正则爬取京东商品信息并打包成.exe可执行程序
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页)
代码如下;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import requestsimport re# 请求头headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}def get_all(url,key): for page in range(1,200,2): params = { 'keyword':key, 'enc':'utf-8', 'page':page } num = int((int(page)+1)/2) try: response = requests.get(url=url,params=params,headers=headers) # 转码 content = response.text.encode(response.encoding).decode(response.apparent_encoding) data_all = re.findall('<div class="p-price">.*?<i>(.*?)</i>.*?<div class="p-name p-name-type-2">.*?title="(.*?)"' '.*?<div class="p-shop".*?title="(.*?)"',content,re.S) for i in data_all: with open(key + '.txt', 'a+', encoding='utf-8') as f: f.write('店铺名称:' + i[2]+'\n'+'商品名称:'+i[1]+'\n'+'价格:'+i[0]+'\n\n') print('第'+str(num)+'页'+'数据下载中....') except Exception as e: print(e)if __name__ == '__main__': print('输入要搜索的内容,获取京东商城里面的商品名称,店铺名称,商品价格') key = input('输入搜索内容:') get_all(url,key) |
打包成.exe可执行文件。
需要用到pyinstaller包pip下载;
pip install pyinstaller
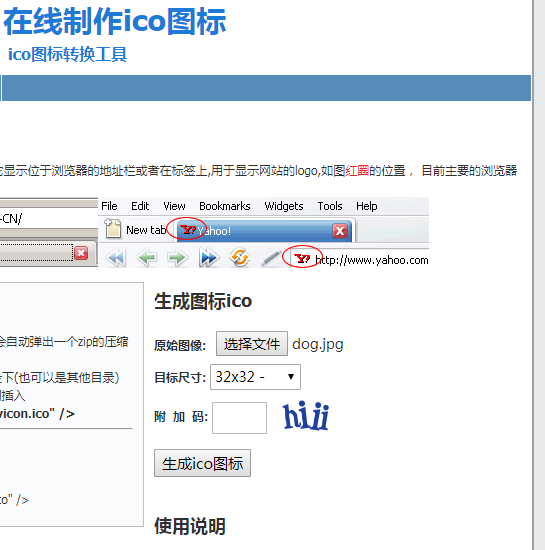
在线制作一个.ico图标,用来当程序图片,把图标和程序放在同一个文件夹下,
在.py文件目录下打开命令行窗口,执行打包命令;
E:\练习\最后阶段\0808\jd1>pyinstaller -F -i dog.ico jd.py
出现successfully表示打包成功;
27525 INFO: Building EXE from EXE-00.toc completed successfully.
可执行程序在当前文件夹下的dist文件夹下;
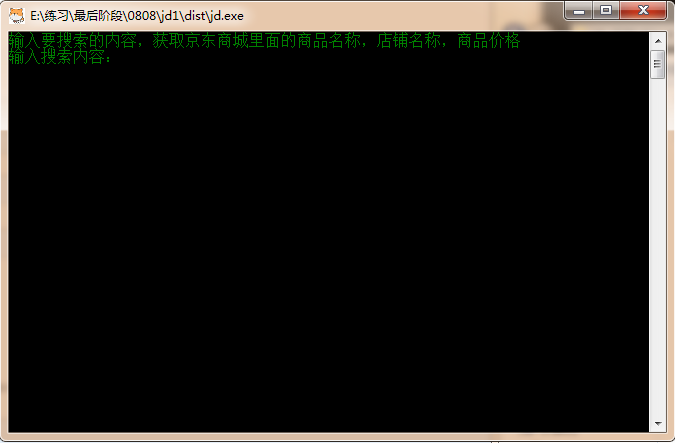
运行效果;
可同时执行多个程序;
输出结果;
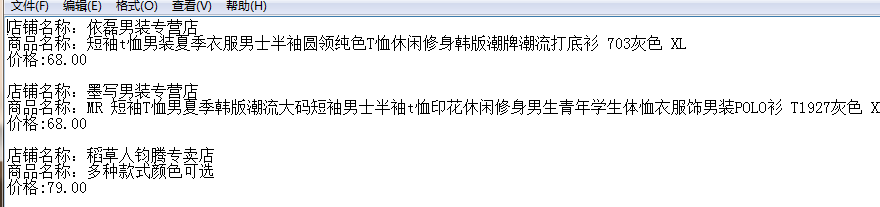
done。
正则爬取京东商品信息并打包成.exe可执行程序的更多相关文章
- 正则爬取京东商品信息并打包成.exe可执行程序。
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页) 代码如下: import requests import re # 请求头 head ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- Python爬虫-爬取京东商品信息-按给定关键词
目的:按给定关键词爬取京东商品信息,并保存至mongodb. 字段:title.url.store.store_url.item_id.price.comments_count.comments 工具 ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 八个commit让你学会爬取京东商品信息
我发现现在不用标题党的套路还真不好吸引人,最近在做相关的事情,从而稍微总结出了一些文字.我一贯的想法吧,虽然才疏学浅,但是还是希望能帮助需要的人.博客园实在不适合这种章回体的文章.这里,我贴出正文的前 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- 爬虫之selenium爬取京东商品信息
import json import time from selenium import webdriver """ 发送请求 1.1生成driver对象 2.1窗口最大 ...
- Java爬虫爬取京东商品信息
以下内容转载于<https://www.cnblogs.com/zhuangbiing/p/9194994.html>,在此仅供学习借鉴只用. Maven地址 <dependency ...
随机推荐
- python常用语句
流程控制if...else.... name = '疯子' res = input('你叫什么名字?') if res == name: print('帅哥') else: print('丑男') 如 ...
- 爬虫4之pyquery
pyquery 初始化 字符串初始化 from pyquery import PyQuery as pq doc = pq(html)#html为需要处理的内容 #方法与CSS选择器相同 print( ...
- 运维日常之机房浪潮服务器硬盘红灯亮起,服务器一直响,raid磁盘红色。。。故障解决方法
按Ctrl+H进入到WebBIOS内,看见的错误如下所示: 错误是PDMissing,只不过维护的IBM服务器错误的磁盘不是第一块,而是第三块而已,不过坏哪块硬盘没有影响,重要的是错误的原因.这种错误 ...
- springBoot2.0使用@ImportResource引入spring配置文件.xml
1. 编写spring配置文件.xml 这里是bean.xml <?xml version="1.0" encoding="UTF-8"?> < ...
- QQ音乐爬虫
#今日目标 **QQ音乐爬虫** 今天要爬取的是QQ音乐任意歌手的所有音乐歌词,因为笔者是周杰伦的忠实粉丝,所以专门写了个爬虫来爬取他的音乐的歌词,因为他的音乐在咪咕音乐可以听,所以便没有去爬取. 好 ...
- VS Code Python 全新发布!Jupyter Notebook 原生支持终于来了!
VS Code Python 全新发布!Jupyter Notebook 原生支持终于来了! 北京时间 2019 年 10 月 9 日,微软发布了全新的 VS Code Python 插件,带来了众多 ...
- selenium2环境搭建----基于python语言
selenium支持多种语言如java.c#.Python.PHP等,这里基于python语言,所以这里搭建环境时需做俩步操作: ----1.Python环境的搭建 ----2.selenium的安装 ...
- Kibana多用户创建及角色权限控制
1 介绍 ELK日志管理属于基础设施平台,接入多个应用系统是正常现象,如果接入多个系统的索引文件没有进行权限划分,那么很大程度会出现索引文件误处理现象,为了避免这种情况发生,多用户及权限设置必不可少. ...
- import cycle not allowed in test
写个 sdk 的测试时报错 import cycle not allowed in test 后发现因为测试文件内多写了导入同包路径. 同 package 下的 xxx_test.go 内不需要额外 ...
- for XML path 使用技巧
FOR XML PATH 是sqlserver数据库的语法,能将查询出的数据转换成xml格式的数据. 首先,我们来看一个正常的查询: SELECT TOP 2 id, name,crDate FROM ...