传递给parse,在parse中解析获取图片的二级分类地址和二级分类名称,并判断是否含有下一页信息,这里使用scrapy框架自动去重原理,所以不用再写去重逻辑。获取到的数据传递给get_image,在get_image中解析出图片路由并赋值到item字段中然后yield item.
5.pipelines管道文件下载图片
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
import os
# 导入scrapy 框架里的 管道文件的里的图像 图像处理的专用管道文件
from scrapy.pipelines.images import ImagesPipeline
# 导入图片路径名称
from images.settings import IMAGES_STORE as images_store class Image_down(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['image_url']) def item_completed(self, results, item, info):
print(results)
image_url = item['image_url']
image_name = image_url.split('/')[-1]
old_name_list = [x['path'] for t, x in results if t]
# 真正的原图片的存储路径
old_name = images_store + old_name_list[0]
image_path = images_store + item['field_name'] + '/' + item['detail_name'] + '/'
# 判断图片存放的目录是否存在
if not os.path.exists(image_path):
# 根据当前页码创建对应的目录
os.makedirs(image_path)
# 新名称
new_name = image_path + image_name
# 重命名
os.rename(old_name, new_name)
return item
分析:scrapy内置的ImagesPipeline自己生成经过md5加密的图片名称,这里导入os模块来使图片下载到自定义的文件夹和名称,需要继承ImagesPipeline类。
6.settings中设置所需参数(部分)
#USER_AGENT = 'images (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36' #指定输出某一种日志信息
LOG_LEVEL = 'ERROR'
#将日志信息存储到指定文件中,不在终端输出
LOG_FILE = 'log.txt'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
IMAGES_STORE = './mn52/' ITEM_PIPELINES = {
# 'images.pipelines.ImagesPipeline': 300,
'images.pipelines.Image_down': 301,
}
说明:settings中主要定义了图片的存储路径,user_agent信息,打开下载管道。
7.创建crawl.py文件,运行爬虫
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # mn52是爬虫名
process.crawl('mn52')
process.start()
这里没有使用cmdline方法运行程序,因为涉及到后面的打包问题,使用cmdline方法无法打包。
8.至此,scrapy爬虫已编写完毕,右键运行crawl文件启动爬虫,图片就会下载。
控制台输出:
打开文件夹查看图片

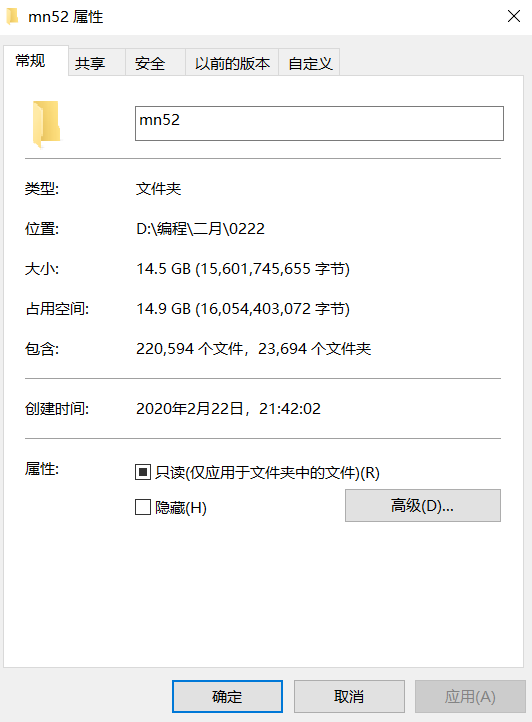
全站下载完成的话大概有22万张图片
9.打包scrapy爬虫。
scrapy爬虫作为一个框架爬虫也是可以被打包成exe文件的,是不是很神奇/
使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件的更多相关文章
- scrapy框架爬取图片并将图片保存到本地
如果基于scrapy进行图片数据的爬取 在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道 配置文件中:IMAGES_STORE = './imgsLib' 在管道文件中进行管道类的制定: f ...
- 将Python项目打包成EXE可执行文件(单文件,多文件,包含图片)
解决 将Python项目打包成EXE可执行文件(单文件,多文件,包含图片) 1.当我们写了一个Python的项目时,特别是一个GUI项目,我们特备希望它能成为一个在Windows系统可执行的EXE文件 ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- 爬虫 Scrapy框架 爬取图虫图片并下载
items.py,根据需求确定自己的数据要求 # -*- coding: utf-8 -*- # Define here the models for your scraped items # # S ...
- 正则爬取京东商品信息并打包成.exe可执行程序。
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页) 代码如下: import requests import re # 请求头 head ...
- 正则爬取京东商品信息并打包成.exe可执行程序
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页) 代码如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- Python多线程爬图&Scrapy框架爬图
一.背景 对于日常Python爬虫由于效率问题,本次测试使用多线程和Scrapy框架来实现抓取斗图啦表情.由于IO操作不使用CPU,对于IO密集(磁盘IO/网络IO/人机交互IO)型适合用多线程,对于 ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
随机推荐
- laravel 初学路由简单介绍
文档中的路由详细演示[初学laravel]对应laravel 的框架目录:routes/web.php 路由的格式一:Route::get($uri,$callback); 1.简单的浏览器输出 Ro ...
- Informatica在linux下安装搭建
安装介质清单准备 介质名称 版本信息 描述 Informatica Powercenter 9.5.1 for Linux 64 bit 必须 Java Jdk 1.6.0_45 for Linux ...
- MySQL5.7 中的query_cache_size
摘自:http://jackyrong.iteye.com/blog/2173523 1 原理 MySQL查询缓存保存查询返回的完整结果.当查询命中该缓存,会立刻返回结果,跳过了解析,优化和执行 ...
- Windows10怎么用Administrator登录?
1.首先按下快捷键win+X键, 2.然后在命令提示符中输入命令“net user administrator /active:yes”后回车 3.此时administrator管理员账户已开启,点击 ...
- node + multer存储element-ui上传的图片
说明 element-ui的Upload组件可以帮助我们上传我们的图片到我们的服务器,可以使用action参数上传图片,也可以使用http-request自定义上传方式.这里我们使用自定义的方式上传. ...
- 使用Java注解实现简单的依赖注入
代码如下: /** * 注入的注解,为空,仅起标志作用 */ @Target({ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) @int ...
- windows系统快速安装pytorch的详细教程
pip和conda的区别 之前一直使用conda和pip ,有时候经常会两者混用.但是今天才发现二者装的东西不是在一个地方的,所以发现有的东西自己装了,但是在运行环境的时候发现包老是识别不了,一直都特 ...
- ELK搭建(docker环境)
ELK是Elasticsearch.Logstash.Kibana的简称,这三者是核心套件,但并非全部. Elasticsearch是实时全文搜索和分析引擎,提供搜集.分析.存储数据三大功能:是一套开 ...
- 13.深度学习(词嵌入)与自然语言处理--HanLP实现
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 13. 深度学习与自然语言处理 13.1 传统方法的局限 前面已经讲过了隐马尔可夫 ...
- Jmeter之安装与环境配置
前言 本次的教程是Jmeter的安装与配置 1.安装JDK并配置好环境变量,在系统变量中添加JAVA_HOME变量 在系统变量path中添加 %JAVA_HOME%\bin 2.打开Jmeter官网: ...